赛尔原创@ACL Findings | 任务共舞,小样本场景下的多任务联合学习方法初探
论文名称:Learning to BridgeMetric Spaces: Few-shot Joint Learning of Intent Detection and Slot Filling 论 文 作 者 :侯宇泰,赖永魁,陈成,车万翔,刘挺 原 创 作 者 :侯宇泰 论 文 链 接 :https://arxiv.org/abs/2106.07343 代码链接:https://github.com/AtmaHou/FewShotJoint 转 载 须 标 注 出 处 : 哈 工 大 S C I R
1 简介
在本文中,我们以对话语言理解为切入点,研究了Few-shot情景下的联合学习(Joint-Learning)问题。现有的小样本模型往往每次只学习单一任务 [1,2]。然而,真实应用场景常常由多个彼此相关的任务组成 [3,4]。例如图1所示,对话语言的理解包含两个紧密相关的任务,即意图检测和槽位填充,并且常常受益于联合学习这两个任务 [5,6]。这种联合学习场景需要全新的小样本学习技术:从仅有的几个示例中捕获任务关系,并联合地学习多个任务。
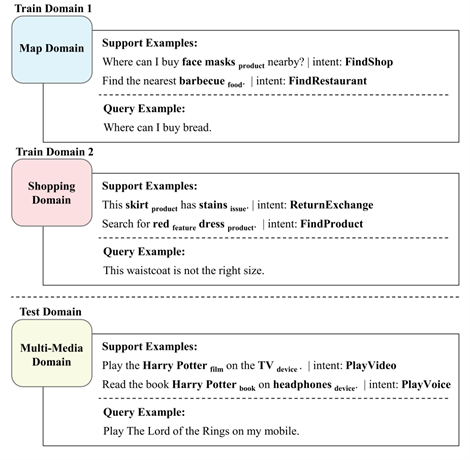
图1 小样本情景下的联合对话理解
然而,简单的结合小样本学习和联合学习的方法并不能达到目的,甚至可能会导致性能下降。这是因为联合学习多个任务需要从数据中建模多个任务之间关系(通常是跨任务标签间的依赖关系),而小样本下的联合学习面临两方面的独特挑战:
(1)一方面,从仅有的少量样本中无法学习具有足够泛化性的任务关系。
(2)另一方面,不同领域任务和标签都不同,任务联系也因而完全不同,导致无法直接从富数据领域迁移任务联系到未见的小样本领域。
为了解决上述问题,我们提出了一种基于相似度的Few-shot学习方案,称为“ Contrastive Prototype Merging Network(ConProm 共舞)”。如图2所示,该模型在数据丰富的领域上学习如何动态地桥接不同任务(意图识别(intent recognition)和槽位填充(slot filling))的度量空间,然后在桥接后的度量空间上联合地优化两个任务。在两个公共数据集Snips和FewJoint上进行的实验表明,我们的模型在显著优于最强的基线模型(baseline)。两个数据集上1-样本设置(1 shot)结果上各提升约10个点。
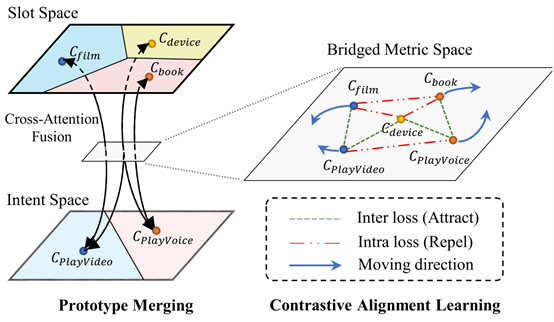
图2 ConProm “共舞”模型架构图
2 方法
2.1 背景:基于度量学习的小样本方法
目前,小样本学习的一个主流研究方向是基于度量学习的方法,在各种图像和自然学习的基准测试(benchmark)中,基于度量学习的方法也屡屡夺魁。因此,本文主要基于度量学习的研究脉络探索解决方案。如图3所示,基于度量的小样本学习方法首先学习一个领域通用的度量空间,然后在目标领域根据标签和标签的相似度判断样本的类别。这种方法属于非参数学习因而天然能缓解下游任务微调(fine-tuning)造成的过拟合问题。
