赛尔原创@ACL 2021 | 如何利用DialoGPT辅助对话摘要任务?
论文名称:Language Model as an Annotator: Exploring DialoGPT for Dialogue Summarization 论文作者:冯夏冲、冯骁骋、覃立波、秦兵、刘挺 原创作者:冯夏冲 论文链接:https://aclanthology.org/2021.acl-long.117/ 代码链接:https://github.com/xcfcode/PLM_annotator Slides链接:http://xcfeng.net/res/paper-slides/ACL2021-slides.pdf 转载须标注出处:哈工大SCIR
1. 背景
从EMNLP 2019开始,对话摘要(Dialogue Summarization)以“迅雷不及掩耳之势”进入研究者的视野,成为了摘要领域最为火热的方向。从图1可以看出,一直到最近刚刚放榜的EMNLP 2021,对话摘要依旧持续发力。据统计,EMNLP 2021对话摘要论文大约占全部摘要论文的25%,数量可观。本文主要介绍我们发表在ACL 2021的论文,探索了如何利用DialoGPT辅助对话摘要任务。
图1 摘要论文标题词云图
2. 摘要
现有的对话摘要系统往往通过引入辅助信息(例如:关键词和主题)来增强对话文本理解能力。然而,这些辅助信息要么使用对话无关的开放域工具获得,要么通过耗时耗力的人工标注获得。为了缓解上述问题,本文提出利用预训练对话回复生成模型DialoGPT作为一种无监督的对话标注器,借助其在预训练阶段编码的背景知识来获得辅助信息。本文将DialoGPT标注器用于AMI和SAMSum两个对话摘要数据集,标注三种类型的辅助信息:关键词,冗余句和主题分割。在标注之后的数据集上,我们使用基于预训练(BART)和非基于预训练(Pointer-Generator)的两类摘要模型进行实验。实验结果显示我们的标注方法可以帮助摘要模型获得提升,并且我们的方法在SAMSum数据集上取得了SOTA效果。
3. 动机
3.1 什么是一个好的摘要?
Peyrard[1]指出,一个好的摘要应该满足三方面的需求:尽可能包含原文信息(高信息量)、剔除原文冗余信息(低冗余度)、与原文相关(高相关度)。聚焦到对话摘要任务,高信息量要求模型可以选择对话中关键的词语、短语;低冗余度要求模型去除对话中无实际含义句子;高相关度要求模型覆盖对话中的每一个主题。因此,我们的目标就在于辅助摘要模型完成这三点目标。
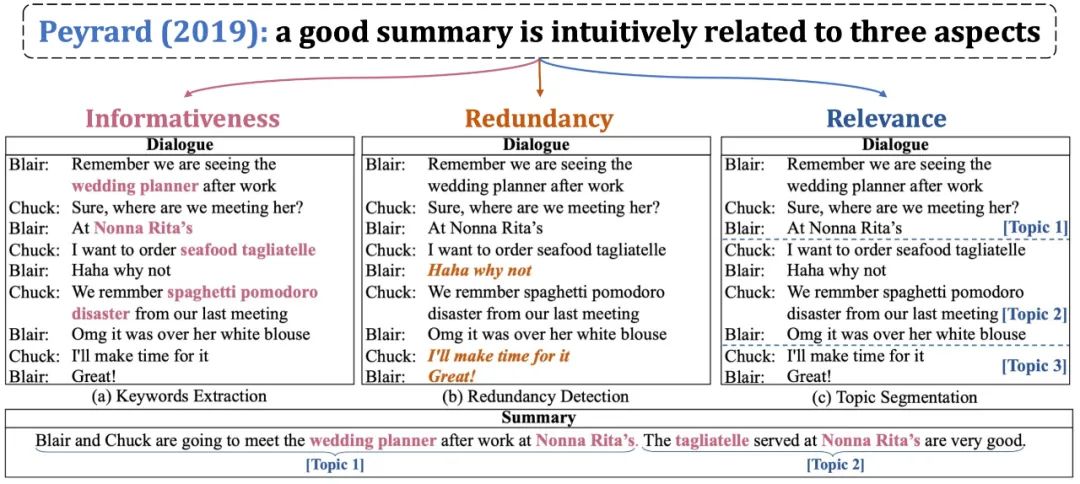
图2 一个好的摘要应该满足三方面需求:高信息量、低冗余度、高相关性
3.2 为什么要利用DialoGPT?
