从视觉到语言:半监督式学习的大规模实际运用


发布人:Google Research 研究员 Thang Luong 和 Google 搜索高级软件工程师 Jingcao Hu
监督式学习 (Supervised Learning),即使用已知的结果数据(即标签数据)来训练预测模型的机器学习任务。由于它执行起来较为简单,通常是行业内的首选方法。但是,监督式学习需要准确添加标签数据,而收集这些数据往往会耗费大量人力。此外,模型效率会随着架构、算法和硬件 (GPU/TPU) 的升级而提高,所以通过训练大型模型来取得更好的质量会更加容易实现。但同时这也需要更多标签数据来确保这种进步。
大型模型
https://arxiv.org/abs/2006.16668
为缓解数据采集难题,半监督式学习 (Semi-supervised Learning)(一种将少量标签数据与大量无标签数据相结合的机器学习范式)近期在 UDA、SimCLR 和其他众多方法中取得成功。在之前的工作中,我们首次展示了一种半监督式学习方法,即 Noisy Student。该方法可通过利用更多无标签示例,在 ImageNet 上达到了目前最佳的 (SOTA) 性能。
Noisy Student
https://arxiv.org/abs/1911.04252
受到这些成果的启发,我们今天十分激动地推出半监督式蒸馏 (SSD)。这是简化版的 Noisy Student,它能够展示其在语言领域的成功应用。我们在 Google 搜索的情境下将 SSD 应用于语言理解,成功地实现了性能上的大幅提升。这是第一次在如此大规模的数据上成功应用半监督学习的实例,并展示了这种方法对生产级系统的潜在影响。

在开发 Noisy Student 之前,我们已经开展了大量有关半监督式学习的研究。然而,尽管有这些大量的研究,这类系统通常只在低数据量环境中运行良好,例如 CIFAR (CIFAR-10)、SVHN 和 10% ImageNet。当存在大量标签数据时,此类模型无法与全监督式学习系统竞争。因此半监督式方法无法适用于生产环境中,如搜索引擎和自动驾驶汽车等重要应用。这一缺陷促使我们开发了 Noisy Student 训练,这种半监督式学习方法目前在高数据量环境中运行良好。比如它在使用了 1.3 亿张额外无标签图像的 ImageNet 上达到目前最佳 (SOTA) 的准确性。
Noisy Student 训练分为 4 个简单步骤:
1. 使用标签数据训练一个分类器(教师)。
2. 教师在一个更大的无标签数据集上推断出伪标签。
3. 利用合并的标签数据和伪标签数据训练一个更大的分类器,同时加入噪声(有噪声的学生)。
4. (可选)回到第 2 步,学生可以用作新教师。
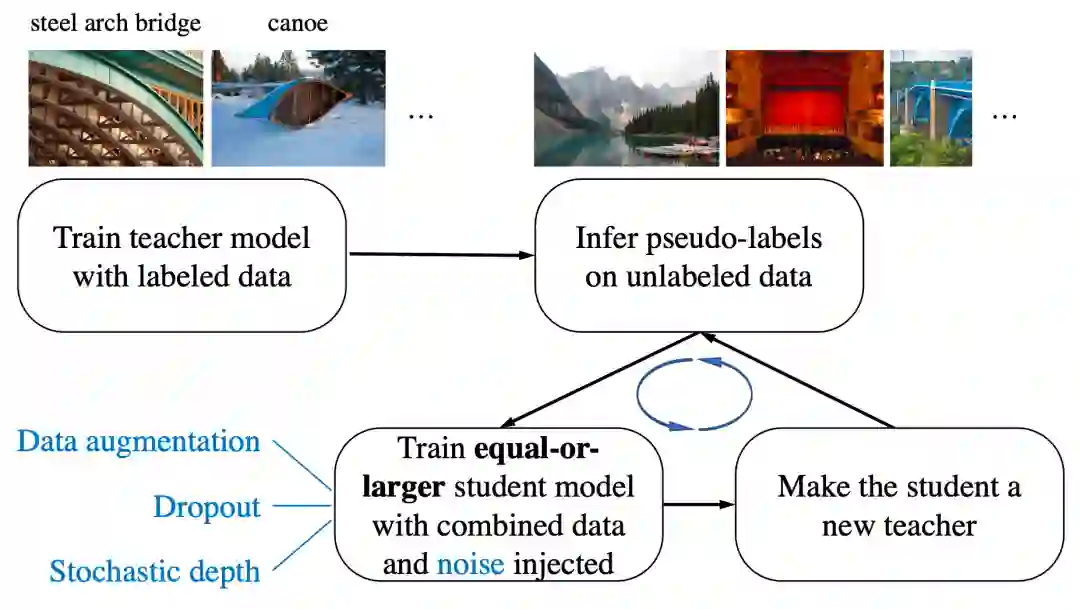
通过这四个简单步骤进行 Noisy Student 训练的图示。我们使用两种类型的噪声:模型噪声 (Dropout、Stochastic Depth) 和输入噪声(数据增强,如 RandAugment)
我们可以把 Noisy Student 看作一种自训练的形式,因为该模型会生成伪标签,然后利用这些伪标签重新训练自己以提高性能。Noisy Student 训练一个令人惊叹的特性是,训练后的模型在没有针对性优化的稳健性测试集上效果非常好,其中包括 ImageNet-A、ImageNet-C 和 ImageNet-P。我们假设在训练过程中加入的噪声不仅有助于学习,还能提高模型的稳定性。
ImageNet-A
https://arxiv.org/abs/1907.07174
ImageNet-C 和 ImageNet-P
https://arxiv.org/abs/1903.12261

