如何匹配两段文本的语义?
喵喵喵,好久不见啦。首先很抱歉大家期待的调参手册(下)迟迟没有出稿,最近两个月连着赶了4个DDL,整个人都不好了。最近几天终于有时间赶一下未完成的稿子了。在赶DDL的时候夹着写了这篇文章,就先发布这一篇吧~调参手册(下)不出意外的话最近也可以发布啦。
本文由来
一年前在知乎上关注过这么一个问题:如何判断两段文本说的是「同一件事情」? - 知乎 https://www.zhihu.com/question/56751077
如果是document level的判断,那么信息检索中的shingling算法是一个简单有效的解决方案。不过看了一下问题描述,应该是特指sentence level,所以这个问题应该是属于sentence level paraphrase任务。
近期小夕的研究中也顺带研究了一下相关任务,发现这个问题并不是如最高票所言的将QA匹配模型直接搬到这个问题里就万事大吉了。其实在理论层面上这种做法已经很不合适了,里面有很多坑要填,所以本文就试图纠正一下这个问题的导向吧(虽然这属于挖坟行为\(//∇//)\)。
paraphrase与QA匹配
在目前主流的研究方向来看,匹配两段文本的语义主要有两个任务,一个是paraphrase,即判断一段文本是不是另一段文本的释义(即换一种说法,但是意思不变);一个是问答对匹配,或者说检索式QA,即给定一个问题,判断一段文本是不是符合这个问题的回答。最多可以再加上entailment任务,即判断给定一段文本后能不能推理出另一段给定的文本(判断文本2是否可以根据文本1推理得到)。近几年检索式QA的问题非常火,很多文本匹配相关的研究都是将一些QA数据集如insuranceQA、wikiQA作为benchmark。
但是!难道真的如那个知乎问题的最高票回答所言,在QA任务上很有效的文本匹配模型真的能直接拿到paraphrase任务上去?
共通之处
我们先来简单讨论一下这两个任务的共通之处,也就是最最最基本的模型结构。显然,对两段文本进行相似度比较之前,首先要把这两段文本各自encoding成一个压缩上下文信息的矩阵或者直接embedding成一个向量,然后通过矩阵相似度或向量相似度的计算方法得到相似程度就可以啦。显然embedding成向量后的比较更为简单,因为可以直接使用欧式距离或者余弦距离啦,但是显然这样对embedding的质量要求非常高,而且难以进行两段文本之间的细粒度的比较。直接比较encoding后的矩阵的方法听起来虽然好,但是两个矩阵之间的相似度该如何比较?细粒度的词、短语的匹配信息又该如何聚合呢?显然后一种更麻烦一些。
当然,不管是embedding还是encoding,其实都要先encoding╮( ̄▽ ̄””)╭,毕竟同一个词的语义在不同的上下文语境中很可能相差甚远。encoding的模型基本分为CNN系、RNN系、RecNN系以及self-attention系这几种。当然,这几种方法可以叠加使用。我们以CNN为例,讨论一下如何在文本匹配模型中对两段文本进行有效的encoding。
这就不得不提到参考文献[1]啦。这篇文章针对这个问题做了详细的实验。
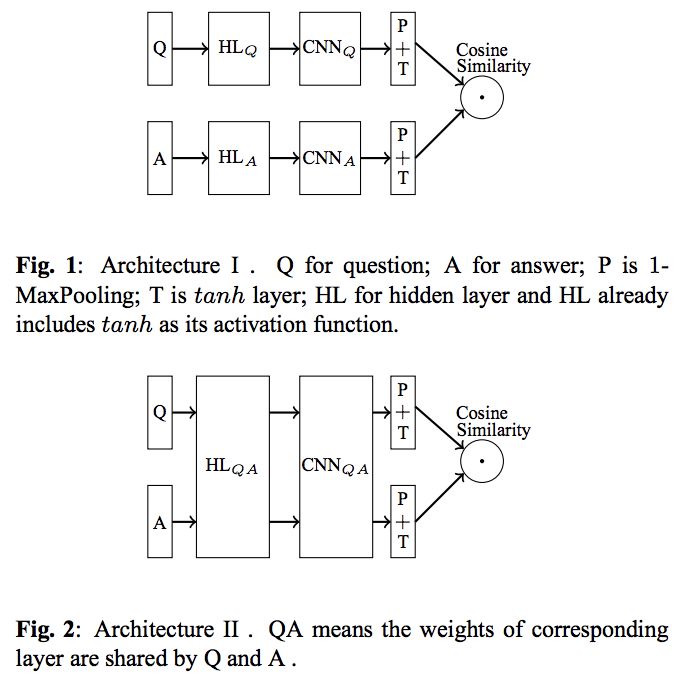
这篇论文实验了6种模型结构,但是我们这里仅关心其中最有意义的一对比较。有兴趣了解全部6种结构的比较的同学可以去看原文哈。
对比图1和图2,图1使用两个CNN网络分别对文本1(Q)和文本2(A)进行encoding,而图2仅仅使用一个CNN,或者说使用两个共享参数的CNN来对两段文本分别进行encoding。然后通过max-over-time-pooling来embedding成向量进而计算余弦距离后发现图2明显的比图1有效(图2比图1高20个百分点,详见参考文献[1])。其实很好理解啦,对两个向量进行余弦距离计算的前提是这两个向量必须要位于同一个embedding空间呀,比如你要是拿三次元的小夕跟二次元的小白狐⬇️相比,【那当然是小夕更可爱啦】(划掉),那当然没有可比性啦,只能说都很可爱。

