USB:首个将视觉、语言和音频分类任务进行统一的半监督分类学习基准
![]()
新智元报道

新智元报道
【新智元导读】微软亚洲研究院的研究员们联合西湖大学、东京工业大学、卡内基梅隆大学、马克斯-普朗克研究所等机构的科研人员提出了 Unified SSL Benchmark(USB):第一个将视觉、语言和音频分类任务进行统一的半监督分类学习基准。
当前,半监督学习的发展如火如荼。但是现有的半监督学习基准大多局限于计算机视觉分类任务,排除了对自然语言处理、音频处理等分类任务的一致和多样化评估。此外,大部分半监督论文由大型机构发表,学术界的实验室往往由于计算资源的限制而很难参与到推动该领域的发展中。
为此,微软亚洲研究院的研究员们联合西湖大学、东京工业大学、卡内基梅隆大学、马克斯-普朗克研究所等机构的科研人员提出了 Unified SSL Benchmark(USB):第一个将视觉、语言和音频分类任务进行统一的半监督分类学习基准。
该论文不仅引入了更多样化的应用领域,还首次利用视觉预训练模型大大缩减了半监督算法的验证时间,使得半监督研究对研究者,特别是小研究团体更加友好。相关论文已被国际人工智能领域顶级学术大会 NeurIPS 2022 接收。

代码链接:https://github.com/microsoft/Semi-supervised-learning
监督学习通过构建模型来拟合有标记数据,当使用监督学习 (supervised learning)对大量高质量的标记数据(labeled data)进行训练时,神经网络模型会产生有竞争力的结果。
例如,据 Paperswithcode 网站统计,在 ImageNet 这一百万量级的数据集上,传统的监督学习方法可以达到超过88%的准确率。然而,获取大量有标签的数据往往费时费力。
为了缓解对标注数据的依赖,半监督学习(semi-supervised learning/SSL)致力于在仅有少量的标注数据时利用大量无标签数据(unlabeled data)来提升模型的泛化性。半监督学习亦是机器学习的重要主题之一。深度学习之前,这一领域的研究者们提出了诸如半监督支持向量机、熵正则化、协同训练等经典算法。
深度半监督学习
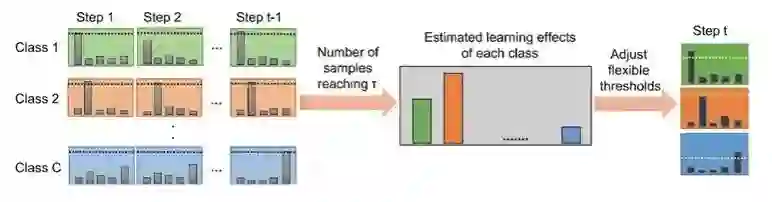
当前半监督学习代码库存在的问题与挑战
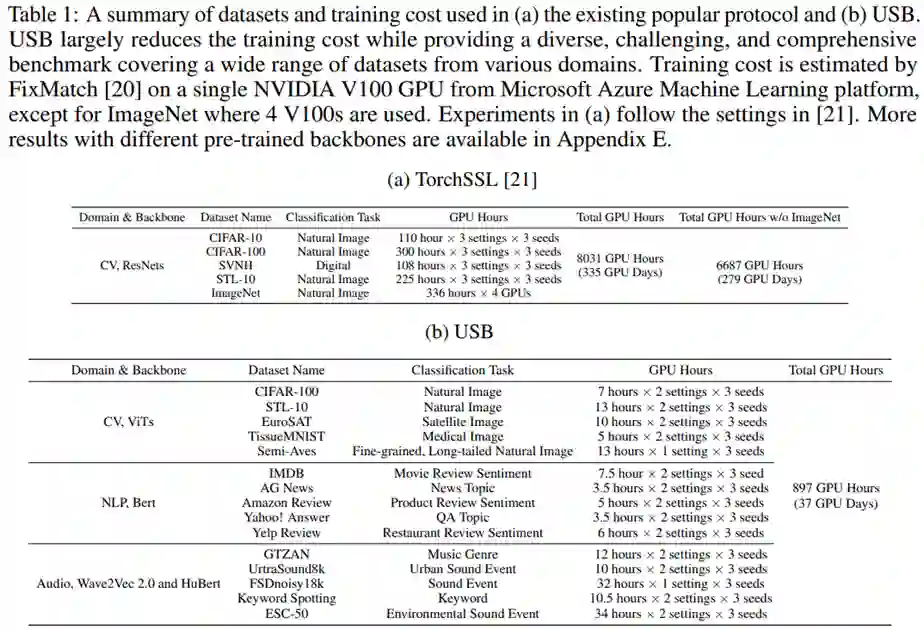
USB:任务多样化且对研究者更友好的新基准库
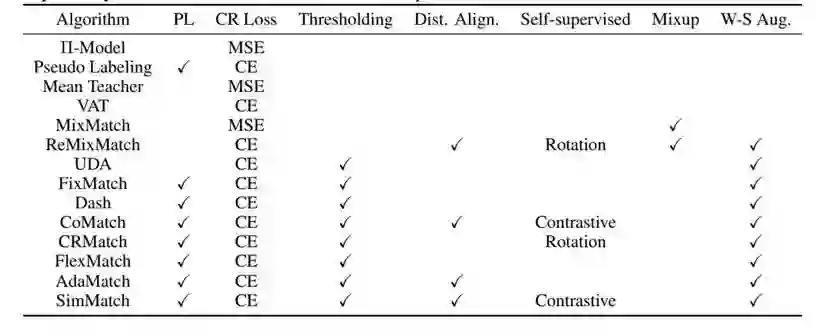
USB 提供的解决方案
参考资料:
[1]https://ai.googleblog.com/2021/07/from-vision-to-language-semi-supervised.html
[2] Kihyuk Sohn, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raffel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Advances in Neural Information Processing Systems, 33:596–608, 2020.
[3] Bowen Zhang, Yidong Wang, Wenxin Hou, Hao Wu, Jindong Wang, Manabu Okumura, and Takahiro Shinozaki. Flexmatch: Boosting semi-supervised learning with curriculum pseudo labeling. Advances in Neural Information Processing Systems, 34, 2021.
[4] TorchSSL: https://github.com/TorchSSL/TorchSSL





