用 LDA 和 LSA 两种方法来降维和做 Topic 建模

本文为 AI 研习社编译的技术博客,原标题 2 latent methods for dimension reduction and topic modeling,作者为 Edward Ma。
翻译 | dudubear、机智的工人 校对 | 余杭 审核 | 余杭

图片链接: https://pixabay.com/en/golden-gate-bridge-women-back-1030999/
在优秀的词嵌入方法出现之前,潜在语义分析模型(LSA)和文档主题生成模型(LDA)都是解决自然语言问题的好方法。LSA模型和LDA模型有相同矩阵形式的词袋表示输入。不过,LSA模型专注于降维,而LDA模型专注于解决主题建模问题。
由于有很多资料介绍这两个模型的数学细节,本篇文章就不深入介绍了。如果感兴趣,请自行阅读参考资料。为了让大家更好地理解,我不会做去停用词这样的预处理操作。但这是在使用LSA、LSI和LDA模型时非常关键的部分。阅读以下文章,你会了解以下内容:
潜在语义分析模型(LSA)
文档主题生成模型(LDA)
主旨概要
潜在语义分析(LSA)
2005年Jerome Bellegarda将LSA模型引入自然语言处理任务。LSA模型的目的是对分类任务降维。其主要思想是具有相似语义的词会出现在相似的文本片段中。在自然语言处理领域,我们经常用潜在语义索引(LSI)作为其别名。
首先,我们用m个文档和n个词作为模型的输入。这样我们就能构建一个以文档为行、以词为列的m*n矩阵。我们可以使用计数或TF-IDF得分。然而,用TF-IDF得分比计数更好,因为大部分情况下高频并不意味着更好的分类。

图片来源: http://mropengate.blogspot.com/2016/04/tf-idf-in-r-language.html
TF-IDF的主要思想是高频的词有可能不代表着很多的信息。换句话说,就是出现频率小的词在模型中有更高的权重。字词的重要性与它在同一文件中出现的次数成正比,但同时与其在语料库中出现的次数成反比。更详细的内容,请参考此博客(https://towardsdatascience.com/3-basic-approaches-in-bag-of-words-which-are-better-than-word-embeddings-c2cbc7398016)。
该模型的挑战是矩阵很稀疏(或维数很高),同时有噪声(包括许多高频词)。因此,使用分解 SVD 来降维。
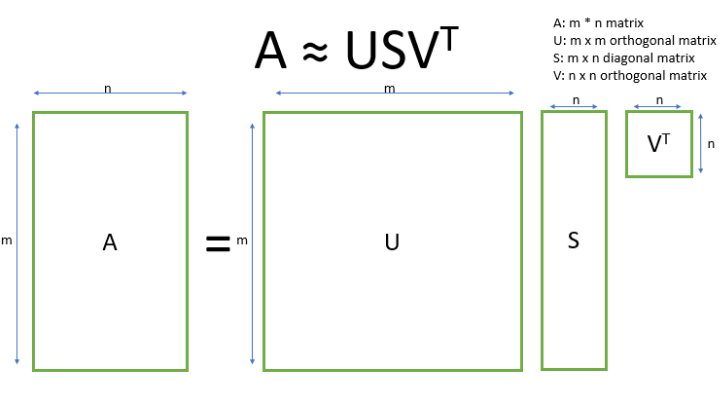
SVD 的思想在于找到最有价值的信息并使用低维的t来表达这一信息。

输出

可以看到维度从 130 K 降到了 50。

输出

文档主题生成模型(LDA)
2003年,David Blei, Andrew Ng和Michael O. Jordan提出了LDA模型。这属于无监督学习,而主题模型是其个中典型。它建立的假设在于每份文档都使用多个主题混合生成,同样每个主题也是由多个单词混合生成。
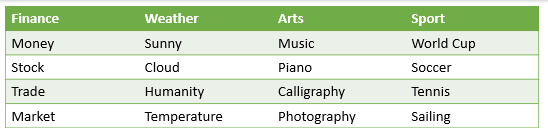
不同话题下的不同词汇
显然,你可以想象出两层聚合。第一层是类别的分布。打个比方,类似我们有金融新闻、天气新闻和政治新闻。第二层则是类中的单词分布。比如,我们可以在天气新闻中找到类似“晴朗的”和“云”这样的单词,在金融新闻中找到“钱”和“股票”这样的单词。
然而,"a","with","can"这样的单词对主题建模问题没有帮助。这样的单词存在于各个文档,并且在类别之间概率大致相同。因此,想要得到更好的效果,消除停用词是关键一步。
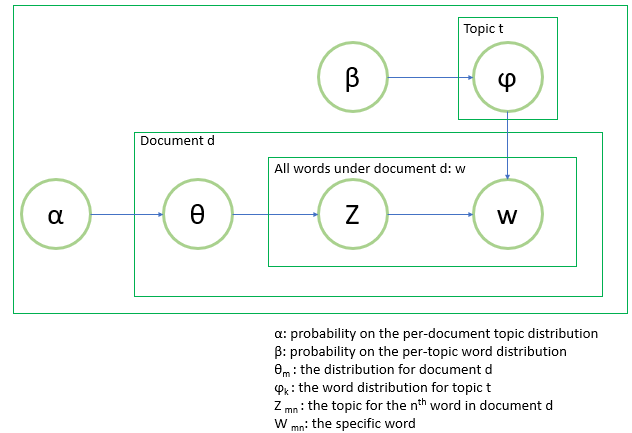
对特定的文档d,我们得到了其主题分布θ。则主题t可以根据这个分布(θ)从ϕ中选出相应的单词。

输出:

主旨概要
要获取完整代码,请访问我的github仓库(https://github.com/makcedward/nlp/blob/master/sample/nlp-lsa_lda.ipynb)。
两个模型均使用词袋表示作为输入矩阵
SVD的挑战是我们很难判定最优的维数。总的来说,低维所消耗的资源更少,但有可能无法区分相反意义的词。而高维能解决该问题,但会消耗更多地资源
关于我
我是工作在湾区的一名数据科学家。我的主要研究方向是数据科学和人工智能,尤其是自然语言处理和平台相关的。你可以通过Medium、LindeIn或Github了解我。
参考
SVD教程:https://cs.fit.edu/~dmitra/SciComp/Resources/singular-value-decomposition-fast-track-tutorial.pdf
CHHK LSI教程:http://www1.se.cuhk.edu.hk/~seem5680/lecture/LSI-Eg.pdf
Stanford LSI教程:https://nlp.stanford.edu/IR-book/pdf/18lsi.pdf
LSA和LDA介绍:https://cs.stanford.edu/~ppasupat/a9online/1140.html
原文链接:
https://towardsdatascience.com/2-latent-methods-for-dimension-reduction-and-topic-modeling-20ff6d7d547
点击文末【阅读原文】即可观看更多精彩内容:
NLP 教程:词性标注、依存分析和命名实体识别解析与应用
想研究 NLP,不了解词嵌入与句嵌入怎么行?
手把手教你从零起步构建自己的快速语义搜索模型
文本分类又来了,用 Scikit-Learn 解决多类文本分类问题
CS224n斯坦福自然语言处理课程(中英双语字幕)
等你来译:
利用词向量和tsne算法来学习tensorflow
LDA 和 LSA 来做Topic建模
微软的TextWorld框架,NLP界的强化学习框架
深度学习的NLP工具






