NL2SQL:弱监督学习与有监督学习完成进阶之路

Outline
NL2SQL 任务和 WikiSQL 数据集介绍
弱监督学习下 NL2SQL 解决方案
有监督学习下 NL2SQL 解决方案
追一科技 NL2SQL 天池挑战赛
NL2SQL任务和WikiSQL数据集介绍
近年来,NLP 的突破,带来了一些创新型研究机会,NL2SQL 正是其中之一,在学界与工业界获得了广泛关注。Salesforce、斯坦福、耶鲁等机构提出了 WikiSQL、WikiTableQuestions、Spider、SParC 等大规模数据集,并得到多次评测结果的提交。以 WikiSQL 为例,目前在排行榜上有多达 19 次的评测结果的提交。
顾名思义,NL2SQL 就是将自然语言转化为 SQL 语句的一项任务。在中文领域,NL2SQL 研究也越来越受到瞩目。随着追一科技在天池平台发起首届中文 NL2SQL 比赛,(比赛地址https://tianchi.aliyun.com/markets/tianchi/zhuiyi_cn),第一个中文 NL2SQL 数据集也将横空出世。那么,这个任务,有哪些解决方案?尤其是在挑战赛这种高手对决的情况下,如何实现最优解?
WikiSQL 是目前规模最大的 NL2SQL 数据集,有不少的借鉴和优化空间。在这篇文章中,我们将帮助选手简要梳理一下目前在 WikiSQL 数据集上的弱监督学习以及有监督学习的方案。
弱监督学习下NL2SQL解决方案
众所周知,使用机器学习算法少不了训练数据的参与。对于 NL2SQL 任务,我们希望实现从自然语言问句到 SQL 程序语句的转换。很容易想到,我们可以使用“自然语言语句-SQL”作为训练数据来训练模型。但“自然语言语句-SQL”这样的训练数据难以获得或标注,使数据的前期准备工作变得繁重困难。使用弱监督学习方式意味着我们可以使用“自然语言语句-SQL 的执行结果”取代“自然语言语句-SQL”作为训练数据更新模型参数。相比之下,这样的训练数据更容易获得,可以将研究人员从训练数据收集的繁重工作解放出来。
针对弱监督学习方法解决 NL2SQL 问题,WikiSQL 提供了专门的榜单。目前榜单上有两种弱监督学习的方案,分别是 MAPO 和 MeRL,本文将对这两种方法对应的论文进行解析。
Memory Augmented Policy Optimization (MAPO)

MAPO 算法是在论文 Memory Augmented Policy Optimization for Program Synthesis and Semantic Parsing 中提出的,发表于 2018 年的 NIPS 会议。论文中对 MAPO 算法的设计思路进行了详细的介绍,并且对 MAPO 算法在 WikiSQL 上的应用进行了详尽的分析。
MAPO 是一种基于弱监督强化学习的方法。在论文中,作者根据 NL2SQL 任务的基本构成和强化学习的基本元素,将 NL2SQL 任务转化为一个强化学习任务。在 MAPO 中,强化学习的状态 x 被看做输入的自然语言问题和其对应的环境(一个解释器或者数据库),强化学习的动作空间 A 被看做当前自然语言问题下所有可能产生的程序集合,而每一条强化学习轨迹的动作序列 a 对应着每一个可能的程序。
MAPO 算法的目的是生成一个策略函数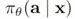
