简述微信看一看基于图的多样性召回丨IEEE Transactions on Big Data


导语
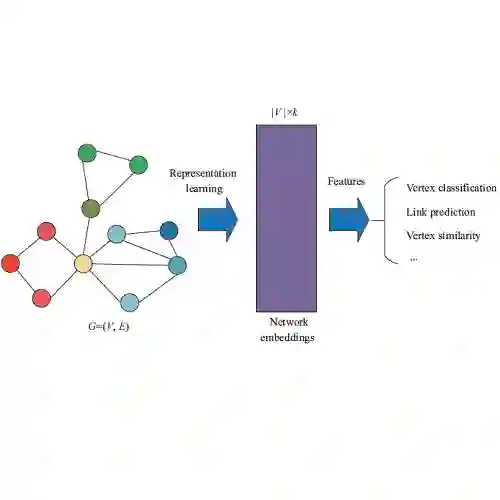
真实世界的推荐系统需要处理百万级的物品(item,如视频、文章等)候选。因此,大规模推荐系统往往包含以下两个模块:召回(matching)和排序(ranking)。召回模块需要高效、准确地从百万级候选物品中选择约几百级别的物品进入排序模块,而排序模块则需要精确地对这些物品进行排序,决定最终展示给用户的物品列表。
在真实推荐场景中,除了推荐准确率(accuracy),推荐结果的多样性(diversity)也是影响用户体验的一个重要指标。目前有很多工作基于物品之间的差异度,关注排序模型的多样性。然而,很少有工作关注召回模型的多样性(我们认为多样性反而是召回模型需要关注的,因为它是排序模型的前置模块,是排序多样性的基础,同时对精准率要求比排序模型更加宽容)。
在这个工作中,我们提出了一种新的GraphDR模型,基于异质图神经网络模型,同时提升召回模块的准确率与多样性。具体地,GraphDR综合考虑了用户(user)、物品(item)、媒体号(media)、标签(tag)、单词(word)等推荐中重要客体之间的全局交互信息,构建了一张异质大图,然后在异质图上使用一种特征域级的异质图注意力网络(field-level heterogeneous graph attention network (FH-GAT))进行节点聚合,得到各个客体的表示。
最后,我们使用一种基于邻居相似度的无监督训练目标(neighbor-similarity based objective),优化节点表示和模型参数,兼顾准确率与多样性。在线上,这些节点表示会被用于多通道召回中。我们进行了广泛的离线和线上实验,在十余个准确率和多样性指标上验证了模型的有效性。GraphDR被部署于微信看一看系统的召回模块,服务千万用户。
模型背景与简介
真实世界的推荐系统往往需要处理成百上千万的物品候选。因此,直接使用端到端的、考虑了复杂user-item交互的推荐算法是十分耗时的。即使是线性时间复杂度的模型,在千万级数据上的时间复杂度都是难以接受的。为了兼顾模型的准确与效率,传统大规模推荐系统往往会包含召回(matching)和排序(ranking)两个模块(如Youtube推荐系统)。召回模块需要高效、准确地从百万级候选物品中选择百级别的物品进入排序模块(如经典的双塔模型)。
而排序模块则需要精确地对这些物品进行精确排序和特征交互建模,决定最终展示给用户的物品列表(如DIN、AutoInt、AutoFIS、AFN等模型)。图1给出了一个经典的召回-推荐两阶段系统示意图,其中召回模块更加关注效率、召回率和多样性指标,而排序模块更关心准确率和物品的具体排序。这个两阶段推荐系统自身就是一种兼顾效率、准确和灵活性的工业实现方式。

