赛尔原创 | 基于句法结构与语义信息核函数的搭配关系抽取
作者: 哈工大SCIR 李盛秋,赵妍妍,秦兵
在自然语言处理领域中,文本情感分析工作包含了几个重要的任务:文本的情感极性分类(如篇章级或句子级情感分类)、主观客观性识别、细粒度情感分析等。文本情感极性分类是情感分析的基础任务,即判断出一段文本所表达出的情感极性[1][2];主观客观性识别即为确定文本情感的主体是否为文本的讲述者[3];而细粒度的情感分析不仅要找出文本所表达出的情感,而且要确定情感的对象,例如某段评论表达出了对某一部手机的不满、或是对某一部相机的喜爱。目前在社交媒体、网上商城等地方的产品评论数量十分庞大,如果能够让计算机自动地来对这些大量的评论进行精炼和分析,智能地完成对产品评论中用户的评价对象进行提取,将有利于消费者对产品的选择,同时对生产厂家收集对产品的建议也有很大帮助。
细粒度情感分析的主要步骤为:抽取出评价对象和评价词的候选、确定评价对象和评价词之间的搭配关系、对评价对象和评价词进行情感分类。本文主要讨论第二步,如何确定一句话中的两个词语之间是一种“情感搭配”的关系,比如在“这部手机的屏幕很不错,但是相机不好”一句中,“屏幕”和“不错”以及“相机”和“不好”都是正确的搭配关系。
引言
情感搭配的抽取可以看作是一种关系分类任务。已有相关研究证明,句法结构在关系分类任务中是一种非常重要的特征[4]。在自然语言处理领域,句法分析是一项基础的工作,句法分析的结果为其他NLP应用提供了关于句子本身的大量信息。例如,使用语言技术平台(Language Technology Platform, LTP)对“这个相机的镜头看起来很不错”一句进行句法分析,得到的依存句法结构如下所示:
图1 句子的依存句法结构
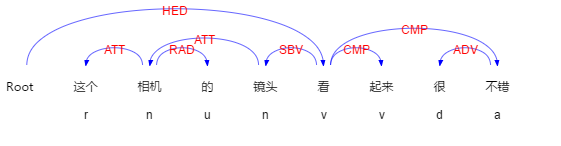
但是,很多方法仅仅把句法结构当作一种离散特征,为不同的句法结构分配一个ID。这样的特征表示方法丢失了原有的结构信息,使得句法结构之间的相似性得不到体现,而且还可能会造成数据稀疏的问题。
因此,我们需要使用一种更好的方式来利用句法结构的信息。Zelenko[5]提出了使用树核(Tree Kernel)函数作为支持向量机的核函数来解决关系抽取问题,它能够接受树形结构作为特征,隐式地在高维空间中对树形结构进行表示。
除了句法结构信息外,我们还希望能够使用一些包含语义信息的特征。例如,词向量就是一种含有语义信息的特征。通过对大规模语料中词语的上下文信息进行建模,使得具有相似词义的词语在词向量的空间中位置更加接近。
基于句法与语义信息核函数的情感搭配抽取
为了在一句评论中提取出评价对象和评价词之间的搭配关系,我们可以依次遍历句子中的所有词对,并通过SVM分类器判断该词对之间是否满足“评价对象-评价词”的搭配关系。
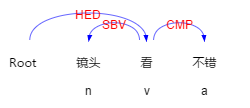
关键句法路径是关系分类任务上常用并且很有效的特征[4]。所谓关键句法路径,是指句法树中待判断的两个词之间的最短路径。图2给出了“这个镜头看起来很不错”一句中“镜头”和“不错”两个词之间的关键句法路径。为了在SVM分类器中利用句法结构信息提高模型性能,本文使用了树核函数来接受关键句法路径作为特征。
图2 “这个镜头看起来很不错” 中“镜头”和“不错”之间的关键句法路径
树核函数能够高效地提供两个句法结构之间的相似度。对于两个句法结构,它们的相似度定义为相同子集合树结构[7]的个数,这种树核函数叫做子集合树核函数(Sub Set Tree Kernels, SSTK)。例如图3展示了“屏幕很不错”和“镜头很不错”两个句法结构,以及它们所有的子集合树结构。从图中可以看出,两句话的5个子集合树结构中,有3个完全一样,因此它们的相似度为3。