由此可知,算法的关键即是对策略函数的训练。在 MAPO 中,作者使用了一个 seq2seq 模型来拟合策略函数,针对策略函数的训练也就等同于对这个 seq2seq 模型进行训练。
值得注意的是,在强化学习中,策略函数的参数更新与深度神经网络有所不同,并非是基于损失函数,而是基于期望回报进行,参数的更新是朝着最大化期望回报的方向进行。期望回报可以由 Reward 函数给出。
由于我们的任务是生成程序语句,因此我们可以很方便地将生成的程序运行在真实环境中,并将结果与弱监督训练数据的 label 对比,从而得到 0-1 二值 Reward 函数,这体现了强化学习的核心思想,即通过与环境交互的方式来纠正智能体的行为,从而达到“学习”的效果。
根据以上所述的强化学习思想,在具体的实施中,MAPO 提出了如下的创新方案。首先,为了提高训练的效率,MAPO 算法将采样到的高回报程序存到一个 Memory Buffer 中,在对策略函数拟合网络进行训练时,最大化期望回报的目标函数分为两个部分,一个是 Memory Buffer 中采样程序的期望回报,另一部分是Buffer之外的采样程序期望回报,如下图所示。

其次,策略梯度类强化学习算法可能会被“冷启动”困扰,也就是说在训练开始时,会给高回报采样程序分配较低概率,从而导致训练参数更新缓慢,拉低整体训练效率,MAPO 算法针对此问题给出了名为 Memory Weight Clipping 的解决方案,也就是以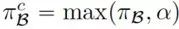
,通过在训练初期强制提高 memory weight 大小的方式提高训练效率,在训练轮数变多后,此 max 函数将失去作用,因此不会给模型带来 bias。
接着,为了高效的产生高回报采样程序,避免出现重复采样导致计算资源的浪费,MAPO 引入了一个 Buffer 用来记录已经采样过得程序序列(完整和非完整),每次进行新的采样时都会对此 Buffer 进行访问。
最后,整个 MAPO 算法的计算瓶颈在于对每个自然语言问句采样新程序的过程,针对这个问题 MAPO 算法采用了分布式采样的方案,引入了 Actor-Learner 框架。Actor 有很多个,负责采样产生新程序和与环境交互得到该程序对应的 Reward,Learner 只有一个,用来根据采样结果对策略函数拟合网络进行训练,更新其参数。
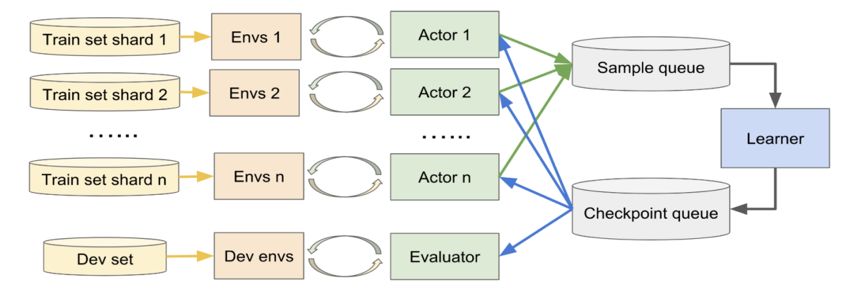
MAPO 算法的整体表述可由下图得到。

作者将 MAPO 应用到了 WikiSQL 数据集上,对于 WikiSQL 数据及上的每一个样本,都产生 1000 个采样程序,Memory Buffer 中储存 5 个高回报样本,在策略函数拟合网络中应用 GloVe embeddings,LSTM 隐藏单元为 200 个,训练 15000 步。
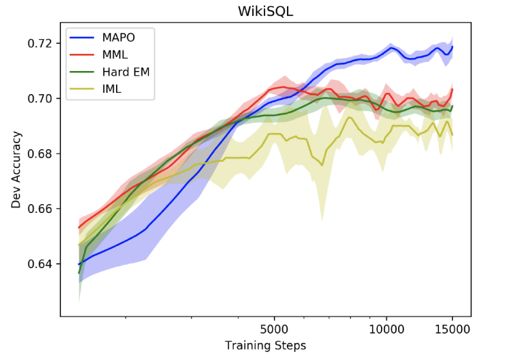
MAPO 在 WikiSQL 上的表现超越了很多有监督学习的算法,如下图所示。
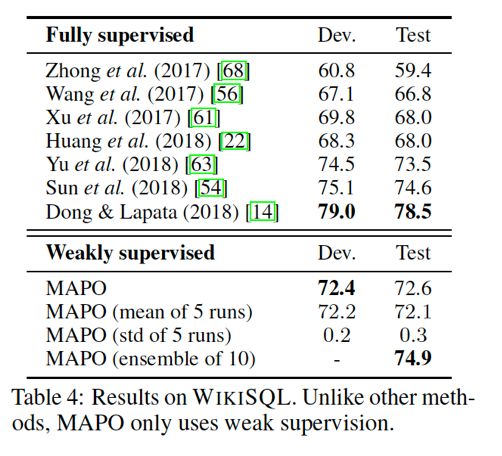
作者对 MAPO 在 WikiSQL 上进行应用时的超参数设置很多是受运算环境所限,因此如果有更强的运算能力,加大 MAPO 采样数、训练步数、Memory Buffer 记录数等超参数,有可能准确率会进一步提高。