对话摘要任务的核心难点在于理解对话。在目前预训练语言模型的范式之下,暂时没有可以直接适配对话摘要任务的预训练语言模型。因此我们将目光转向预训练对话回复生成模型(例如:DialoGPT),虽然其任务目标与对话摘要不一致,但是其核心难点同样为理解对话文本。最后,我们将目光锁定在挖掘DialoGPT中以参数形式存储的知识,用于理解对话,从而辅助对话摘要任务。
4. 方法
我们的核心想法是利用DialoGPT为对话提供多种标注信息,如图3所示。
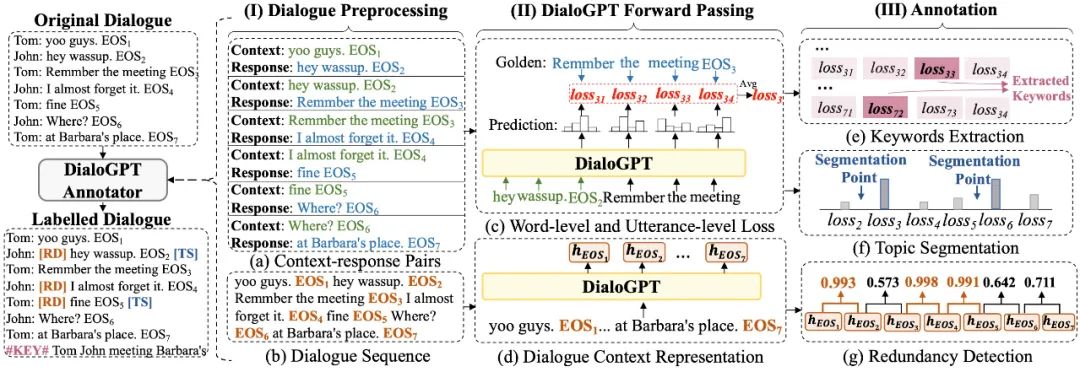
图3 关键词抽取、主题分割、冗余句检测流程图
4.1 关键词抽取
首先给出我们的猜想:给定对话上文,如果一个见过海量对话数据的语言模型无法预测出下文中的词语,说明该词语“另辟蹊径、不符常规”,包含的信息量高,是该下文中的关键词。基于这一想法,我们进行关键词抽取这一标注任务。我们输入对话的上文,使用DialoGPT在每一个解码步预测输出分布,然后和标准的回复词语计算损失,如果损失大,说明该词语包含了较高的信息量,可能是一个关键词。
4.2 主题分割
在这一步,我们采用句子级别的损失。我们的猜想是:如果下文句子整体比较难预测,则该下文句子很有可能已经在讨论另一个主题。因此我们首先计算句子级别的损失,然后在损失较高的句子之前插入主题分割点。
4.3 冗余句检测
由于DialoGPT是一种解码器结构,后面的词语会收集之前词语的信息。因此我们首先获得每一个 位置的表示,代表了对话前 句的整体表示( 代表第 句话的结束)。我们的猜想是:如果新增一个句子,没有对当前对话表示造成太大的影响,也就是前 句对话与前 句对话表示相似度很高,说明新增的第 句话没有包含实际含义。除此以外,DialoGPT的作用是预测回复,如果两个对话上文的表示很相似,说明新加入的句子对回复生成没有太大影响。因此,我们将其识别为冗余句,如图4所示。