本文为了使句法结构特征更加泛化,句法结构中的词节点使用词性来表示。例如,对于“屏幕很不错”,将产生特征(a (SBV n)(ADV d))。
除了关键句法路径特征外,本文还尝试引入词向量作为语义信息的补充。词向量是对一个词的语义特征的表示,词与词之间的语义越接近,他们在向量空间中的位置就会越近。本文设计了两种词向量的使用方式,一种是将待识别的两个词的词向量相连接,另一种是对关键句法路径上的所有词的向量进行平均。
此外,人工提取特征也可以作为补充信息加入进来。本文一共设计了如表1所示的5类离散特征,统一称作Flat特征:
表1 Flat特征

上表中,w代表了待识别的两个词,t代表了他们的词性。即Flat特征包含了两个词前后一个词的Unigram词特征、Unigram词性特征、Bigram词特征、Bigram词性特征、关键句法路径ID特征。
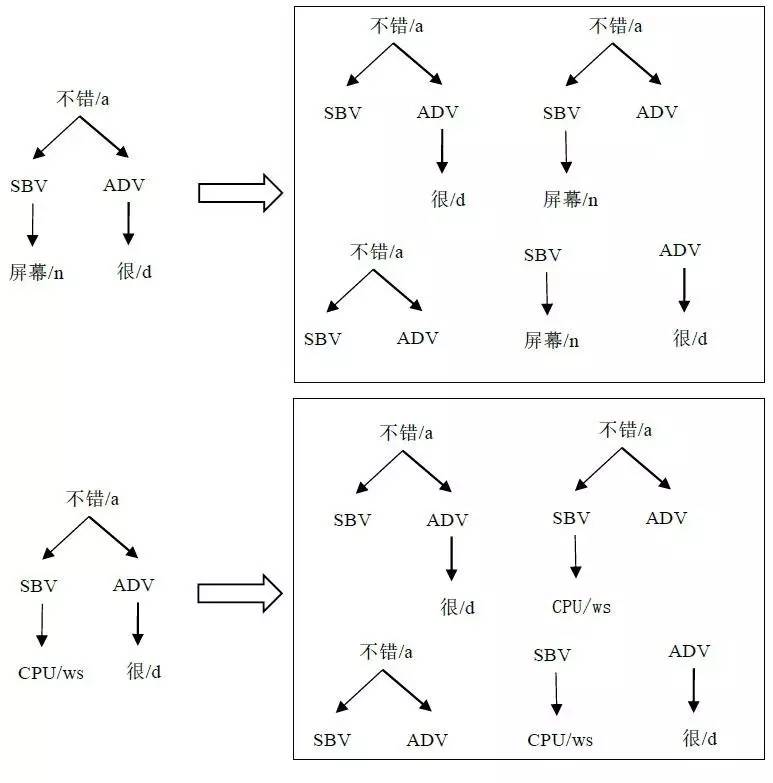
图3 “屏幕很不错” 和“CPU很不错”的句法结构及子集合树结构。
Flat特征和词向量语义特征均为向量特征。向量特征和树形结构特征之间的权重关系通过α调节,即:
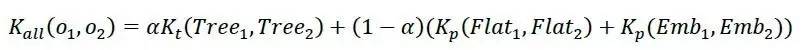
其中 Kt 为树核函数,Kp 为多项式核函数。Tree、Flat、Emb分别为树形句法结构特征、Flat特征和词向量语义特征。本文还设计了权重α的调节实验,以便确定α对模型性能的影响。
实验设置
语料集
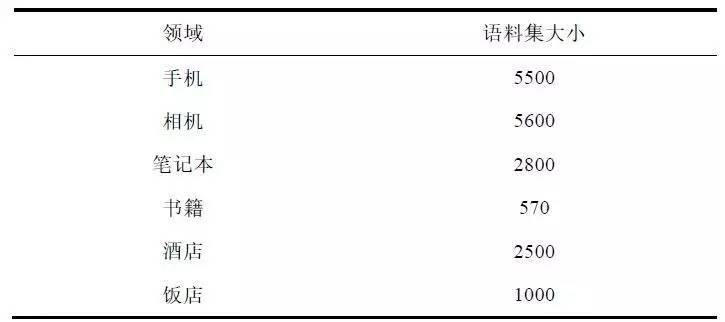
语料集方面,一共对手机、相机、笔记本、书籍、酒店、饭店六个领域的语料进行了实验。每个领域的语料规模如表2所示。
表2 搭配识别任务语料集规模
除了正例语料(即正确的搭配词对)以外,负例语料的构建方式为:首先构建出所有在正例语料中出现过的评价对象和评价词,分别形成评价对象集合和评价词集合;随后在对句子进行处理时,将其中所有的名词作为评价对象的候选,所有形容词作为评价词的候选,对这两个候选集合做笛卡尔乘积,形成候选负例搭配词对;最后,过滤掉那些词对中评价对象候选词不在评价对象集合中、评价词候选词也不在评价词集合中的搭配。最后剩下的候选负例搭配词对作为负例语料。
这样的负例语料构建方式既减少了负例语料的规模,又留下了与正例更相似的负例,有利于训练出性能更好的模型。另外,由于正负例语料不够均衡,我们在实验中还针对每一个领域分别调整了Cost参数。
特征选择
本文使用了以下特征进行基于Tree Kernel SVM的搭配关系抽取实验:
• Flat 包含了待识别评价对象及评价词前后2个词语的Unigram词ID特征、Unigram词性特征、Bigram词ID特征、Bigram词性特征、关键句法路径的句法结构ID特征作为词向量特征
• Flat + Emb-Avg 使用所有Flat特征、以及句法结构中每个词的词向量根据句法层次平均后作为词向量特征
• Flat + Emb-Concat 使用所有Flat特征、以及将待识别评价对象及评价词的向量相连接作为词向量特征
• Flat + Tree 使用所有Flat特征、以及利用树核函数接受待识别评价对象及评价词之间的关键句法路径作为特征
• Flat + Tree + Emb-Avg 使用所有的Flat特征、树核函数接受的关键句法路径特征、以及Emb-Avg特征
