从R-CNN到Mask R-CNN!

自从2012年的ILSVRC竞赛中基于CNN的方法一鸣惊人之后,CNN已成为图像分类、检测和分割的神器。其中在图像检测的任务中,R-CNN系列是一套经典的方法,从最初的R-CNN到后来的Fast R-CNN, Faster R-CNN 和今年的Mask R-CNN, 我们可以看到CNN在图像检测中是如何一点一点提高的。和本文来一道回顾R-CNN家族的发展史,了解这些方法的演变和这个演变过程中的那些富有创意的想法。
R-CNN 系列的四篇文章如下:
R-CNN: https://arxiv.org/abs/1311.2524
Fast R-CNN: https://arxiv.org/abs/1504.08083
Faster R-CNN: https://arxiv.org/abs/1506.01497
Mask R-CNN: https://arxiv.org/abs/1703.06870
图像的检测任务是从一个复杂场景的图像中找到不同的物体,并且给出各个物体的边界框。图像检测的三个著名的数据集是PASCAL VOC,ImageNet和微软COCO. PASCAL VOC包含20个物体的类别,而ImageNet包含一千多种物体类别,COCO有80中物体类别和150万个物体实例。


1, R-CNN
R-CNN的思路是很直观的三步曲:1,得到若干候选区域;2, 对每个候选区域分别用CNN分类;3,对每个候选区域分别进行边框预测。
在R-CNN出现之前,目标检测的流行思路是先从图像中得到一些候选区域,再从候选区域中提取一些特征,然后利用一个分类器对这些特征进行分类。分类的结果和候选区域的边界框就可以作为目标检测的输出。一种得到候选区域的方法是Selective Search, 该方法可以得到不同尺度的候选区域,每个候选区域是一个联通的区域。如下图中,左边得到的是较小的候选区域,右边是较大的候选区域,在该尺度下包含了整个人的区域。

R-CNN的想法是,既然CNN在图像分类任务中的表现很好,可以自动学习特征,何不用它来对每个候选区域进行特征提取呢?于是R-CNN在Selective Search得到的候选区域的基础上,将每个候选区域缩放到一个固定的大小,并且作为AlexNet(ImageNet 2012图像分类竞赛的冠军)的输入,依次对这些区域进行特征提取,然后再使用支持向量机对各个区域的特征分别进行分类。R-CNN的过程如下:
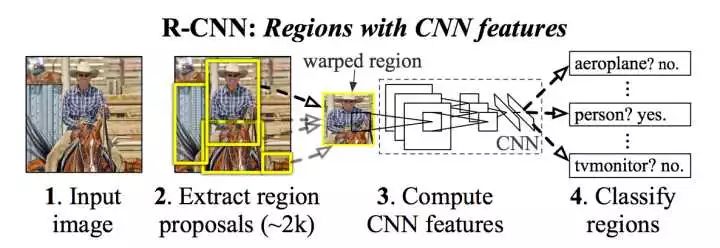
这样就能得到一个检测的结果了。但是Slelective Search得到的候选区域并不一定和目标物体的真实边界相吻合,因此R-CNN提出对物体的边界框做进一步的调整,使用一个线性回归器来预测一个候选区域中物体的真实边界。该回归器的输入就是候选区域的特征,而输出是边界框的坐标。
R-CNN的效果很不错,比VOC 2012的最好的结果提高了30%的准确度。但是问题就是太慢,主要有三方面原因:1,候选区域的生成是一个耗时的过程;2,对候选区域特征提取需要在单张图像上使用AlexNet 2000多次; 3, 特征提取、图像分类、边框回归是三个独立的步骤,要分别进行训练,测试过程中的效率也较低。
2, Fast R-CNN
为了解决R-CNN中效率低的问题,Fast R-CNN想,一张图像上要使用AlexNet 2000多次来分别得到各个区域的特征,但很多区域都是重合的,可否避免这些重复计算,只在一张图像上使用一次AlexNet,然后再得到不同区域的特征呢?
