推荐!【美国陆军战略项目年度报告】《人工智能(AI)用于多域作战(MDO)的指挥和控制(C2)》完整译文,美国陆军研究实验室

1. 引言
1.1 军队的相关性和问题领域
美国陆军目前还没有一个基于人工智能的、部分自主的任务指挥工具,在战术或作战层面上以高作战节奏(OPTEMPO)运作。通常情况下,生死攸关的决定是由少数人在时间限制下利用不完善的信息作出的。目前可供规划者使用的工具(如高级野战炮兵战术数据系统[AFATDS]、蓝色部队追踪器等)通常仅限于分析战场地形的基本决策辅助工具和记录决策的自动化工具。指挥官在向下级提供快速OPTEMPO指导时,会遇到信息过载。战斗损伤评估(BDA)很慢,而且不能与单位运动/传感器与射手的联系同步,也不允许利用优势窗口。行动方案(CoA)分析主要集中在对友军计划的评估上,很少强调对手的目标和能力的复杂性。
随着空间、网络电磁活动(CEMA)和机器人资产的加入,MDO成倍地增加了C2的复杂性,这可能会使OPTEMPO比过去更高。此外,人类指挥官使用目前可用的决策辅助工具来提供高度详细的指令将是难以解决的。有可靠的报告称,美国的同行和近邻竞争对手,特别是中国,正在大力追求人工智能在军事上的应用,包括指挥决策和军事推演(即兵棋推演)。因此,在追求人工智能C2系统的过程中,存在着很大的失败风险,只有不断地朝着这个目标前进,不断地努力实现一个能够在MDO中执行C2的人工智能系统,才能克服这个风险。
1.2 长期目标
到2035年,我们设想需要开发敏捷和适应性强的人工智能C2系统,用于复杂、高OPTEMPO、超活跃的MDO中的作战规划和决策支持。这些系统将不断整合未来战争的几个领域。设想中的系统将能够分析敌人的活动;不断地规划、准备、执行和评估战役,通过不断地感知、识别和快速利用新出现的优势窗口,使军队的能力得到快速反应。这些优势窗口将在不同梯队的MDO框架内的行动中出现,但识别和利用它们需要较少地依赖刻意的规划周期,而更多地依赖持续、综合的规划能力。启用人工智能的C2系统有可能在不同的梯队、领域和多个同时运作的资产之间快速同步采取多种行动,以利用优势窗口。部队将主要由机器人资产(地面、空中)组成,人工智能C2系统将收集和处理来自智能传感器和平台的数据,评估作战环境中的新趋势,并建议采取减少认知负担的行动,使人类指挥官能够快速有效地采取行动。启用人工智能的流程还将提供定量分析、预测分析和其他可供人类有效使用的突出数据。这最终将使美国陆军有能力在武装冲突期间,根据对敌人弱点的理解和详细的友军估计,重新分配、重组和使用能力,并将产生具体、详细的指令来控制自主资产。
DEVCOM陆军研究实验室在机器人学、自主性、人工智能和机器学习方面有积极的研究计划。本报告的作者领导了政府、学术界和工业界合作伙伴之间的大型合作机器人研究工作的研究和整合活动,在场景理解、人类与人工智能的合作、RL、多智能体强化学习和多智能体协作系统方面进行了开拓性的研究。此外,ARL还拥有广泛的基础设施来进行上述领域的研究。这包括用于机器人研究的地面和空中平台;用于场景驱动研究的机器人研究合作园区(R2C2),能够承载实时的、可扩展的、多领域的实验;旨在支持人工智能和机器学习应用的新兴要求的集装箱式超级计算机;这只是其中的几个例子。我们相信,这些专业知识和资源可以被用来建立一个成功的计划,将人工智能纳入C2应用。
1.3 DSI的目标
ARL主任战略倡议(DSI)计划是一个跨学科基础和应用研究的机制,成功的提案可以跨越科学和技术学科的界限。该计划确定了代表战略研究机会的主题领域,对陆军任务具有非常高的潜在回报,以扩大现有的计划或建立新的核心能力,并在这些领域建立内部的专业知识。
作为20财政年度授予的 "用于MDO C2的人工智能 "DSI项目的一部分,我们探索基于DRL的算法在多大程度上可用于估计红方部队的状态,评估红方和蓝方的战斗损失(损耗),预测红方的战略和即将展开的行动,并根据所有这些信息制定蓝方计划。这种方法有可能为蓝方部队产生新的计划,利用潜在的机会窗口,其速度比专家规划者快得多。最近,DRL在非结构化战略游戏中的成功提供了重要的暗示性证据,表明人工智能方法可能能够基本上 "从零开始 "发现适当的战术概念,并以高于人类的速度选择、应用和执行战略。
在这个DSI中,我们探索使用DRL在战斗行动前制定详细的计划,并在执行正在进行的行动中生成实时计划和建议。我们计划在两个关键领域推动技术水平的发展:1)构思、设计和实施基于DRL的智能体,以生成与专家计划员生成的计划一样好或更好的计划;2)将人类纳入指挥和学习回路,并评估这些人工智能-人类(人在回路中)的解决方案。在为这种人工智能支持的C2开发途径的同时,需要回答几个研究问题。在这个DSI中,我们试图回答三个具体问题:
DRL C2智能体的训练和数据要求是什么,以便准确和足够快地学习?
我们如何才能使DRL智能体具有通用性,以便根据人类专家的判断,特别是在以前未曾见过的细节被引入到一个情况中时,它们能够合理地执行?
在人工智能支持的C2系统中,人类的干预有什么影响?