图1:经典的两阶段召回-排序推荐系统示意图
传统的推荐模型往往关注CTR等基于准确率的指标,这种情况下,热门物品容易获得算法的偏爱。然而,过于关注CTR指标,可能会带来推荐结果同质化(homogenization)和热点偏差(popularity bias)等问题,从长期上看会影响用户体验,降低个性化推荐效果。为了解决这个问题,有一些工作开始在推荐模型中综合考虑多样性指标。
基于视角的不同,推荐多样性常常可以分为以下两个类别:个体多样性(individual diversity)和聚合多样性(aggregate diversity)。个体多样性关注某个推荐结果列表中的局部多样性,希望能够同时满足用户-物品的相似度,以及被推荐物品之间的差异度。聚合多样性则关注整体推荐系统的全局多样性,往往通过整体被推荐物品的覆盖度和长尾率等指标进行衡量。推荐系统多样性指标的重要性已经在现实中被证明,而以上两种多样性指标均需要被考虑。
已有的考虑多样性的推荐往往部署于排序模型上,将推荐结果列表中被推荐物品之间的差异度作为优化指标。然而,这些工作很难直接迁移到召回模型上,因为召回模型的候选池和输出结果池都远大于排序模型,计算物品候选之间的两两差异度十分耗时。
事实上,我们认为召回模型更需要对推荐结果的多样性负责,因为(1)它是排序模型的前置模块,召回多样性是最终结果多样性的基本条件;(2)召回对精准率要求比排序更加宽容(只需要给出top 500的物品,而不需要分辨top 500物品的精确排序),适合兼顾多样性指标。
在这个工作中,我们希望能够同时提升推荐系统召回模块的准确率与多样性。我们提出一个新的基于异质图神经网络的GraphDR模型。具体地,GraphDR包含三个模块:(1)多样性偏好网络构建模块(Diversified preference network construction),负责基于用户(user)、物品(item)、媒体号(media)、标签(tag)、单词(word)等5种客体之间的6种异质全局交互信息,构建一张包含用户多样性偏好的全局网络。这个全局大图中的多种异质交互信息从不同角度(例如相同群体、相似标签/关键词/文章来源、session行为信息等)描述了用户的多样化的兴趣偏好,成为GraphDR模型多样性的基本来源。(2)异质图表示学习模块(Heterogeneous network representation learning),使用特征域级的异质图注意力网络模型(FH-GAT),从上述多样性偏好网络中学得各种异质节点的聚合向量表示。我们使用一种基于邻居相似度的无监督训练目标(neighbor-similarity based objective)学习节点表示和模型参数,和传统的CTR-oriented loss相比,进一步强调结果多样性。(3)线上多通道召回模块(Online multi-channel matching),从标签、媒体和物品等多个角度,快速召回用户可能感兴趣的物品,通过多通道召回进一步放大多样性。GraphDR的多样性提升来源于全部三个模块的设计。
在实验部分,我们在拥有千万级用户的微信看一看真实系统数据下进行了离线和线上实验。GraphDR在十几个离线/线上准确率和多样性指标上都获得了显著提升。我们也进行了详尽的模型分析和消融实验,验证模型各个模块和参数设置的有效性。我们总结这个工作的主要贡献点如下:
1、我们强调了在推荐系统召回模块上考虑多样性的重要性,并且系统性地研究了在召回模块兼顾准确率、多样性和效率的方法;
2、我们提出了一个全新的GraphDR框架,基于全局异质多样性偏好网络、邻居相似度的训练目标和线上多通道召回等设计,兼顾推荐的准确率与多样性;
3、模型在十几个离线/线上准确率和多样性指标上都获得了显著提升。GraphDR也已经部署于微信看一看上,经过了真实系统千万用户的长期验证。另外,GraphDR是一个简单有效的通用框架,易部署和迁移至大多数召回场景。
具体模型
▍2.1 整体模型结构
图2给出了GraphDR的整体结构图。如前所述,在离线阶段,模型首先基于用户(user)、物品(item)、媒体号(media)、标签(tag)、单词(word)等5种客体(作为节点)之间的6种异质全局交互信息(作为边),构建一张全局的多样性偏好网络(Diversified preference network)。
然后,特征域级的异质图注意力网络模型(FH-GAT)在这张图上进行节点聚合,得到所有异质节点表示,并且基于邻居相似度的目标(neighbor-similarity based objective)和图上的邻居关系,学习节点表示和模型参数。
线上的多通道召回模块(Online multi-channel matching)从用户历史行为记录中获取用户对于不同客体的偏好(如物品、标签、媒体号等),然后基于离线学习到的节点向量进行基于相似度的多通道快速召回,获取最终召回结果。模型的整体思想直观但有效,也能快速适配不同召回系统和推荐场景。

图2:模型整体结构图
▍2.2 多样性偏好网络
多样性偏好网络旨在联合储存用户-物品点击行为信息之外的其它异质信息,从用户偏好的产生源头增加召回多样性。因此,我们选择了用户、物品、媒体号、标签、单词等推荐中的重要客体,作为多样性偏好网络的5种异质节点。基于以上节点,我们选择了以下6种边构建用户的不同偏好信息:
1、物品-物品边:如果两个物品在一个click session中的相邻位置出现,则计为一次session共现。对于视频,我们要求了一定的播放完成度,以保证click行为的质量。这种共现代表了一种泛化的物品相似性或用户观看习惯(例如吃播->探店视频->烘焙教程->铁器锻造科普)。物品-物品session共现数超过一定阈值则产生连边。
2、物品-用户边:反映用户点击物品的行为。这是传统推荐模型的主要监督信息。
3、物品-标签边:物品和其所属的标签之间连边。这里的标签(tag)也可以替换成category/topic等其它taxonomies,代表物品的粗粒度分类信息。用户可能对于粗粒度标签而非细粒度物品有明显偏好。
4、物品-单词边:物品和其标题中的单词有连边(根据需要,这里物品的单词也可以包括正文的关键词等文本信息)。这里保存的是用户的语义上的偏好信息。
5、物品-媒体号边:物品和发表物品的媒体号之间有连边。这里保存的是用户对于信息来源(如用户喜欢的公众号)的偏好。
6、标签-标签边:标签在一个物品上的共现产生标签-标签边,主要用于加强标签之间的相关性。
可以看到,在传统的用户-物品交互信息之外,我们还考虑了用户观看习惯、粗粒度标签、信息来源、语义等其它角度的偏好信息。这些信息能够在点击行为信息之外,极大地增加最终表示的多样性,成为召回模块的多样性来源。
▍2.3 考虑多样性的网络表示学习
我们使用一种特征域级的异质图注意力网络模型(FH-GAT)在这张图上进行节点聚合,得到所有异质节点表示。具体地,FH-GAT会在用户、物品、媒体号、标签、单词等特征域上分别进行GAT聚合,然后再进行联合。