于是Fast R-CNN提出了一个ROI Pooling的方法,先对输入图像使用一次CNN前向计算,得到整个图像的特征图,再在这个特征图中分别取提取各个候选区域的特征。由于候选区域的大小不一样,而对应的特征需要要具有固定的大小,因此该方法对各个候选区域分别使用POI Pooling, 其做法是:假设第 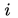
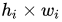
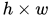
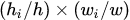
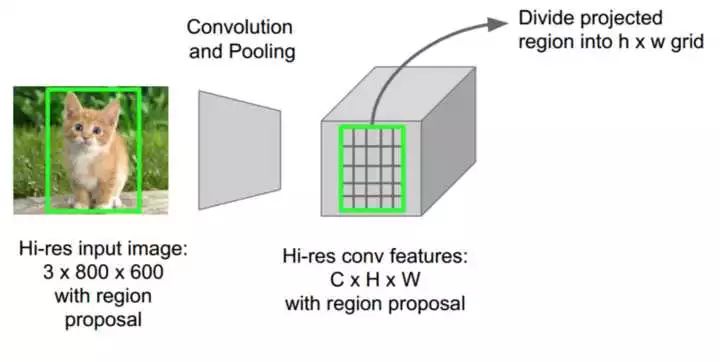
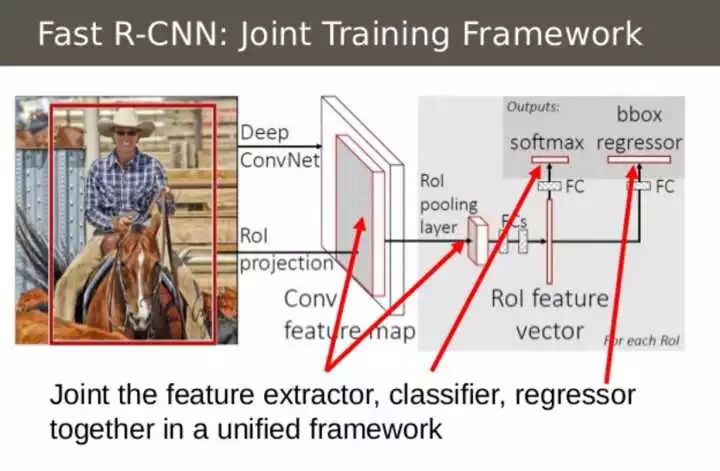
Fast R-CNN的第二点创意是把之前独立的三个步骤(特征提取、分类和回归)放到一个统一的网络结构中。该网络结构同时预测一个候选区域的物体类别和该物体的边界框,使用两个全连接的输出层分别进行类别预测和边框预测(如下图所示),将这两个任务进行同时训练,利用一个联合代价函数:
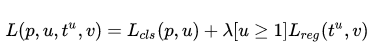
公式中的两项分别是classification loss 和regression loss。
使用VGG16作为特征提取网络,Fast R-CNN在测试图像上的处理时间比R-CNN快了200多倍,并且精度更高。如果不考虑生成候选区域的时间,可以达到实时检测。生成候选区域的Selective Search算法处理一张图像大概需要2s的时间,因此成为该方法的一个瓶颈。
3, Faster R-CNN
上面两种方法都依赖于Selective Search生成候选区域,十分耗时。考虑到CNN如此强大,Faster R-CNN提出使用CNN来得到候选区域。假设有两个卷积神经网络,一个是区域生成网络,得到图像中的各个候选区域,另一个是候选区域的分类和边框回归网路。这两个网络的前几层都要计算卷积,如果让它们在这几层共享参数,只是在末尾的几层分别实现各自的特定的目标任务,那么对一幅图像只需用这几个共享的卷积层进行一次前向卷积计算,就能同时得到候选区域和各候选区域的类别及边框。
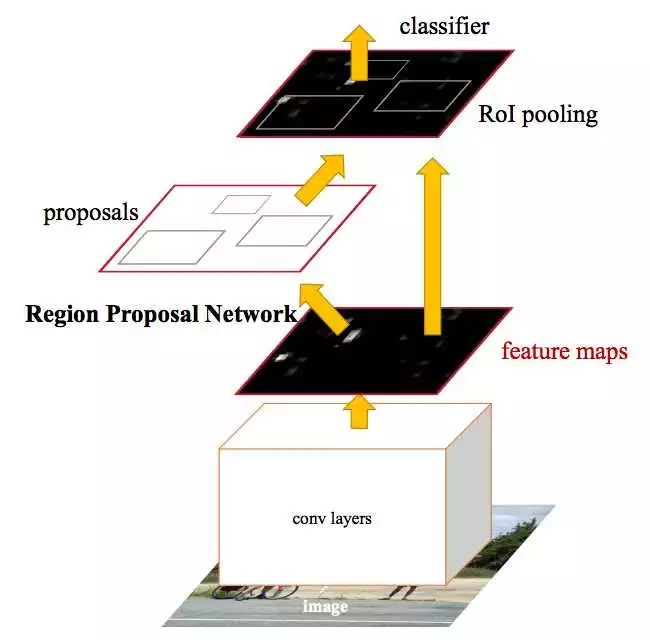
候选区域生成网络(Region Proposal Network, RPN)如下,先通过对输入图像的数层卷积得到一个特征图像,然后在特征图像上生成候选区域。它使用一个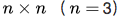
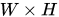
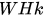
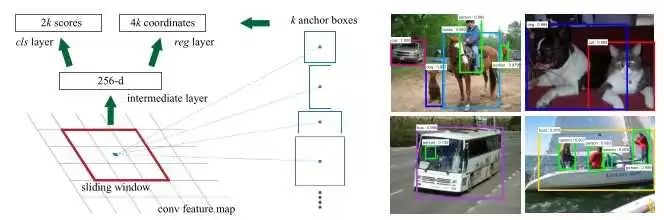
使用RPN得到候选区域后,对候选区域的分类和边框回归仍然使用Fast R-CNN。这两个网络使用共同的卷积层。 由于Fast R-CNN的训练过程中需要使用固定的候选区域生成方法,不能同时对RPN和Fast R-CNN使用反向传播算法进行训练。该文章使用了四个步骤完成训练过程:1,单独训练RPN;2,使用步骤中1得到的区域生成方法单独训练Fast R-CNN; 3, 使用步骤2得到的网络作为初始网络训练RPN;4, 再次训练Fast R-CNN, 微调参数。