• Flat + Tree + Emb-Concat 使用所有的Flat特征、树核函数接受的关键句法路径特征、以及Emb-Concat特征
其中,所有使用的词向量均为在新浪微博大规模语料上训练的50维词向量。所有树形结构特征与向量特征的权重均设置为0.5(即α=0.5)。
工具集与评价指标
实验中使用的分词、词性标注、句法分析器为语言技术平台LTP。实验使用svmlight-tk[8][7]工具包进行SVM分类实验,svmlight-tk支持线性核函数、树核函数等常见的核函数,并支持树形结构特征与向量特征的混合使用。
实验结果使用精确率、召回率和F1值进行评价。实验结果采用软匹配的方式,即提取出的词包含或被包含于标准词语中即算作正确。
实验结果及分析
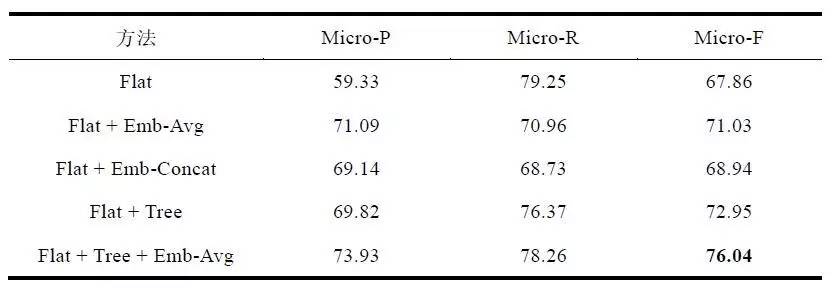
基于Tree Kernel SVM方法的搭配关系抽取实验结果如表3所示。表中所有方法的实验数据均为在上述6个领域上实验结果的微平均(Micro Average),即按照测试语料规模加权平均。
表3 Tree Kernel SVM 搭配关系抽取实验结果(%)
对上述实验结果进行比较分析可以发现:
(1) 对比Flat方法与Flat + Emb-Avg、Flat + Emb-Concat两种方法可以得出,词向量由于包含了更多的语义信息,作为SVM的特征使用时能够带来一定的性能提升。
(2) 对比Flat + Emb-Avg与Flat + Emb-Concat两种方法可以得出,虽然Emb-Concat特征采用连接两个候选词词向量的方式构造特征,信息丢失较少,但由于Emb-Avg特征中包含了关键句法路径上所有词语的词向量内容,因此Emb-Avg特征仍然取得了较好的效果。
(3) 对比Flat方法与Flat + Tree方法可以得出,关键句法路径特征能够有效提高关系分类模型的性能。
(4) 对比Flat + Tree方法与Flat + Emb-Avg、Flat + Emb-Concat可以发现,在关系分类任务上,关键句法路径作为特征的有效性甚至超过了使用词向量作为特征。
(5) 对比Flat + Tree + Emb-Avg、Flat + Tree + Emb-Concat与其他模型可以发现,在混合使用关键句法路径特征和词向量特征后,模型性能得到了进一步的提高,这说明了关键句法路径特征所提供的信息中有相当一部分是词向量特征所无法提供的。
同时,为了进一步确认树形句法结构特征在分类中所起到的作用,还进行了比重调节实验。调节树形句法结构特征与向量特征(包含Flat特征与Emb-Avg词向量特征)之间的比重所得到的实验结果如图4所示。
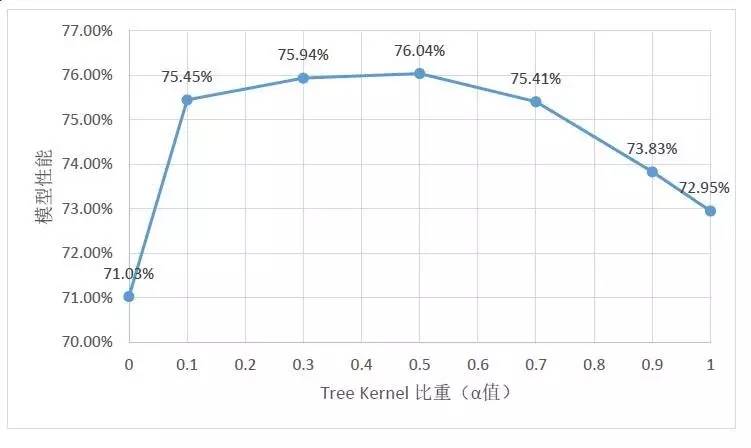
图4 树形句法结构特征比重实验结果
从比重调节实验结果可以看出,α参数取0.5左右能够到达最佳性能;在权重不断增加或降低的过程中,性能不断下降;而在单独使用树形特征和向量特征时,均无法达到一同使用时的性能。
总结
本文首先介绍了搭配抽取相关的任务和方法,并介绍了支持向量机(SVM)与核函数的相关内容。支持向量机作为一种二元线性分类器,通过寻找最大间隔平面来减少泛化误差。同时,支持向量机对核函数的利用使得其不再局限于一般的线性分类器的能力,这是因为核函数能够将低维的向量映射至高维空间,而又不需要显式地计算出高维空间向量。核函数本质上是一个相似度函数,这使得核函数不仅可以接受向量特征,还能够接受结构特征,使得结构特征能够在支持向量机中得到应用。