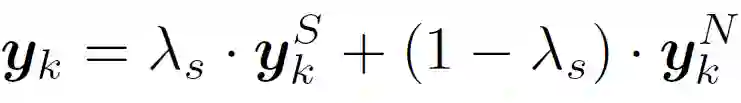
这种简单的GAT改进强调了不同邻居的相同特征域之间的交互,能够更加完整地把不同特征域的信息通过节点聚合传导至最终的聚合节点表示中。
▍2.4 多样性驱动的训练目标
我们使用了一种基于邻居相似度的无监督的训练目标(neighbor-similarity based objective),在多样性偏好网络上优化聚合节点表示。这种训练目标想法很直观:希望多样性偏好网络中相邻(包括同质及异质)节点的聚合节点表示之间更加相似。具体如下:
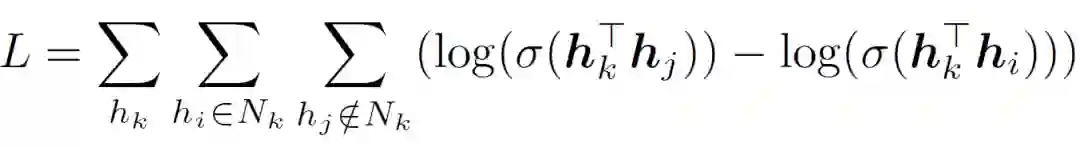
如果仅仅考虑物品-用户边,这种训练目标则退化成为通常的MF推荐模型。我们使用基于邻居相似度的训练目标的原因主要如下:(1)在这个目标下,用户的多样化偏好信息(如用户点击、用户观看习惯、粗粒度标签、信息来源、语义等多样化角度的偏好)都被统一建模进节点表示中,兼顾准确率和多样性;(2)GraphDR是一个召回模型,最终线上是基于类似FAISS的近似近邻查询(ANN)服务,基于向量相似度进行快速召回。而这个基于邻居相似度的训练目标直接优化了线上使用的异质节点向量之间的相似度(例如标签->物品、媒体号->物品等),事半功倍。
▍2.5 线上部署
我们在线上实现了多通道召回,选择了物品、标签和媒体号作为三个通道。以标签为例,我们首先将用户历史行为中的点击物品的多个标签作为用户的标签偏好候选,然后使用这些标签候选的向量召回其top近邻的物品,计算得分:

其中sim表示标签和物品向量的相似度,x(ij)=1表示物品j在标签i的top近邻物品中,p表示加权分,由历史物品的阅读完成率和到现在的时间等因素联合决定:

物品和媒体号通道也是类似,最后三个score进行加权,作为最后召回模型的排序分score:

