文本分析 | 常用距离/相似度 一览
这个系列打算以文本相似度为切入点,逐步介绍一些文本分析的干货,包括分词、词频、词频向量、TF-IDF、文本匹配等等。
第一篇中,介绍了文本相似度是干什么的;
第二篇,介绍了如何量化两个文本,如何计算余弦相似度,穿插介绍了分词、词频、向量夹角余弦的概念。
其中具体如何计算,在这里复习:
度量两个文本的相似度,或者距离,可以有很多方法,余弦夹角只是一种。本文简单列了一下常用的距离。
需要注意的是,本文中列的方法,有的是距离,也就是指越小越相似,有的是相似度,值越大越相似。
在 Python 的距离包 pairwise_distances 中,统一处理成了距离,即都是值越小,则距离越小、越相似。在具体的介绍中,我会专门说明一下。
本文中统一用下面两个文本作为例子:
text1 = '上海市市级科技重大专项’
text2 = '上海市国家级科研重大项目'
将2个进行分词,选取词维度有:
(上海市, 市级, 国家级, 科技, 科研, 重大, 专项, 项目)
x = (1, 1, 0, 1, 0, 1, 1, 0)
y = (1, 0, 1, 0, 1, 1, 0, 1)
OK,下面结合这个例子,具体介绍下各种距离:
1、欧氏距离(Euclidean Distance)
(1)定义
欧氏距离是最常见的向量距离,定义为:
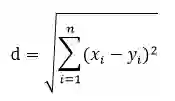
值越小越相似。
(2)实例计算
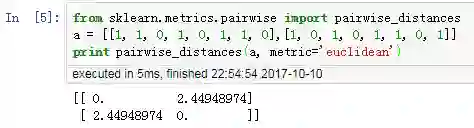
用 Python 验证,x 和 y 的欧氏距离为 = 2.45
2、曼哈顿距离(Manhattan Distance)
(1)定义
曼哈顿距离的定义为:
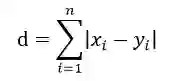
值越小越相似。
(2)实例计算
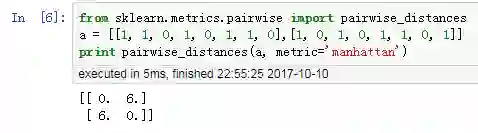
用 Python 验证,x 和 y 的曼哈顿距离为 = 6
3、闵科夫斯基距离(Minkowski Distance)
(1)定义
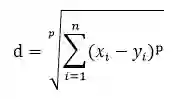
值越小越相似。
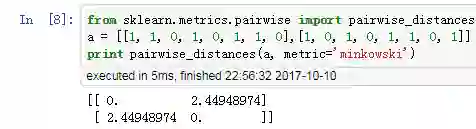
(2)实例计算
用 Python 验证,x 和 y 的闵科夫斯基距离为 = 2.45
4、马氏距离(Mahalanobis Distance)
(1)定义:
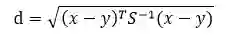
值越小越相似。
(2)实例计算
由于马氏距离需要计算向量x与y的协方差S,因此对数据量有一定要求,本例中数据量不足因此 Python 提示无法计算。
5、海明距离(Hamming Distance)
(1)定义
海明距离为两串向量中,对应元素不一样的个数,比如101010与101011的最后一位不一样,那么hamming distance即为1,,同理000与111的hamming为3。
但这没有考虑到向量的长度,如111111000与111111111的距离也是3,尤其是比较文本的相似时,这样的结果肯定不合理,因此我们可以用向量长度作为分母。Python 中的 hamming distance 即这么计算的。
海明距离也是值越小越相似。但除以长度之后的海明距离,最大值为1(完全不相似),最小值为0(完全一致)。
(2)实例计算
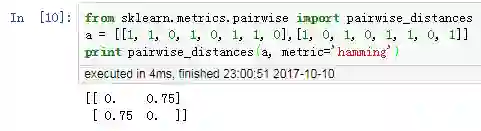
6、Jaccard 系数
(1)定义
Jaccard系数的原始定义为:
两个集合中,交集的个数/并集的个数。
比如本例中的两个文本:
text1 = '上海市市级科技重大专项’ → {上海市, 市级, 科技, 重大, 专项 }
text2 = '上海市国家级科研重大项目' → {上海市, 国家级, 科研, 重大, 项目}
交集有2个(上海市,重大),并集有8个。
因此Jaccard系数为:1/4。
转化成向量计算,其实跟 hamming 距离是一样的,都是对应元素相同的个数,除以向量的个数。
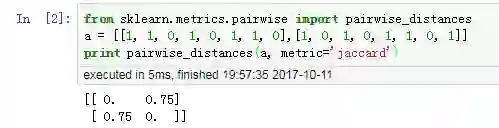
原始定义是相似度,即越大越相似,取值范围是 0~1(1=100%一致,0=完全不相似)。在 Python 中,需要统一转化成距离,即值越小月相似。因此 Python 中的定义为: 1 - Jaccard 系数。
(2)Python 验证
7、余弦夹角相似度(Cosine Similarity)
(1)定义
余弦夹角相似度之前专门说过(文本分析 | 词频与余弦相似度),在文本分析中,它是一个比较常用的衡量方法。
简单复习一下,有a、b两个向量,那么 cosine 相似度的原始定义为:
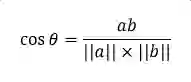
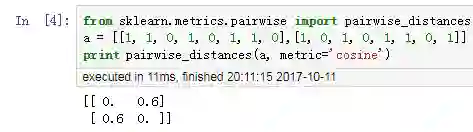
它本身是值越大越相似,取值范围是0~1(1=100%一致,0=完全不相似)。在 Python 中,需要转化成距离,即越小越相似。Python 中的定义为: 1 - cosine similarity
(2)Python 验证
8、切比雪夫距离(Chebyshev Distance )
(1)定义
切比雪夫距离的定义为:
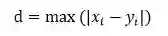
意思就是,x 和 y 两个向量,对应元素只差的最大值的绝对值。值越小越相似
本例中,最大值只可能是1了。
(2)Python 验证

pairwise_distances 包中还有很多距离:

感兴趣可以了解一下
http://scikit-learn.org/stable/modules/generated/sklearn.metrics.pairwise.pairwise_distances.html
更多 SQL 连载、Python 连载、SAS 教程 请关注 数说工作室
【统计师的 Python 系列】连载
第1天:谁来给我讲讲Python?
第2天:再接着介绍一下Python呗
第3天:Numpy你好
第4天:欢迎光临Pandas
第5天:Pandas,露两手
第6天:数据合并
第7天:数据清洗(1)
第8天:数据清洗(2)文本处理
第9天:正则表达式
第10天:数据聚合
第11天:class-类
【文本挖掘系列】连载
1、文本相似度思想
2、词频与余弦相似度算法
3、TF-IDF 治啰嗦利器
【分类战车SVM】系列
开题话
线性分类
最大间隔分类器
拉格朗日对偶问题
核函数
SMO算法
用Python做SVM模型
SAS系列,包括 【SAS IML系列】、【SAS 正则表达式系列】、【SAS 基础系列】
金融数据挖掘系列、量化投资系列、生物大数据系列 等等更多干货......