该项目第一年的重点是开发研究的基本构件,包括:1)通过调整和使用基于《星际争霸II》和OpSim的环境来开发模拟能力和高级界面;2)开发执行C2功能的初始端到端人工智能;3)通过与高性能计算(HPC)环境整合来开发计算能力;4)初步确定数据量和训练要求。本报告提供了这些任务中每个任务的细节。
2. 实验能力
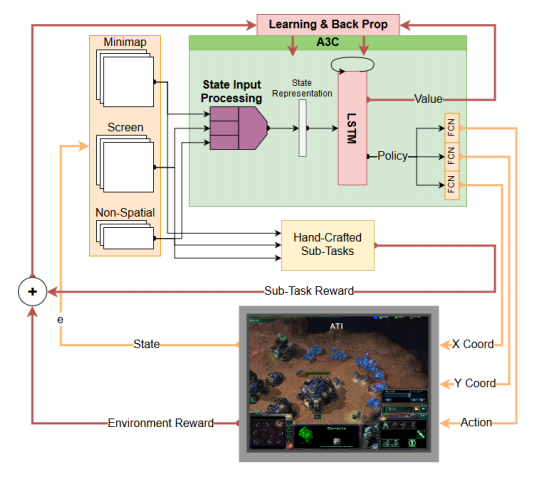
作为该项目的一部分,我们开发了C2模拟和实验能力,包括与基于DRL的人工智能算法和国防部高性能计算系统上的可扩展RL的接口的模拟战斗空间(图1)。我们使用两种模拟环境来生成C2场景:星际争霸II学习环境(SC2LE)29和OpSim。虎爪,一个由卓越机动中心(Fort Benning,Georgia)开发的场景,在模拟环境中生成了真实的战斗环境。最后,我们使用RLlib31,一个为RL提供可扩展软件基元的库,在HPC系统上扩展学习。
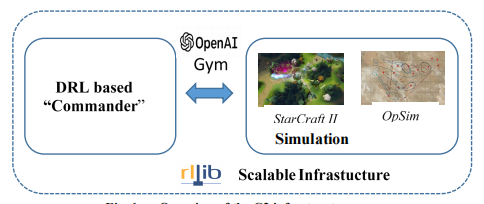
图1 C2基础设施概述
2.1 虎爪行动
虎爪行动(Tiger Claw)是一个预定义的战斗场景,由红军和蓝军组成,由乔治亚州本宁堡的上尉职业课程的军事主题专家(SME)开发。这个假想场景显示特遣部队(1-12 CAV)在区域内进攻,以夺取OBJ Lion,以便将师的决定性行动(DO)向东传递。特遣部队的目标是穿越Thar Thar Wadi,摧毁红色部队,并夺取OBJ Lion(图2)。特遣部队包括使用M1A2艾布拉姆斯的战斗装甲,使用布拉德利的步兵战车,野战炮和迫击炮,使用布拉德利的装甲侦察骑兵,战斗航空兵,防空兵和无人驾驶飞机。红军由装备BMP-2M的机械化步兵、装备T-90坦克的战斗装甲、野战榴弹炮、装备BMP-2M的装甲侦察骑兵、战斗航空兵、反装甲兵和战斗步兵组成。虎爪方案还包括由中小型军事专家制定的蓝军和红军的可能计划。这些计划是根据作战命令(OPORD)和相应的威胁战术,使用理论上的力量部署产生的。虎爪方案已被纳入OpSim和《星际争霸II》,并作为一个基准基线,用于比较不同的神经网络架构和奖励驱动属性。
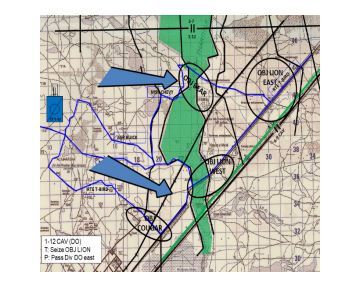
图2 TF 1-12 CAV在《虎爪》中的作战区域(AO)。
2.2 《星际争霸II》模拟环境
星际争霸II》是一个复杂的实时战略游戏,玩家要在高水平的经济决策和低水平的个人控制可能的数百个单位之间取得平衡,以压倒和击败对手的部队。星际争霸II》对人工智能有许多困难的挑战,使它成为MDO中C2的一个合适的模拟环境。例如,游戏有复杂的状态和行动空间,可以持续数万个时间步骤,实时选择数千个行动,并由于游戏的部分可观察性或 "战争迷雾 "而捕捉到不确定性。此外,该游戏具有可用于MDO模拟的异质资产、固有的C2架构、嵌入式军事(动能)目标,以及与更强大的模拟(例如,One Semi-Automated Force [OneSAF])相比,实施/修改的学习曲线较浅。DeepMind的SC2LE框架将暴雪娱乐公司的《星际争霸II》机器学习应用编程接口暴露为RL环境。这个工具提供了对《星际争霸II》和相关地图编辑器的访问,以及RL智能体与《星际争霸II》互动的接口,获得观察和发送行动。
作为DSI的一部分,一个SC2LE地图是根据Tiger Claw OPORD和支持文件开发的(图3)。通过重新绘制图标以纳入2525B军事符号和与虎爪计划相关的单位参数(武器、范围、比例),游戏被军事化。内部评分系统被重新使用,以计算RL的奖励函数,其中包括任务目标的收敛(穿越瓦迪),蓝色损耗的最小化,以及红色损耗的最大化。

图3 《星际争霸II》中的虎爪地图
专知便捷查看
便捷下载,请关注专知人工智能公众号(点击上方蓝色专知关注)
后台回复“A3C” 就可以获取《推荐!【美国陆军战略项目年度报告】《人工智能(AI)用于多域作战(MDO)的指挥和控制(C2)》完整译文,美国陆军研究实验室》 专知下载链接