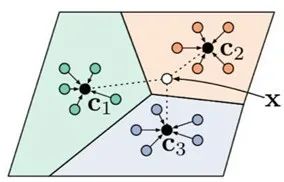
图3 基于度量学习的小样本方法
2.2 Contrastive Prototype Merging Network(ConProm 共舞模型)
ConProm 模型包含两个主要相辅相成的步骤:
(1)原型融合(Prototype Merging),动态连接联合学习任务的度量空间。
(2)比较对齐学习(Contrastive Alignment Learning),在连接后的度量空间联合优化多个任务。
这样,我们可以达到如下两个目的:
(1)我们可以避免直接学习小样本中稀疏意图-槽位关系。
(2)我们可以转而迁移连接度量空间的能力,从而间接达到迁移建模任务间联系的目的。
2.3 原型融合
(1)动机:动态连接联合学习任务的度量空间。
(2)解决方法:如图4左半所示,我们通过连接不同任务的类别表示来桥接不同任务的度量空间。这里我们连接意图类别和相关的槽位类别的表示。
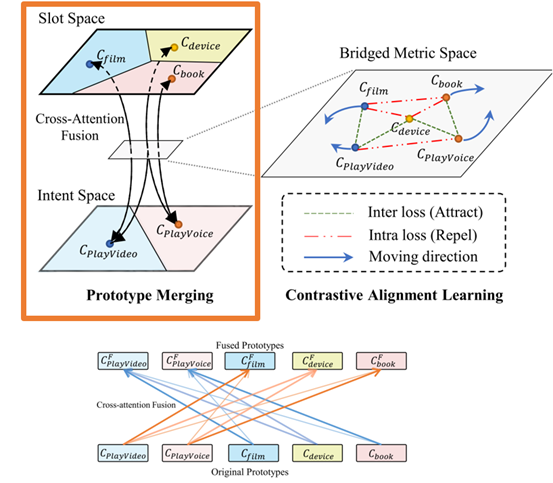
具体地,意图和槽位是否相关的关系是通过意图和槽类原型之间的交叉注意力来学习的(如图4 下所示)。然后,我们用插值的方式融合跨任务但相关的类别表示信息,从而在两个任务的原型之间自适应地共享信息,如下式所示:

2.4 比较对齐学习
(1)动机:
-
联合优化连接后的度量空间。 -
优化的直觉和目标是,相关的意图和插槽类别应该相邻分布,否则应该彼此分开。
(2)解决方案:具体地,我们用边缘对比损失(Margined Contrastive Loss)正则化小样本模型的学习过程。以达到如图5右半部分所示的效果。正则loss如下所示:
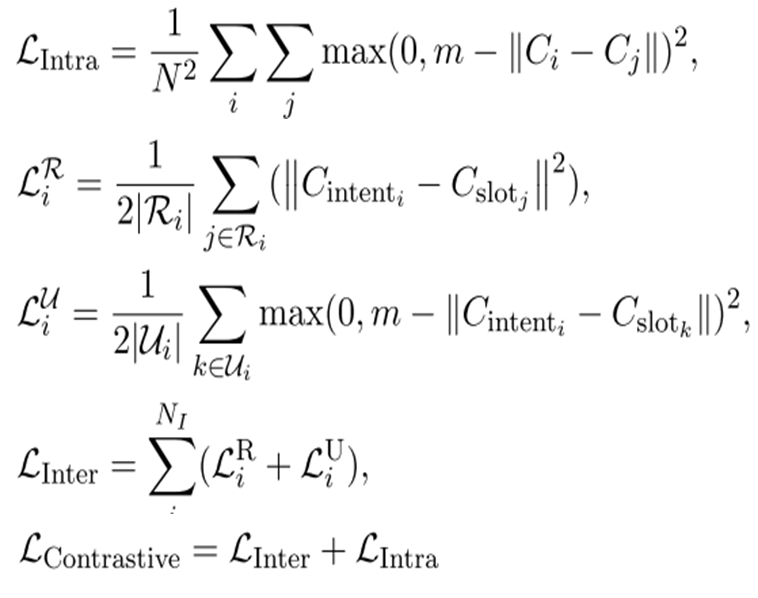
最终的联合模型的学习loss的是多个任务的loss加上Margined Contrastive Loss。
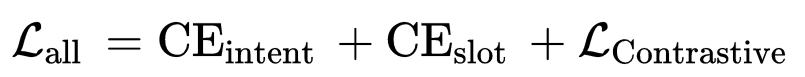
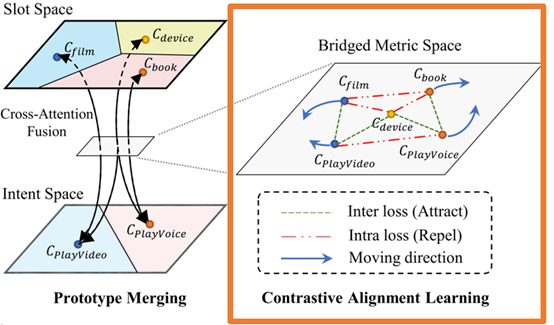
图5 Contrastive Alignment Learning 比较对齐学习
3 实验
我们在两个数据Snips和FewJoint上进行了1-shot 和5-shot 实验。如图6所示,我们的模型大幅地提升了联合准确率。
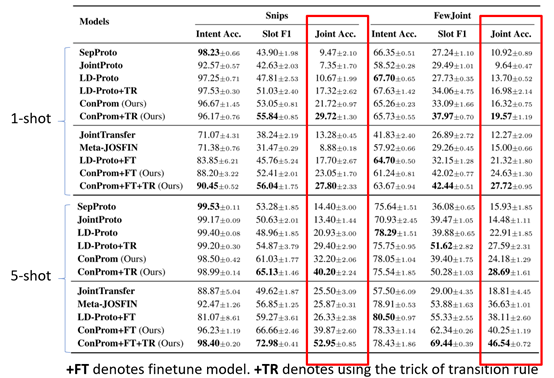
图6 主实验结果
图7是联合学习的可视化效果图,可以看到,我们的方法相较于简单地共享编码器(Encoder),能更有效地捕获不同任务之间的类别联系,并使不同类别的分布更加合理、易于区分。
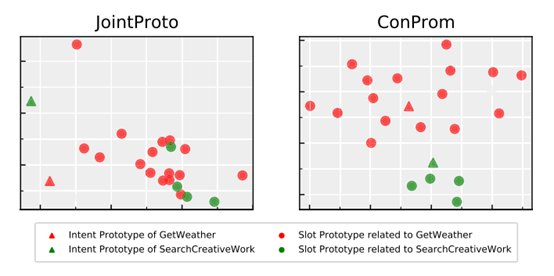
图7 联合学习的可视化效果
4 总结
本文中,我们以对话语言理解为切入点,研究了Few-shot情景下的联合学习问题。我们提出了一种基于相似度的Few-shot学习方案:“ Contrastive Prototype Merging Network(ConProm 共舞)”。我们在数据丰富的领域上学习如何动态地桥接不同任务的度量空间,然后在桥接后的度量空间上联合地优化两个任务。在两个公共数据集Snips和FewJoint上进行的实验表明,我们的模型显著优于最强baseline。