被基准模型错误分类,但被 Noisy Student 正确分类的图像示例。左:来自 ImageNet-A 的未修改图像。中和右:添加了噪声的图像,选自 ImageNet-C。要查看更多包含 ImageNet-P 的示例,请参阅此论文
论文
https://arxiv.org/abs/1911.04252
Noisy Student 类似于知识蒸馏,它是将知识从一个大模型(即教师)转移到一个小模型(学生)的过程。蒸馏的目标是通过提高速度来构建能在生产环境中快速运行,且质量不比教师差得很多模型。蒸馏最简单的设置是仅涉及一个教师,并使用相同的数据。但在实践中,可以为学生使用多个教师或单独的数据集。
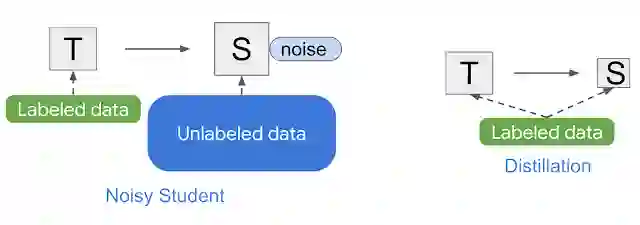
Noisy Student 和知识蒸馏的简图
知识蒸馏
https://arxiv.org/abs/1503.02531
不同于 Noisy Student 的是,知识蒸馏在训练过程中不添加噪音(例如数据增强或模型正则化),所涉及的学生模型通常较小。相比之下,我们可以把 Noisy Student 看作是“知识扩展”的过程。
训练生产模型的另一个策略是两次应用 Noisy Student 训练。首先得到一个较大的教师模型 T',然后得出一个较小的学生 S。这种方法产生的模型比用监督式学习训练或单独用 Noisy Student 训练得出的模型质量要高。具体来说,当应用于视觉领域的 EfficientNet 模型系列(从 5.3M 参数的 EfficientNet-B0 到 66M 参数的 EfficientNet-B7)时,这种策略在每种给定的模型大小上都取得了更好的性能(详见 Noisy Student 论文的表 9)。
Noisy Student 训练需要数据的增强,例如通过 RandAugment(用于视觉)或 SpecAugment(用于语音),才能有很好的性能。但在某些,如自然语言处理的应用中,这种类型的噪声输入并不容易获得。所以对于这些应用,Noisy Student 训练可简化为没有噪声。在这种情况下,上述两阶段的过程就变成了一种更简单的方法,我们称之为半监督式蒸馏 (SSD)。首先,教师模型在无标记数据集上推断出伪标签,然后我们从中训练一个新的教师模型 (T'),其规模与原教师模型相当或比它更大。这一步本质上是自我训练,然后再进行知识蒸馏,产生一个较小的学生模型用于生产。
