Python中的端对端主题建模: 隐含狄利克雷分布(LDA)

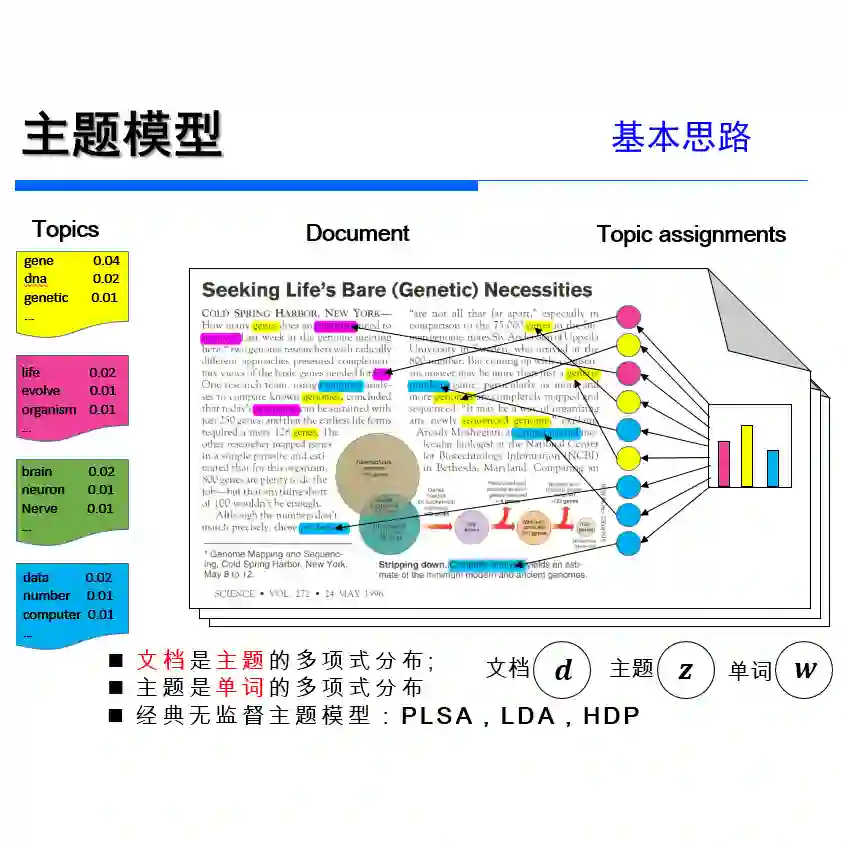
主题模型: 简而言之,它是一种统计模型,用于标记出现在文档集合中的抽象“主题”,这些主题最能代表这个文档集合中的信息。
获取主题模型使用了许多技术。本文旨在演示LDA的实现:一种广泛使用的主题建模技术。
隐含狄利克雷分布(LDA)
根据定义,LDA是给定语料库的生成概率模型。其基本思想是将文档表示为潜在主题的随机混合,并对每个主题通过单词分布进行特征化。
LDA的底层算法
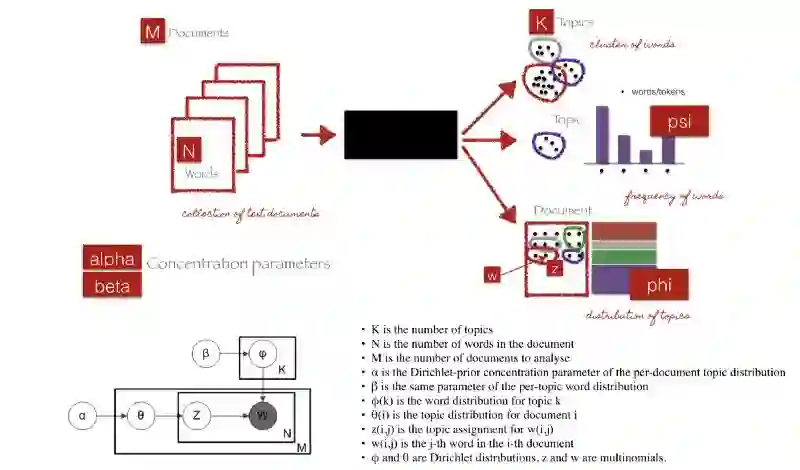
http://chdoig.github.io/pytexas2015-topic-modeling/#/3/4
给定M个文档、N个单词和估计的K个主题, LDA使用这些信息输出(1)K个主题,(2)psi,表示每个主题K的单词分布,(3)phi,表示文档 i 的主题分布。
α参数是Dirichlet先验浓度参数,表示文档-主题密度,α值越高,就可以假定文档由更多的主题组成,从而导致每个文档的主题分布更加具体。
β参数与先验浓度参数相同,表示主题词密度的,β值越高,就可以假定主题由大部分单词组成,从而导致每个主题的单词分布更加具体。
LDA 的实现
完整的代码可以在GitHub上以Jupyter Notebook的形式获得。(https://github.com/kapadias/ml-directory/blob/master/medium_posts/Introduction%20to%20Topic%20Modeling.ipynb )
加载数据
数据清洗
探索性分析
为LDA分析准备数据
LDA模型训练
分析LDA模型结果
加载数据