5 引用
[1] Erik G. Miller, Nicholas E. Matsakis, and Paul A. Viola. 2000. Learning from one example through shared densities on transforms. In Proc. of the CVPR, pages 1464–1471. IEEE Computer Society.
[2] Oriol Vinyals, Charles Blundell, Tim Lillicrap, Koray Kavukcuoglu, and Daan Wierstra. 2016. Matching networks for one shot learning. In Proc. of the NeurIPS, pages 3630–3638.
[3] Joseph Worsham and Jugal Kalita. 2020. Multitask learning for natural language processing in the 2020s: where are we going? Pattern Recognition Letters.
[4] Qian Chen, Zhu Zhuo, and Wen Wang. 2019. BERT for joint intent classification and slot filling. CoRR, abs/1902.10909.
[5] Libo Qin, Wanxiang Che, Yangming Li, Haoyang Wen, and Ting Liu. 2019. A stack-propagation framework with token-level intent detection for spoken language understanding. In Proc. of the EMNLPIJCNLP, pages 2078–2087, Hong Kong, China. Association for Computational Linguistics.
[6] Chih-Wen Goo, Guang Gao, Yun-Kai Hsu, Chih-Li Huo, Tsung-Chieh Chen, Keng-Wei Hsu, and YunNung Chen. 2018. Slot-gated modeling for joint slot filling and intent prediction. In Proc. of the NAACL, Volume 2 (Short Papers), pages 753–757, New Orleans, Louisiana. Association for Computational Linguistics.
本期责任编辑:冯骁骋
理解语言,认知社会
以中文技术,助民族复兴




