【泡泡图灵智库】移动操作平台上的统一卷积神经网络场景识别和对象检测
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Scene Recognition and Object Detection in A Unified Convolutional Neural Network on A Mobile Manipulator
作者:Hao Sun, Zehui Meng, Pey Yuen Tao, et al.
来源:ICRA 2018
编译:黄文超
审核:杨小育
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是:移动操作平台上的统一卷积神经网络场景识别和对象检测。
环境理解,对象检测和识别对于在现实世界中运行的机器人来说是非常关键的技能。在本文中,作者提出了一个多任务卷积神经网络:在一个统一的网络结构中进行对象检测和场景分类。所提出的网络能够全面地了解图像以理解场景,假设对象位置,并利用区域对象特征对全局场景特征进行编码以改善对象识别。作者在SUN RGBD数据集上评估了该网络。实验表明,本文提出的方法优于现有最高水平。网络的预测输出进一步转化为连续的机器人置信度,以确保时间一致性,并扩展到3D空间的机器人应用。作者将整个框架嵌入到了ROS中,并在真实的机器人上评估其语义建图和抓取检测的性能。
主要贡献
1、提出了一个多任务的CNN框架,可并行执行场景理解和对象检测,其中场景特征可用于改善对象检测;
2、设计了一个置信度更新系统,以确保网络预测输出的时间一致性,并将2D检测结果扩展到3D空间;
3、整个系统在ROS中实现,并在真实世界中对算法进行了评估。
算法流程
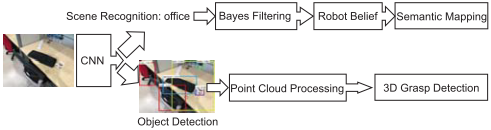
图1 系统简要架构
本系统主要有三个关键部分:一个用于场景理解和对象检测的多任务CNN;一个用于语义建图的置信度更新系统;一个将2D检测结果扩展到3D空间用于抓取的点云处理流程。
网络结构
网络结构的设计是受Faster RCNN二分支网络的启发。本文中的网络又可以进一步分为三个部分:场景理解网络,Scene
Recognition Network (SRN);区域提议网络Region Proposal Network (RPN);对象识别网络Object Recognition Network (ORN)。这三个网络共享卷积计算
SRN基于VGGNet,网络接受一张图像的输入,输出为固定维度的特征图(7x7x512),称为输入图像的场景特征图。RPN用于对象提议的生成,与Faster RCNN中相同。为了共享卷积计算,ORN的结构与RPN和SRN相同,但是融合了二者的特征,其在通道维度串接RPN和SRN的输出,成为7x7x1024的特征图,随后使用全连接层来进行对象识别和包围框回归。ORN的更多细节可参见下图。
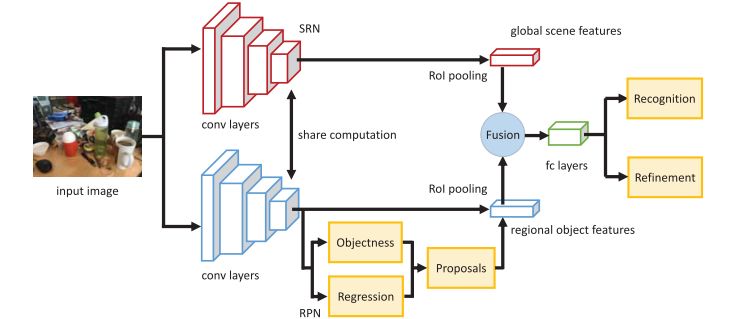
图3 ORN的基本工作流程
置信度更新系统和语义建图
卷积神经网络的预测有可能变化的很快,因为它仅依靠输入图片进行预测。但是对于机器人来说,场景是连续且根据物理约束逐渐更新的。因此作者设计了一个基于贝叶斯滤波的置信度更新系统以确保时间一致性,算法如式(1)所示。
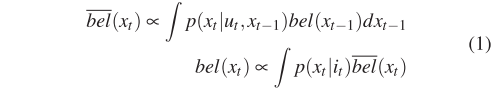
其中bel(x)为机器人的场景置信度,u为里程计数据,i为输入图像,p(x_t | i_t)表示当前图像的场景预测,p(x_t | u_t, x_t−1)是预定义的参数,用于描述置信度如何随着机器人的里程计变化,作者将该参数设为:机器人运动时为1/19 ,静止时为1。
传统的机器人导航使用SLAM算法来建图,接受LiDAR输入并建立一个占用栅格地图。尽管这足以满足基本的导航任务,但是智能机器人需要对环境有更高层次的理解。由于本文的网络能够识别场景,作者提出了一个语义建图方法,接受2D LiDAR和相机图像输入,将空间划分为具体的语义概念如办公室,起居室和走廊等,在建图过程中传统的占用栅格地图和语义地图同时构建。
用于3D检测的点云处理
2D的检测结果不足以满足真实物理世界中的机器人应用。作者提出一个算法,接受网络的预测输出、Kinect V2的RGB图像和点云来检测对象的基本几何信息。算法如下所示:

主要结果
作者在SUN RGBD数据集中的19个对象类别的检测任务和19个场景类别的场景识别任务评估的提出的网络。
表1 对象检测评估
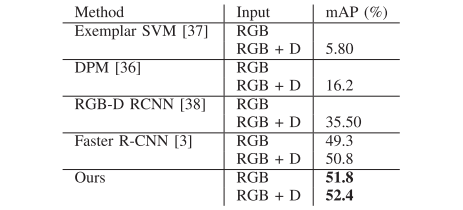
表2 场景识别评估

作者在真实室内环境建立语义地图,如下图所示,占用栅格地图中的空间由其对应的场景类别标注,例如走廊标记为绿色,起居室和办公室分别标记为粉红色和暗绿色。


Abstract
Environment understanding, object detection and recognition are crucial skills for robots operating in the real world. In this paper, we propose a Convolutional Neural Network with multi-task objectives: object detection and scene classification in one unified architecture. The proposed network reasons globally about an image to understand the scene, hypothesize object locations, and encodes global scene features with regional object features to improve object recognition. We evaluate our network on the standard SUN RGBD dataset. Experiments show that our approach outperforms state-of-the-arts. Network predictions are further transformed into continuous robot beliefs to ensure temporal coherence and extended to 3D space for robotics applications. We embed the whole framework in Robot Operating System, and evaluate its performance on a real robot for semantic mapping and grasp detection.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