Faster R-CNN的精度和Fast R-CNN差不多,但是训练时间和测试时间都缩短了10倍。
4, Mask R-CNN
Faster R-CNN 在物体检测中已达到非常好的性能,Mask R-CNN在此基础上更进一步:得到像素级别的检测结果。 对每一个目标物体,不仅给出其边界框,并且对边界框内的各个像素是否属于该物体进行标记。

Mask R-CNN利用Faster R-CNN中已有的网络结构,再添加了一个头部分支,使用FCN对每个区域做二值分割。
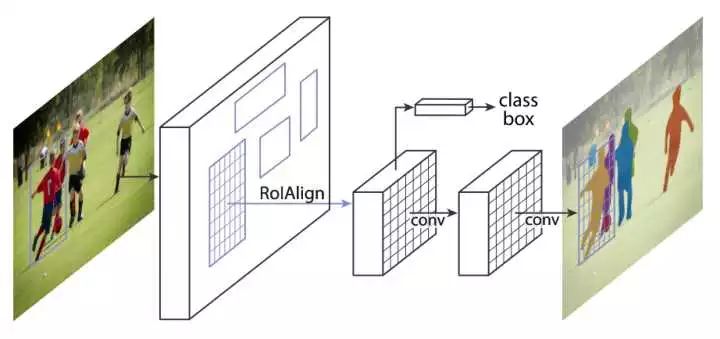
Mask R-CNN还提出了两个小的改进使分割的结果更好。第一,对各个区域分割时,解除不同类之间的耦合。假设有K类物体,一般的分割方法直接预测一个有K个通道的输出,其中每个通道代表对应的类别。而Mask R-CNN预测K个有2个通道(前景和背景)的输出,这样各个类别的预测是独立的。第二,Faster R-CNN中使用的ROI Pooling将每个ROI映射到一个固定的大小,在pooling时有取整操作,这样会导致pooling 前后的特征图没有连续的对应关系。例如,如果pooling前的大小是112x112,pooling之后的大小是7x7,对于pooling之前的一个像素,其横坐标位置是 X ,那么pooling后对应的横坐标是 x/16 , 再取整就得到了其在7x7格子中的位置。由于取整操作会带来误差,Faster R-CNN不取整,使用双线性插值得到 X/16处的真实数值,该方法称作ROIAlign.
上述几种方法的代码:
R-CNN
Caffe版本:rbgirshick/rcnn
Fast R-CNN
Caffe版本: rbgirshick/fast-rcnn
Faster R-CNN
Caffe版本: https://github.com/rbgirshick/py-faster-rcnn
PyTorch版本: https://github.com/longcw/faster_rcnn_pytorch
MatLab版本: https://github.com/ShaoqingRen/faster_rcnn
Mask R-CNN
PyTorch版本: https://github.com/felixgwu/mask_rcnn_pytorch
TensorFlow版本: https://github.com/CharlesShang/FastMaskRCNN
注:R-CNN, Fast R-CNN和Faster R-CNN已在之前的文章总结过,这里添上Mask R-CNN。更多目标检测的方法在《深度卷积神经网络在目标检测中的进展》这篇文章中。另外,《A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN》这篇文章也做了详细的介绍。
原文:https://zhuanlan.zhihu.com/p/30967656?group_id=913258673741639680
浙大90后女黑客在GeekPwn2017上秒破人脸识别系统!



