R语言模拟:Bias Variance Trade-Off

作者:量化小白一枚,上财研究生在读,偏向数据分析与量化投资
个人公众号:量化小白上分记
本文主要是对机器学习算法误差的分解,全文包括理论推导和模拟两部分。
1. 理论推导
如何评价机器学习算法的性能,是一个非常重要的问题,目前已有很多方法,基本思路都是用样本误差去估计泛化误差,简单的有将样本分为测试集和训练集两部分,复杂的包括交叉验证和Boostrap等方法,这其中一个很重要的思想是,避免测试样本在训练样本中出现,否则得到的会是一个偏向乐观的结果。
本文不过多论述这方面的内容,而是阐述另一个话题,误差的来源和分解,通过偏差-方差分解的办法。
这里我们使用西瓜书中的符号说明,

学习算法的期望预测可以表示为
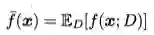
学习算法总误差(期望泛化误差)用均方误差衡量时可以表示为
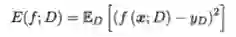
所谓偏差,是指真实值与预测值之间的差别,它刻画的是算法本身的拟合能力,用均方误差衡量如下

所谓方差,是指用不同的训练集进行训练,对同一测试集进行测试时,得到结果中误差序列的方差,这些训练集都来自同一个分布,即整体,它刻画的是数据扰动对于结果的影响
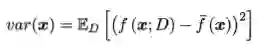
此外,模型还存在一定的噪声,可以表示为
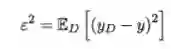
通过简单推导可以得出如下结论
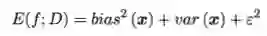
也就是泛化误差可以分解为偏差、方差和噪声的和。
一般来说,方差和偏差是有冲突的,他们之间存在trade-off,无法减小方差的同时减小偏差,他们的关系可以表示为下图

这其中,训练程度是可以通过调参,增加特征进行控制的。 训练程度不足时,模型的拟合程度不够,偏差较大,训练数据的变化不会导致结果出现显著的变化,这时偏差主导了泛化误差率,随着训练程度加深,模型拟合程度加大,偏差逐渐减小,但此时对于数据的依赖性变强,数据的任一微小变动都可能导致结果发生巨大变化,可能出现过拟合现象。此时,方差主导的泛化误差率。
2. 模拟
首先说明,模拟部分使用的软件是R语言,不是PYTHON
实证部分我们尝试复制上面图中的偏差、方差关系示意图,案例来自ESL,先放上书中的标准图,毕竟这个看上去比较完美,我复制出来的结果没有这个好。
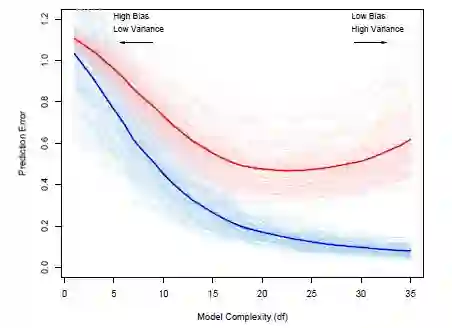
首先解释下这个图,图中浅红色线为用来自同一分布的不同训练集训练的模型对同一测试集预测结果的误差,浅蓝色线为对用于训练的训练集预测结果的误差,浅红色线和浅蓝色线分别是100条,即有100个训练集。深红色和深蓝色线为浅色线的平均,用均值作为期望的估计量。
横轴表示的是训练程度,这里实际上是自变量的个数,数据中与因变量相关的自变量共有35个,每次训练分别使用1到35个变量进行训练,得到不同自变量数下的误差,就可以得到一条误差曲线。
可以看出,(测试集)红色线存在明显的Bias Variance Trade-Off,训练集(蓝色线)随着自变量个数增加,误差不断减小,最后实际上出现过了拟合,也就是之前说到的乐观结果。
再说下数据的生成
训练集:100个训练集,每个训练集中设置50个样本,每个样本有35个自变量,自变量均来自标准正态分布,因变量取值为:如果所有自变量加起来大于0,就是1,不大于0,就是0
测试集:1个测试集,50个样本,规则与训练集相同,代码如下
1set.seed(1)
2test_size <- 50
3sigma <- 0.5
4test_x <- matrix(rnorm(test_size*35,0,1),test_size)
5test_y <- ifelse(apply(test_x,1,sum)>0 , 1 , 0)
训练用的模型是Lasso,这个没什么需要说明的,R语言的glmnet包可以直接做。
1pnum <- 35
2train_error_all <- matrix(NaN,100,pnum)
3test_error_all <- matrix(0,100,pnum)
4for( i in (1:100)){
5
6 flag = 1
7 while (flag == 1){
8 train_x <- matrix(rnorm(50*35,0,1),nrow = 50)
9 train_y <- ifelse(apply(train_x,1,sum)>0 , 1 , 0)
10
11 lasso <- glmnet(train_x,train_y,alpha = 1, nlambda = 10000, family = 'gaussian',pmax = pnum)
12 lambdas <- data.frame(df = lasso$df,lambda = lasso$lambda)
13 ld <- aggregate(lambdas,by = list(lambdas$df),mean)
14
15 ld <- ld[-1,]
16 if(dim(ld)[1] == pnum){
17 flag = 0
18 }
19 }
20
21
22
23 lasso1 <- glmnet(train_x,train_y,alpha = 1, lambda = ld$lambda, family = 'gaussian')
24 result_train <- predict(lasso1, newx = train_x,type = 'response',s = ld$lambda)
25 result_test <- predict(lasso1, newx = test_x,type = 'response',s = ld$lambda)
26
27
28 train_error <- apply(abs(result_train - train_y),2,mean)
29 test_error <- apply(abs(result_test - test_y),2,mean)
30
31
32 train_error_all[i,ld$df] <- train_error
33 test_error_all[i,ld$df] <- test_error
34
35print(i)
36}
37
38
39train_error_mean <- apply(train_error_all,2,mean)
40test_error_mean <- apply(test_error_all,2,mean)
算出来之后作图,最终效果图如下
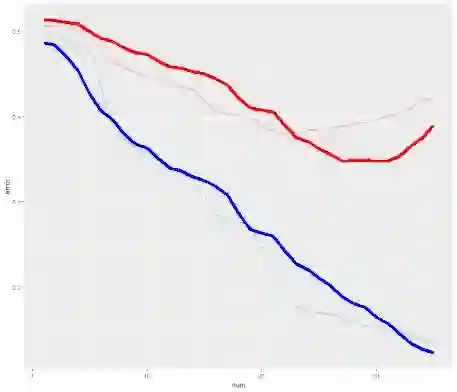
动图是用animation、ggplot包做的,也是折腾了很久,感觉以后有时间可以专门写篇文章怎么用r语言做动图了。
1g1 <- ggplot()
2saveGIF({
3 for (i in 1:100){
4 print(i)
5 train_data <- data.frame(train_error_all[i,])
6 train_data$num <- 1:35
7 names(train_data) <- c('error','num')
8 train_data$type <- 'train_error'
9
10
11 test_data <- data.frame(test_error_all[i,])
12 test_data$num <- 1:35
13 names(test_data) <- c('error','num')
14 test_data$type <- 'test_error'
15
16 train_all <- data.frame(train_error)
17 train_all$num <- 1:35
18 names(train_all) <- c('error','num')
19 train_all$type <- 'average(train_error)'
20
21 test_all <- data.frame(test_error)
22 test_all$num <- 1:35
23 names(test_all) <- c('error','num')
24 test_all$type <- 'average(test_error)'
25
26
27
28 g1 <- g1 + geom_line(data = train_data,aes(x=num,y=error),lwd = 1,colour = 'lightblue') +
29 geom_line(data = test_data,aes(x=num,y=error),lwd = 1,colour = 'lightpink') +
30 geom_line(data = train_all,aes(x=num,y=error),lwd = 2,colour = 'blue') +
31 geom_line(data = test_all,aes(x=num,y=error),lwd = 2,colour = 'red')
32
33 print(g1)
34 }
35},movie.name='Bias-Variance-Trade-Off.gif',interval=0.5,ani.width=700,ani.height=600)
再来一个静态版的,这个就简单多了