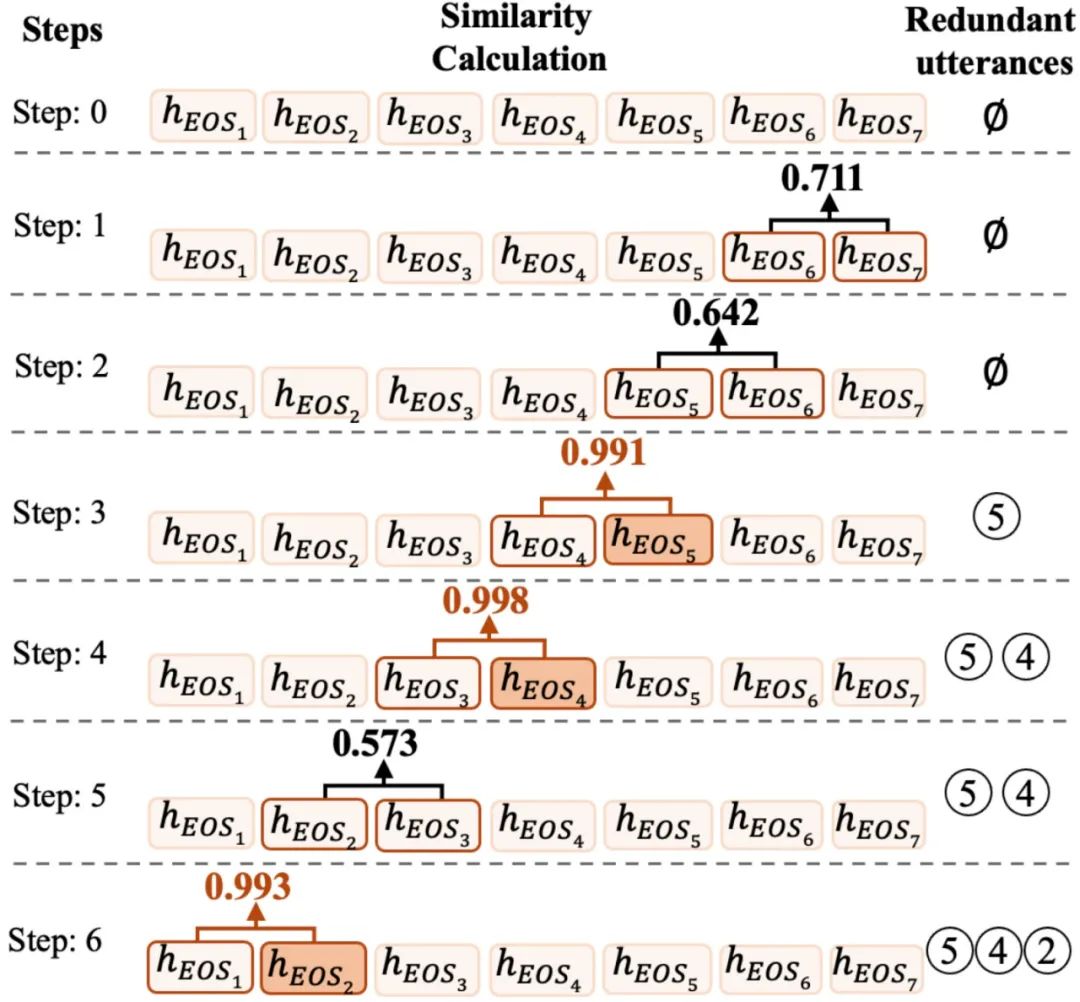
图4 冗余句检测流程图
4.4 小结
我们首先使用DialoGPT为对话提供三种标注,三种标注分别以标签形式插入到对话中,然后利用标注之后的数据训练模型,测试模型,如图5所示。
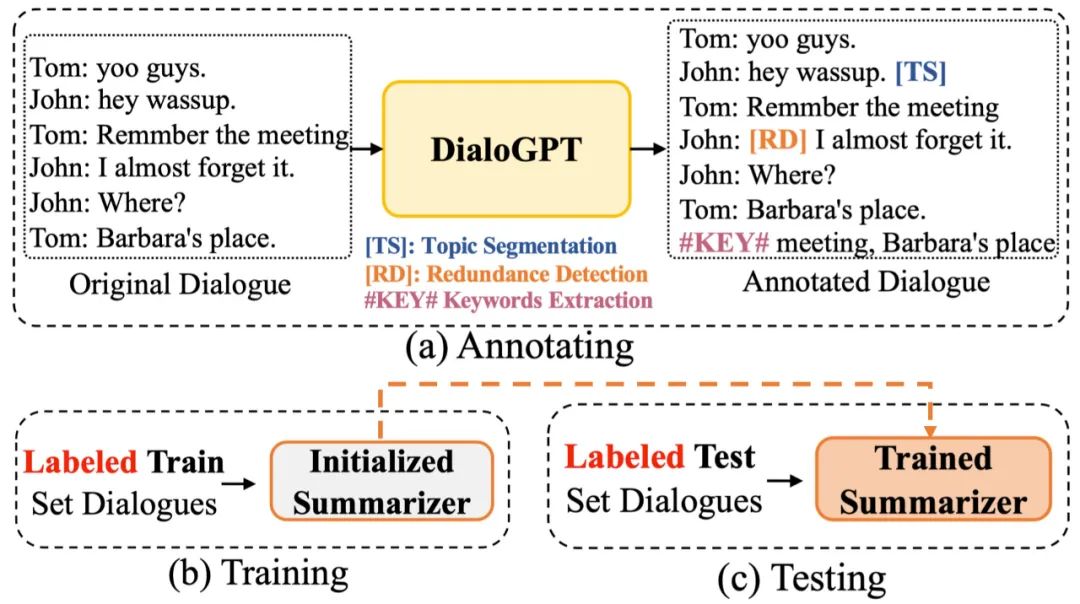
图5 标注、训练、测试流程
5. 实验结果
我们在两个标准的对话摘要数据集SAMSum和AMI上进行实验,均取得了有效提升,并且在SAMSum上取得了SOTA效果,如图6所示。
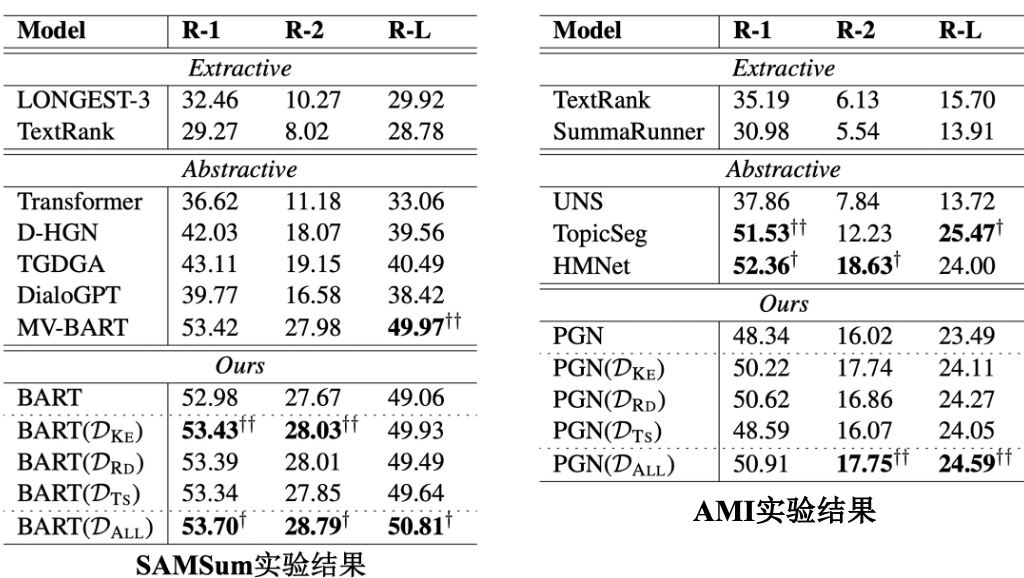
图6 实验结果
6. 扩展
我们针对论文之外的一些思考。最近大热的方向,Prompt learning当属其中之一,其核心想法是为了让下游任务适配预训练语言模型,更常见的应用于自然语言理解任务。通过构建prompt,在[MASK]位置输出词语分布,根据该分布再映射到最终的答案,这是一种利用prompt,在[MASK]位置显式去预测答案的方法。我们的工作没有设定显式的[MASK],我们隐含的设定是在对话-回复对中,回复的每一个词语都是[MASK]。我们通过[MASK]位置的预测分布和真实词语的差距来判断该词语信息含量的高低。通俗来讲,如果该[MASK]位置预测损失大,我们将这一词语分类为高信息量词语。除此以外,还有一些工作具有相似的想法。BARTScore[2]是一种基于BART预训练语言模型的文本生成评价方法,其核心在于利用输出分布评价文本,通过不同的转换,可以评价Faithfulness,Precision,Recall和F-score。Inverse Prompting[3]核心在于利用已生成部分预测输入主题,该部分的损失由一个语言模型的输出分布与主题计算损失得到,同样利用了预训练语言模型的输出分布来完成一些任务。
7. 总结
本文将DialoGPT视为一种无监督的对话标注器,为对话数据提供不同类型的标注信息,以标签的形式丰富对话表示,进一步辅助对话摘要任务。我们在两个对话摘要数据集上取得了提升,并且在SAMSum上取得了SOTA效果。
参考文献
[1] Peyrard M. A Simple Theoretical Model of Importance for Summarization[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 1059-1073.
[2] Yuan W, Neubig G, Liu P. BARTScore: Evaluating Generated Text as Text Generation[J]. arXiv preprint arXiv:2106.11520, 2021.
[3] Zou X, Yin D, Zhong Q, et al. Controllable Generation from Pre-trained Language Models via Inverse Prompting[J]. arXiv preprint arXiv:2103.10685, 2021.
本期责任编辑:刘 铭
理解语言,认知社会
以中文技术,助民族复兴