本文随后讨论了如何使用融合了依存句法结构信息和语义信息的核函数对评价对象与评价词进行抽取,并对不同的特征组合进行了实验。实验结果表明,使用树核函数接受句法结构信息能够明显提高模型的性能,融合了向量特征后性能得到进一步的提高,这说明句法结构特征和词向量特征均能够很有效地用于解决关系分类问题。同时本文还通过调节树核函数与线性核函数之间的比重,发现了当句法结构特征的权重在0.5时,模型的性能最好,进一步说明了各项特征的有效性。
参考文献
[1] Bo P, Lee L, Vaithyanathan S. Thumbs up?: sentiment classification using machine learning techniques[J]. 2002:79-86.
[2] 赵妍妍, 秦兵, 刘挺. 文本情感分析[J]. 软件学报, 2010, 21(8):1834-1848.
[3] Bo P, Lee L. Opinion Mining and Sentiment Analysis[M]. Now Publishers Inc, 2008.
[4] Bach N, Badaskar S. A SURVEY ON RELATION EXTRACTION[J]. Language Technologies Institute, 2007.
[5] Zelenko D, Aone C, Richardella A. Kernel Methods for Relation Extraction.[J]. Journal of Machine Learning Research, 2003, 3(3):1083-1106.
[6] Culotta A, Sorensen J. Dependency tree kernels for relation extraction[C]// Meeting of the Association for Computational Linguistics, 21-26 July, 2004, Barcelona, Spain. DBLP, 2004:423-429.
[7] Duffy N, Duffy N. New ranking algorithms for parsing and tagging: kernels over discrete structures, and the voted perceptron[C]// Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2002:263-270.
[8] Moschitti A. Making Tree Kernels Practical for Natural Language Learning[C]// Eacl 2006, Conference of the European Chapter of the Association for Computational Linguistics, Proceedings of the Conference, April 3-7, 2006, Trento, Italy. DBLP, 2006.
本期责任编辑: 郭江
本期编辑: 李家琦
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,郭江,赵森栋
编辑: 李家琦,施晓明,张文博,赵得志
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。