所以说,图2将两个文本的embedding结果约束在同一个embedding空间内进行比较,当然会比图1这种在两个不同的embedding空间之间进行比较靠谱的多。像图2这种底层共享权重的架构俗称双塔模型(俩基座,但是是同一个塔)。
出问题了╮( ̄▽ ̄””)╭
然而,这种简单做法显然在QA匹配问题上会有明显问题的。哪怕一个回答是标准回答,问题的embedding结果与回答的embedding结果都很难完全一致,而且真的完全一致了也不合理。甚至如果你把问题本身当成回答的话,会发现两段文本的embedding结果一样,导致余弦距离超级近,然而问题本身并不能当作问题的回答呀。但是这对于paraphrase任务来说就没毛病(句子A和句子B完全一致的话,对paraphrase任务里A与B当然应该有最近的距离)。所以其实这时paraphrase与QA匹配的模型应该开始有所区别了。
一方面,由于paraphrase看起来没有大毛病,因此理论上在相似度计算的层面上再取得重大突破应该比较困难,而QA匹配显然在相似度计算的层面上有非常非常大的改进需求。如参考文献[2]的实验结果支撑,文献[2]仅仅使用了简单的attentive pooling就使得模型在多个QA匹配数据集上取得了显著提升(如图3,CNN上提高接近10个百分点),这个实验现象恰好验证了上述小夕的理论猜想。
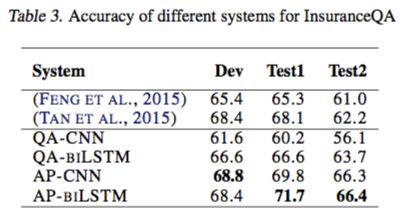
图3
而在Quora数据集(也是一个paraphrase detection任务)里Quora给出的baseline来看(如图4,见参考文献[3]),果然使用attention的模型并没有明显的优越性(甚至性能还不如不用attention)。
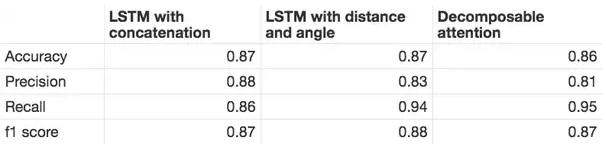
图4
抱着好奇,小夕在某不方便透露的数据集上也做了实验,实验了在QA匹配上辣么有效的attentive pooling,除了文章中提到的attention方法(机器翻译领域中貌似叫general attention[4]),小夕还额外实验了无参数的dot attention[4]以及经典的additive attention[5],结果发现在该paraphrase数据集上效果最好的是additive attention,但是在char-level上比不用attention低了整整3个点的f1,在word-level上也仅仅有0.几的提升,还不排除随机初始化的影响。而原文里的attentive pooling直接惨出天际,这还都是调参后的结果。
为什么呢?其实依然非常好理解,以attentive pooling为例,其核心就是这么一个对齐矩阵的计算公式:
")
其中U是可训练的参数矩阵,Q是文本1,A是文本2,G是对齐矩阵,存储着Q中每个词跟A中每个词的相关度(attention degree)。Q和A都可以看作是一个[embed_dim, seq_len]的矩阵,显然U就是[embed_dim, embed_dim]的矩阵。当然,去掉U之后就是最简单的dot attention,即直接计算两个词向量的内积。
想一下,这里的U起到什么作用呢?虽然Q和A被embedding进了同一个向量空间,但是显然问题中的词分布与正确回答中的词分布是有显著差异的。比如回答中很少出现”多高“这个词,但是问题中出现就不稀奇了。因此Q的空间与A的空间其实是不一样的,直接进行距离计算会有问题。显然,在Q的空间和A的空间之间缺一个桥梁!而在小夕的《线性代数这样讲(一)》里提过,矩阵代表着线性映射,因此U的出现恰好可以完成两个分布之间的映射。