Meta Reward Learning (MeRL)

由 MAPO 算法可知,将强化学习算法应用在 NL2SQL 可以得到比较理想的结果,但在应用过程中也会产生两方面的典型问题。
第一点是 Sparse Rewards,在 MAPO 中,只有生成的采样程序运行结果与训练数据 label 一致,回报函数才会返回 1,否则均为 0,而在采样过程中,生成的高回报的采样程序数量非常稀少,因此会遇到回报稀疏的问题。
第二点是 Underspecified Rewards,在 NL2SQL 这种回报函数是二值函数的问题中,很容易会出现偶然的情况得到高回报,如果能有效地对这种偶然情况进行处理,算法的效果将会进一步提高。
针对这两点,论文 Learning to Generalize from Sparse and Underspecified Rewards 提出了相应的解决方案。作者基于 MAPO 提出了其改进方案 MAPOX(MAPOeXploratory)用于解决在 Sparse Rewards 情况下高效探索样本空间的问题,并提出了 MeRL(Meta Reward-Learning)用来处理虚假的高回报样本程序。
定义目标函数的形式如下图所示,这种目标函数被称为 IML(Iterative Maximum Likelihood)。
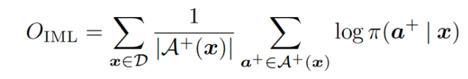
IML 目标函数和 MAPO 目标函数都可以被通过 KL 散度的方式进行解释,并且正好相反。IML 目标函数可以看做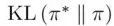
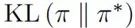
作者推断,使用 IML 目标函数将会鼓励更多的探索行为,并在 WikiSQL 上进行了实验,如下图所示,IML 比 MAPO 可以采样到更多的高回报样本。
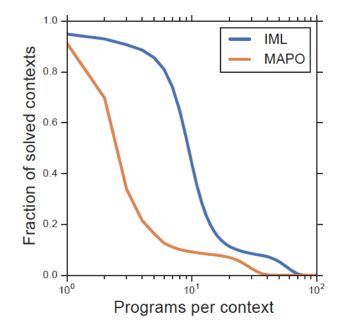
基于这样的观察,作者设计了 MAPOX,MAPO 和 MAPOX 关键的不同之处是对 Memory Buffer 中样本程序的初始化方式。除了使用随机搜索的方式产生 Buffer 中的初始样本外,同时会使用 IML 来进行样本程序的生成。
对于 Underspecified Rewards,作者提出了 MeRL,具体做法是学习一个辅助 reward function,通过这个函数利用样本级别特征来对高回报样本进行评估,样本级别特征是指样本程序长度等特征。对于一个给定的自然语言语句 x,辅助 reward function 可用下式表示。
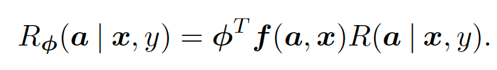
其中,R 为 underspecified rewards,f 表示样本级特征函数,Φ 是权重。这个权重是很难通过人工的方式进行调参的,因此解决方案是对其进行训练,训练的方式就是 MeRL。

算法中辅助回报函数的参数是和策略网络参数一起更新的,辅助回报函数的优化目标函数为:
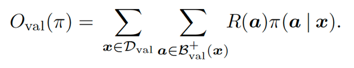
由验证集中的样本给出,从而可以分辨虚假的高回报样本。
作者在 WikiSQL 数据集上对 MAPOI、MAPOX、MAPOX+MeRL 等多种算法进行了测试,结果如下所示。