NIPS(神经信息处理系统)标识
在本教程中,我们将使用NIPS大会上发表的论文数据集。NIPS大会(神经信息处理系统)是机器学习领域最负盛名的年度事件之一。在每次的NIPS大会上,参会者都会发表大量的研究论文。此CSV文件包含了从1987年到2016年(29年!)发表的不同的NIPS论文的信息。这些论文讨论了机器学习领域的各种各样的主题,从神经网络到优化方法等等。
首先,我们将研究CSV文件,以确定我们可以使用什么类型的数据进行分析,以及它的结构是怎样的。一篇研究论文通常由标题、摘要和正文组成。
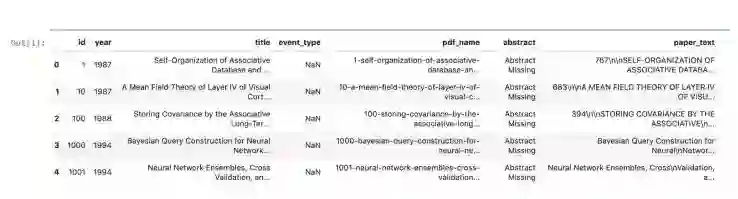
原始数据示例
数据清洗
去掉多余列
对于论文的分析,我们只对与论文相关的文本数据以及论文发表年份感兴趣。由于该文件包含一些元数据,如id和文件名,因此删除所有不包含有用文本信息的列是很有必要的。

删除标点符号/转换为小写
现在,我们将对论文文本内容执行一些简单的预处理,以便它们更易于分析。我们将使用一个正则表达式来删除标题中的任何标点符号。然后我们将执行小写字母转换。


探索性分析
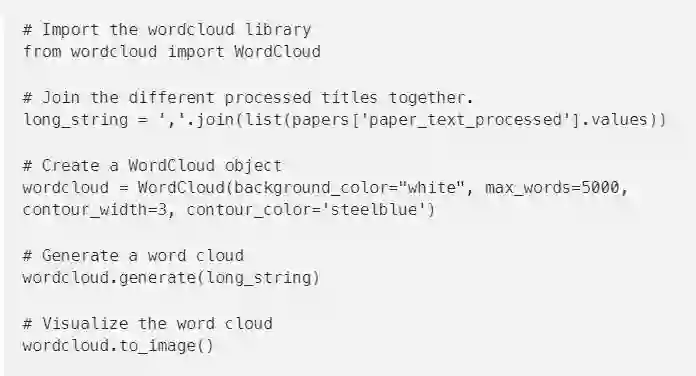
为了验证预处理是否正确执行,我们可以对研究论文的文本创建一个词云。这将给我们一个最常见单词的可视化表示。可视化是理解我们是否仍然在正确的轨道上的关键!此外,它还允许我们在进一步分析文本数据之前验证是否需要对文本数据进行额外的预处理。
Python有大量的开放库!我们将使用Andreas Mueller的wordcloud库,而不是自己开发一种方法来创建词云:

为LDA分析准备文本
LDA不直接处理文本数据。首先,需要将文档转换为简单的向量表示形式。然后,LDA将使用这个表示来确定主题。“文档向量”的每个条目都对应于一个单词在文档中出现的次数(词袋模型,即BOW表示)。
接下来,我们将把标题列表转换为向量列表,所有向量的长度都等于对应的词汇。
然后,我们将根据这个操作的结果(文档向量列表)来标出最常见的10个单词。作为检查,这些单词也应该出现在词云中。