啰嗦一下,举个栗子。一方面,无attention的模型中,答案中的“1米”的词向量可能跟问题中的“多高”并没有很近的距离,但是U完全可以把“1米”相关的表示具体长度的语义映射到“多高”附近。另一方面,无attention的模型中,答案中的”多高“和问题中的”多高“肯定有非常近的距离(欧式距离为0),但是U完全可以将问题中的”多高“映射到其他词附近,导致其跟回答中的”多高“有很远的距离(即”多高“并不是”多高“的回答!)。所以说,U为答案空间和问题空间搭建了一座桥梁,使得两者的之间的距离计算变得有意义。看,attention一下子把QA匹配里的两个大问题都解决了。
然而,这种标准的词对齐的attention放在paraphrase任务里有什么意义呢?起码我很难想到它是无可取代的。文本1中的词与文本2中的词本身就是同一个空间里的,文本1与文本2里的同义词、近义词已经通过训练词向量获得了很近的距离,为什么要多此一举的加个attention呢?哪怕是为了针对OOV(未登陆词),那么在表示层多叠几层CNN或RNN就可以了哇(用OOV的上下文去描述它),也没有必要为此上一个attention吧,何况OOV在大部分情况下并不会有太大影响。
所以
那么对于paraphrase任务来说,怎样才看起来比较靠谱呢。我觉得那个知乎问答下最高票回答的第一大段还有斤木的回答其实是真正在点子上的。一方面要提高word-level embedding的质量和领域相关的词汇召回率,另一方面要将关注点放在捕捉syntactic level和semantic level的知识上,可以直接做POS、SRL等相关特性,要么就在大数据集上引导模型学习相关知识。
而在花式attention方面,推荐大家去关注机器阅读理解领域的前沿模型,在相似度计算方面,推荐大家关注检索式QA相关的前沿。当然,小夕也可能未来放出相关文章哦,限于篇幅,这里就不展开讲啦。
总结一下:
1、再次验证no-free-lunch定理,哪怕是两个看起来非常相似的任务,都有可能导致非常不同的解决方案。
2、对于检索式QA来说好好做attention是值得的。
3、对于paraphrase来说,别对别人家的attention抱那么大的期望,除非你能自己造一种task-specific的attention方式,并且你认为它捕获的信息无可替代。
4、在没有相应的理论分析和实验验证之前,不要盲目相信一个东西的性能。引用美妆届的一句经典:甲之蜜糖,乙之砒霜╮(╯▽╰)╭。
参考文献
[1] Feng M, Xiang B, Glass M R, et al. Applying deep learning to answer selection: A study and an open task[C]//Automatic Speech Recognition and Understanding (ASRU), 2015 IEEE Workshop on. IEEE, 2015: 813-820.
[2] dos Santos C N, Tan M, Xiang B, et al. Attentive pooling networks[J]. CoRR, abs/1602.03609, 2016, 2(3): 4
[3] https://engineering.quora.com/Semantic-Question-Matching-with-Deep-Learning
[4] Luong M T, Pham H, Manning C D. Effective approaches to attention-based neural machine translation[J]. arXiv preprint arXiv:1508.04025, 2015.
[5] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
哦对啦,「小公式」与「小算法」开通,欢迎顺路逛逛哦( ̄∇ ̄)