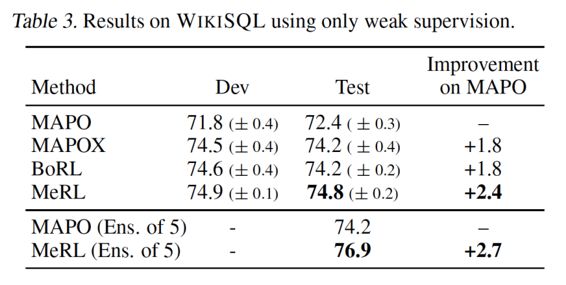
由表中的实验结果可以看到,将 MAPO 与 MeRL 结合,可以显著提升 MAPO 算法在 WikiSQL 数据集上的训练准确率。
有监督学习下NL2SQL解决方案
弱监督学习具有训练数据更易于收集、数据标注成本低等优势。但现状下不可否认的是,如果有足够多“自然语言语句-SQL”这样的有标签训练数据,有监督学习算法的效果会更胜一筹。
WikiSQL 数据集提供了 8w 多条有标签数据,足以满足目前的数据驱动型算法对数据量的需求。在目前的榜单上,效果最好的模型是 SQLova 和 X-SQL,它们在测试集上分别可以达到 89.6% 和 91.8% 的执行准确率。接下来本文将对这两种方法的原理和论文进行解析。
SQLova
SQLova 是韩国 Naver 提出的一种模型,全名为 Search & QLova,是作者们所在部门的名称。此方案是于 SQLNet 的基础上,在模型结构方面做了一些改进而得到的,并没有提出一些创新性的解决方案。在具体介绍 SQLova 之前,我们先简单介绍一下原型方案 SQLNet。
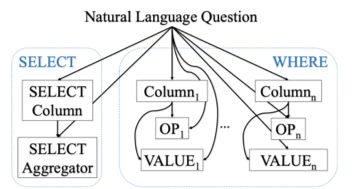
SQLNet 是 WikiSQL 数据集上的一个 baseline 模型。根据 WikiSQL 数据集中 SQL 语句的特征,预测 SQL 这一任务被 SQLNet 解耦为了 6 个子任务,包括选择哪一列的 Select-Column、使用什么聚合函数的 Select-Aggregation、有几个条件的 Where-Number、筛选条件是针对哪几列的 Where-Column、各个条件的操作符 Where-Operator 以及各个条件的条件值 Where-Value。
同时,每个子任务按照各自的任务目标设计了不同输出层,例如,Select-Column 的输出层是一个对所有列进行的单分类任务,Select-Aggregation 的输出层是对包括 MAX、MIN、AVG、SUM、COUNT 和空函数进行的单分类任务。不同子任务的分工可以参照下图来理解。

同时,根据数据集中的数据特征以及编写 SQL 时的先后顺序,各个子任务之间设计了一种如下图所示的依赖关系。这样的依赖关系可以一定程度上利用已预测好的任务来帮助下游任务更好地预测。
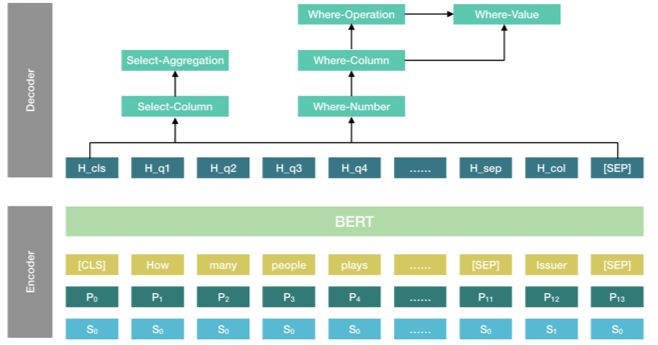
在理解了这种解耦任务的做法后,我们再回过头来看 SQLova。SQLova 继承了 SQLNet 任务解耦的思路,同样使用 6 个子任务来预测 SQL。不同之处在于,SQLova 使用了 BERT 来作为模型的输入表达层,代替了词向量。
为了让自然语言问句与表结构更好地结合,模型将自然语言问句与列名一并作为输入进行编码。同时,模型在拼接输入时采用了不同的 Segmentation Embedding 来让 BERT 可以区分问题和列名。
除此以外,SQLova 在下游的子模型中做了一些细小的调优,比如 SQLNet 在预测 Where-Value 时,只采用了 Where-Column 特征来作为额外输入,而 SQLova 额外采用了 Where-Operator 的特征一并作为输入;SQLNet 在结合自然语言问句与表格列名的特征时采用了相加,而 SQLova 则采用了拼接等等诸如此类的细小改动。
X-SQL