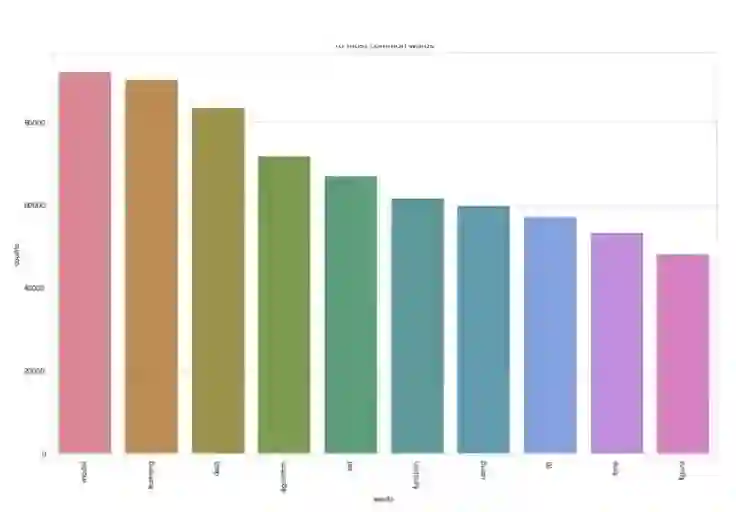
前10个最相同的词
LDA 模型训练和结果可视化
我们唯一要调整的参数是LDA算法中的主题数量。通常,人们会计算“perplexity(困惑度)”指标来确定多少数量的主题是最好的,然后迭代不同数量的主题,直到找到最低的“perplexity”。在下一篇文章中,我们将介绍模型评估和调优概念,并探讨广泛使用的自然语言处理工具包Gensim。


通过LDA找到的最终主题
分析 LDA 模型结果
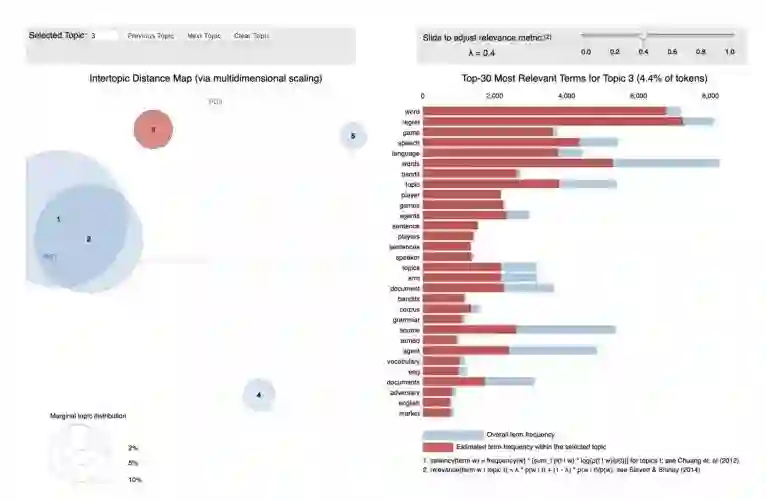
pyLDAvis包的目的是帮助用户在主题模型中解释适合于文本数据集的主题。pyLDAvis开发的交互式可视化工具对以下两方面都很有帮助:
更好地理解和解释个别主题
更好地理解主题之间的关系。
对于(1),通过使用不同的λ参数,你可以手动选择每个主题以查看其最频繁的和/或“相关的”词语。当你试图为每个主题指定一个人可解释的名称或“含义”时,这将有所帮助。
对于(2),探索主题间距图(Intertopic Distance Plot )可以帮助你了解主题之间的关系,包括主题组之间潜在的高级结构。

在过去的十年里,机器学习已经变得越来越流行,最近在计算可用性方面的进步已经导致研究该领域的人数的指数级增长,人们正在寻找如何将新方法结合起来,从而推动自然语言处理领域的发展。通常,我们将主题模型视为黑箱算法,但我希望这篇文章能够阐明它背后的数学原理、直觉和高级代码,并帮助你开始处理任何文本数据。
如上所述,在下一篇文章中,我们将更深入地了解如何评估主题模型的性能,优化超参数,使其能够部署到生产环境中。
参考资料:
[1] 主题模型— 维基百科。 https://en.wikipedia.org/wiki/Topic_model
[2] 用于主题建模的分布式策略。 https://www.ideals.illinois.edu/bitstream/handle/2142/46405/ParallelTopicModels.pdf?sequence=2&isAllowed=y
[3] 主题映射 — 软件 — 资源— Amaral Lab.。https://amaral.northwestern.edu/resources/software/topic-mapping
如果你有任何反馈,请对本文进行评论,也可以在LinkedIn(https://www.linkedin.com/in/shashankkapadia/ )上给我发信息,或者给我发邮件(shmkapadia[at]gmail.com)。
英文原文:https://qiniumedia.freelycode.com/vcdn/1/%E4%BC%98%E8%B4%A8%E6%96%87%E7%AB%A0%E9%95%BF%E5%9B%BE3/end-to-end-topic-modeling-in-python-latent-dirichlet-allocation-lda.pdf
译者:野生大熊猫