一文了解成分句法分析

本文介绍了自然语言处理中成分句法分析,包括定义、基本任务、常见方法以及短语结构和依存结构的关系,最后,分享了一些流行的工具以及工具实战例子。
01
定义
维基百科上给的定义如下:The constituency-based parse trees of constituency grammars (= phrase structure grammars) distinguish between terminal and non-terminal nodes. The interior nodes are labeled by non-terminal categories of the grammar, while the leaf nodes are labeled by terminal categories.
句子的组成成分叫句子成分,也叫句法成分。在句子中,词与词之间有一定的组合关系,按照不同的关系,可以把句子分为不同的组成成分。句子成分由词或词组充当。
句法结构分析是指对输入的单词序列(一般为句子)判断其构成是否合乎给定的语法,分析出合乎语法的句子的句法结构。
句法结构一般用树状数据结构表示,通常称之为句法分析树(syntactic parsing tree)或简称分析树(parsing tree),而完成这种分析过程的程序模块称为句法结构分析器(syntactic parser),也简称分析器(parser)。
02
基本任务
句法结构分析的基本任务主要有三个:
1. 判断输入的字符串是否属于某种语言。
2. 消除输入句子中的词法和结构等方面的歧义。
3. 分析输入句子的内部结构,如成分构成、上下文关系等。
如果一个句子有多种结构表示,句法分析器应该分析出该句子最有可能的结构。有时人们也把句法结构分析称为语言或句子识别。
一般构造一个句法分析器需要考虑二部分:语法的形式化表示和词条信息描述问题,分析算法的设计。目前在自然语言处理中广泛使用的是上下文无关文法(CFG)和基于约束的文法(又称合一语法)。
03
常见方法
句法结构分析可以分为基于规则的分析方法、基于统计的分析方法以及近年来基于深度学习的方法等。
基于规则的分析方法:其基本思路是由人工组织语法规则,建立语法知识库,通过条件约束和检查来实现句法结构歧义的消除。
基于统计的分析方法:统计句法分析中目前最成功当属基于概率上下文无关文法(PCFG或SCFG)。该方法采用的模型主要包括词汇化的概率模型(lexicalized probabilistic model)和非词汇化的概率模型(unlexicalized probabilistic model)两种。
基于深度学习的分析方法:近几年深度学习在nlp基础任务取得了不错的效果,也涌现出了不少论文。
04
短语结构和依存结构关系
短语结构树可以被一一对应地转化成依存关系树,反过来则不然,因为一棵依存关系树可能对应多个短语结构树。转化方法可以通过如下实现:
定义中心词抽取规则,产生中心词表;
根据中心词表,为句法树中每个结点选择中心子结点;
同一层内将非中心子结点的中心词依存到中心子结点的中心词上,下一层的中心词依存到上一层的中心词上,从而得到相应的依存结构。
05
工具推荐
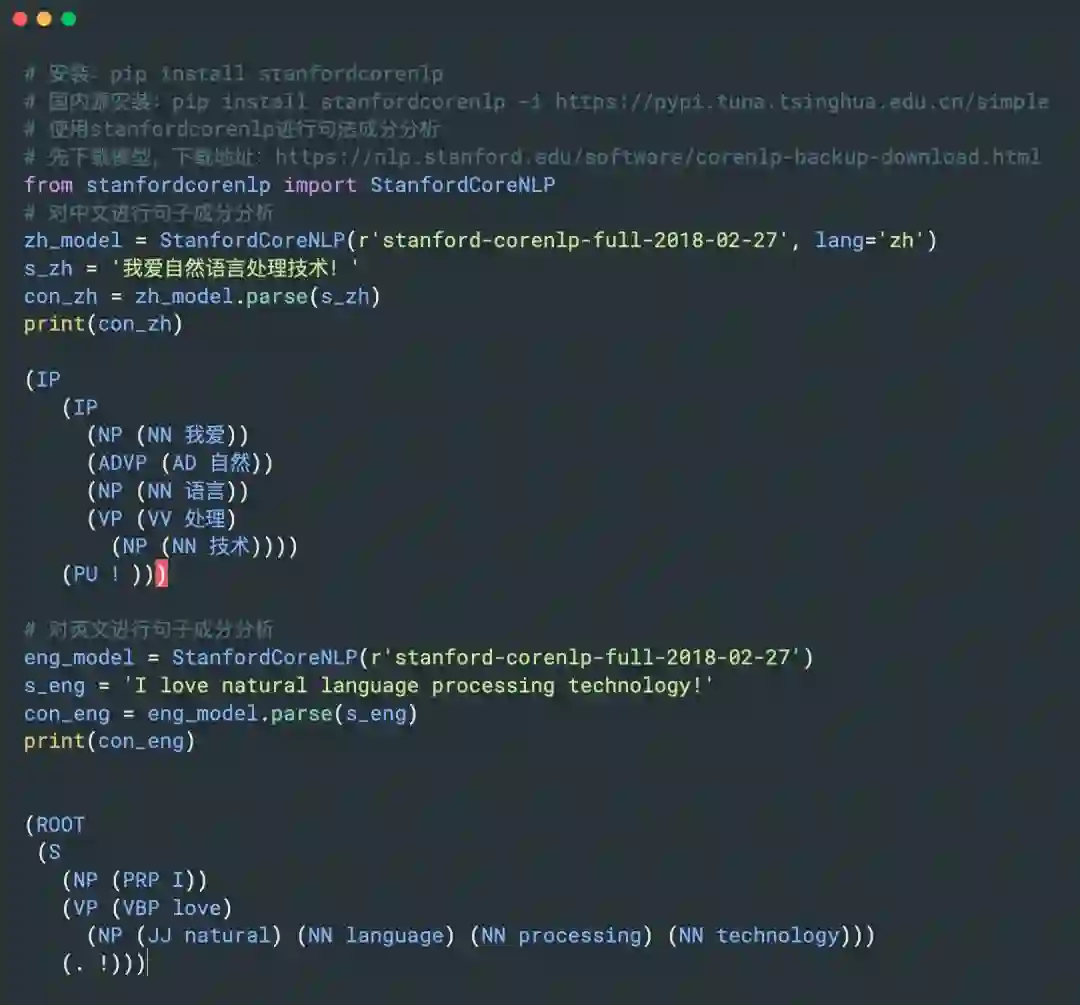
1. StanfordCoreNLP
斯坦福的,提供成分句法分析功能。
Github 地址:
https://github.com/Lynten/stanford-corenlp
官网:
https://stanfordnlp.github.io/CoreNLP/
2. Berkeley Parser
伯克利大学 NLP 组开源的工具。提供英文的句法分析功能。
官方地址:
http://nlp.cs.berkeley.edu/software.shtml
3. SpaCy
工业级的自然语言处理工具,遗憾的是不支持中文。
Gihub 地址:
https://github.com/explosion/spaCy
官网:
https://spacy.io/
代码已上传:
https://github.com/yuquanle/StudyForNLP/blob/master/NLPbasic/Constituency.ipynb
参考:
1. 统计自然语言处理
2. 中文信息处理报告-2016
相关阅读:

作者简介
乐雨泉 (yuquanle),湖南大学在读硕士,研究方向机器学习与自然语言处理。曾在IJCAI、TASLP等会议/期刊发表文章多篇。欢迎志同道合的朋友和我在公众号"AI小白入门"一起交流学习,探讨成长。

# 点击「阅读原文」 技术书限时特价中 #