1for (i in 1:100){
2 plot(1:pnum,train_error_all[i,],xlab = '',ylab = '',xlim = c(0,pnum),ylim = c(0,0.6),
3 type = 'l',col = 'lightblue')
4 par(new = T)
5 plot(1:pnum,test_error_all[i,],xlab = '',ylab = '',xlim = c(0,pnum),ylim = c(0,0.6),
6 type = 'l',col = 'lightpink')
7
8 par(new = T)
9}
10
11plot(ld$df,train_error,xlab = '',ylab = '',xlim = c(0,pnum),ylim = c(0,0.6),type = 'l',col = 'blue',lwd = 2)
12par(new = T)
13plot(ld$df,test_error,xlab = 'Model Complexity (df)',ylab = 'Prediction Error',xlim = c(0,pnum),ylim = c(0,0.6),
14 type = 'l',col = 'red',lwd = 2)
15box()
整体来看,跟书上的趋势是差不多的,但还是有一些细微的差别,比如书上图最左侧y轴在1,我做的在0.5,因为ESL里没有具体说明因变量是怎么定义的,我是按照后面一个例子的方式定义的,所以有差别,但不影响理解。
最后需要说明两点:
1. 虽然之前提到了方差-偏差分解,但模拟过程中其实并没有用到,计算的是总的误差,只是为了分析方便,下一篇会通过方差偏差分解来更细致分析误差。
2.之前提到的方差-偏差分解并不一定成立,只有在用均方误差度量模型误差时才成立,如果使用0-1误差等其他方法,就不再成立。
参考文献
1. Ruppert D. The Elements of Statistical Learning: Data Mining, Inference, and Prediction[J]. Journal of the Royal Statistical Society, 2010, 99(466):567-567.
2. 周志华. 机器学习 : = Machine learning[M]. 清华大学出版社, 2016.


公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法