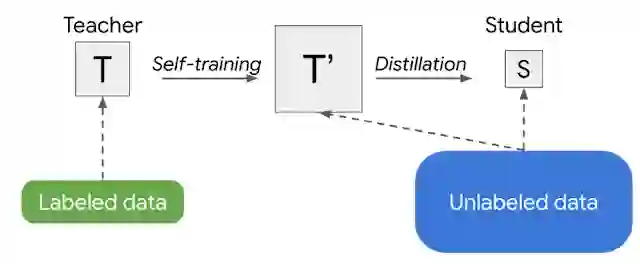
半监督式蒸馏 (SSD) 的图示,这是一个 2 阶段过程,在蒸馏产生学生 (S) 之前,自训练一个规模相当或更大的教师 (T')
RandAugment
https://arxiv.org/abs/1909.13719
SpecAugment
https://arxiv.org/abs/1904.08779
在视觉领域获得成功后,按照逻辑应在语言理解领域(如 Google 搜索)进行应用,以便对用户产生更广泛的影响。在这种情况下,我们专注于 Google 搜索中的一个重要排名组件,该组件基于 BERT 构建,以更好地理解语言。事实证明,SSD 非常适合这项任务。同时,将 SSD 应用于排名组件,可以更好地理解候选搜索结果与查询的相关性,这是 2020 年 Google 搜索中各项顶级内容发布的、最显著的性能提升之一。下面是一个与查询相关的例子,它表明经改进后的模型,可以展示出更好的语言理解能力。
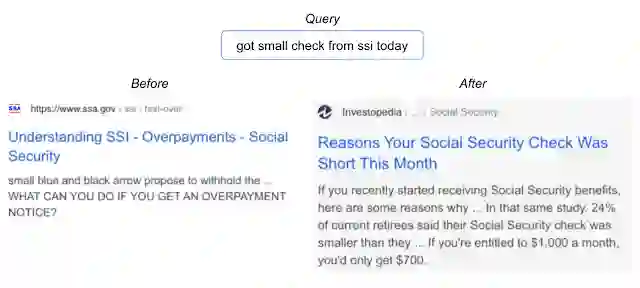
随着 SSD 的实施,Google 搜索能够找出与用户查询更相关的文件
通过展示半监督式蒸馏 (SSD) 在 Google 搜索的生产级设置中成功应用的实例,我们相信 SSD 能够对行业内机器学习的使用范围产生持续性影响,从以监督式学习为主变成以半监督式学习为主。尽管我们的结果证明了它的潜力,但现实世界往往更复杂,如何在其中有效地利用无标签示例,并将其应用于各个领域,这一问题仍需要进行许多研究。
Zhenshuai Ding、Yanping Huang、Elizabeth Tucker、Hai Qian 和 Steve He 为此次成功发布做出了巨大贡献。本项目的成功离不开 Google Brain 和 Google 搜索团队成员的贡献:Shuyuan Zhang、Rohan Anil、Zhifeng Chen、Rigel Swavely、Chris Waterson、Avinash Atreya。感谢 Qizhe Xie 和 Zihang Dai 为工作提供的反馈。另外还要感谢领导层 Quoc Le、Yonghui Wu、Sundeep Tirumalareddy、Alexander Grushetsky、Pandu Nayak 提供的支持。

推荐阅读



点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看