为了节省时间,我们可以在离线为所有的物品、标签和媒体号计算top近邻的物品,存入index中。线上多通道召回时,我们只需要实时分析用户历史行为序列中的多样偏好,再基于index召回相似物品候选,然后根据score计算得分选择top 500作为召回模块的输出即可。
实验结果
我们在微信看一看的真实数据集上进行了充分的实验。针对离线准确率,在我们更加关心的HIT@500指标上(和线上系统一致,召回top500个结果),GraphDR取得了最好的结果。
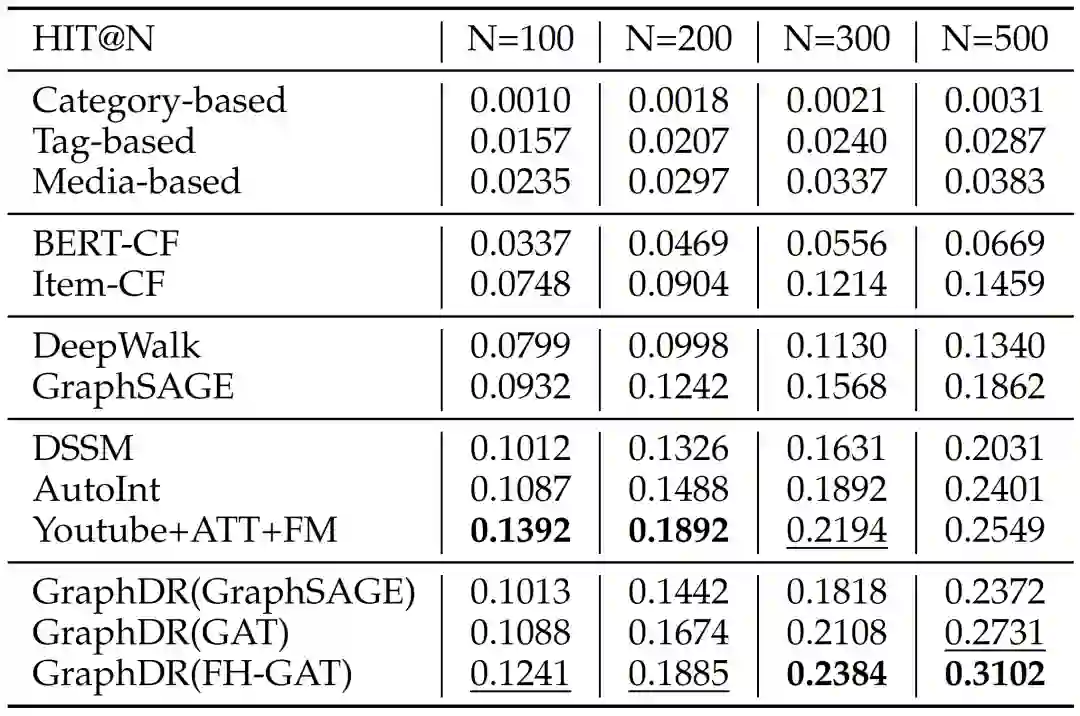
图3:GraphDR召回模型离线准确率结果
在多样性指标上,我们考虑了个体多样性(individual diversity)和聚合多样性(aggregate diversity)的9个多样性指标。GraphDR在所有指标上都获得了显著提升。

图4:GraphDR召回模型离线多样性结果
在线上A/B实验中,GraphDR也在准确率和多样性的多个指标上取得显著提升:

图5:GraphDR线上实验结果
我们还进行了充分的参数实验,分析不同通道召回队列和用户历史行为长度对于最终准确率和多样性的影响:

图6:不同通道召回队列的结果
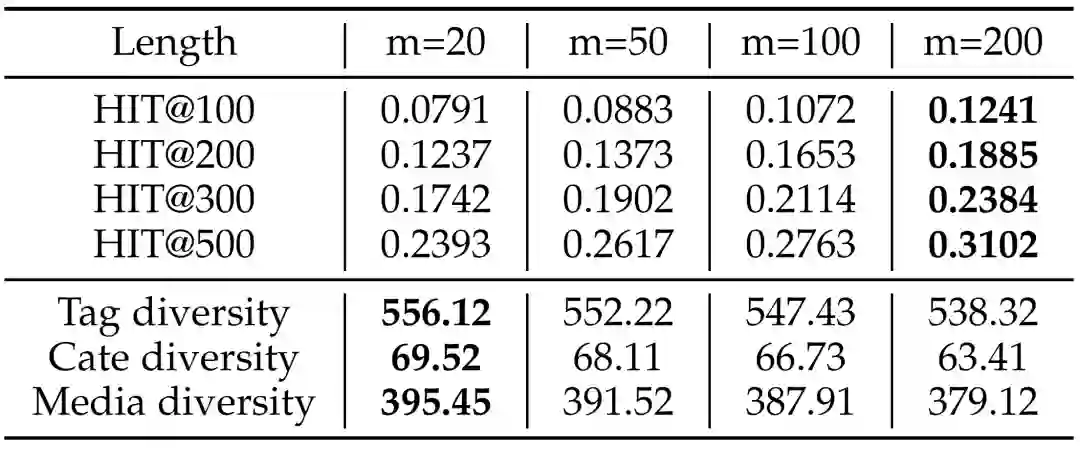
图7:不同历史行为长度的结果
总结
在这篇工作中,我们基于真实推荐场景,设计了一个简单、高效、易部署、易扩充的基于异质图神经网络的召回框架,能够同时提升模型的准确率和多样性。我们的工作证明了异质图神经网络在真实大规模推荐系统上是很有用武之地的。
我们另一篇CIKM-2020的工作Graph Neural Network for Tag Ranking in Tag-enhanced Video Recommendation,也证明了类似的多样性偏好网络和异质图神经网络模型在其它异质推荐场景大有可为。我们也将遵循这篇工作的简单、高效、易部署、易扩充的思想,继续尝试更加高效、通用的异质图神经网络推荐模型。
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。