X-SQL 是微软 Dynamics 365 提出一种方案。这个方案同样继承了解耦任务的思路,将预测 SQL 分解为 6 个子任务。但不同于 SQLova,X-SQL 引入了更多创新性的一些改进,主要包括以下几个方面。
首先,X-SQL 使用了 MT-DNN 来作为编码层,代替了 SQLova 中使用的 BERT,因为 MT-DNN 在很多其它自然语言处理的下游任务上取得了比 BERT 更好的效果。但因为作者并没有提供对比实验,所以 MT-DNN 可以比 BERT 带来多少的提升就不得而知。
其次,X-SQL 在 SQLova 中原有的 Question Segmentation 和 Column Segmentation 的基础上拓展为 Question、Categorical Column、Numerical Column 以及 Empty Column 这四种 Segmentation Embedding,分别用来作为自然语言问句、文本类型的列、数字类型的列以及空列的相应输入。通过引入更多的分类表达,可以让模型得以区分数字与文本类型的列,进而更好地生成 SQL。
最后,在输出层与损失函数部分,Where-Column 的损失函数被定义为了 KL 散度。并且,借助之前提到的引入的特殊列 [EMPTY],如果模型在预测 Where-Column 时,分数最高的列是 [EMPTY],那么就无视 Where-Number 所得到的预测结果,判断 SQL 语句为没有条件。
通过这些输入与结构上的优化,X-SQL 可以在 WikiSQL 的测试集上取得 86.0% 的 Logic Form 准确率和 91.8% 的 Execution 准确率。
缺点与不足
我们可以看到,简单地通过 BERT、MT-DNN 这类预训练神器的加持,原有的思路就可以在 WikiSQL 取得非常显著的提升,达到 90% 左右的执行准确率。可见,这种借助解耦任务的解决思路在 SQL 语法并不复杂的 WikiSQL 数据集上可以取得较好的效果。
但如果数据集较为复杂时,这种思路便不再奏效。比如另一个代表性的大规模有标签数据集 Spider,其包含的 SQL 语法覆盖了排序、聚组、多表联合查询、嵌套查询等复杂语法。
其中的方案之一,SyntaxSQLNet 也采取了类似于 SQLNet 的思路,将预测 SQL 的任务从语法上进行解耦,按照 SQL 语句中不同字符的不同类别分组,来进行 SQL 的预测。这样的思路在 Spider 上并没有取得较好的效果,只取得了 19.7 的准确率。
追一科技NL2SQL天池挑战赛
分享了上面两种解决方案,各种优势不足,相信大家对 NL2SQL 任务,也有了更加清晰的认知和思路。当然,从入门到进阶,甚至成为高手,还需要不断的修炼。
目前,追一科技正在天池平台上举办首届 NL2SQL 比赛。比赛中提供了约 4,500 张表格,以及 50,000 条基于这些表格标注的自然语言语句与 SQL。如果在 NL2SQL 上做好了准备,这将是一次难得的晋级和对抗机会。
比赛将于 6 月 24 日进入初赛阶段,欢迎上场。
点击阅读原文,进入比赛报名链接:
https://tianchi.aliyun.com/markets/tianchi/zhuiyi_cn

点击以下标题查看往期内容推荐:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 报名参赛




