
在广义零样本(Generalized Zero-shot Learning,GZSL)问题中,由于其可见类与不可见类的类别相互独立的特性,域偏移问题[1]是研究者面临的主要问题之一。而伪样本生成是目前提升模型在GZSL问题中的性能的最有效的方式。但是这类方式仍然存在以下两个问题:(1)特征混淆. 目前基于整体视觉特征(基于预训练好的CNN网络提取的2048D的高级特征)的GZSL模型中,其视觉特征所包含信息的丰富程度远大于属性语义特征,因此直接构建两者之间的映射并进一步合成伪样本并不符合人类一致认知,虽然有相关工作[2, 3]进行了视觉特征的解耦,但它们采用了生成式模型的方式,难以基于有限的可见类样本去保证有效的解耦和生成。(2)分布不明确. 已有GZSL模型尤其是生成式模型需要大量数据去拟合真实数据的分布,并且生成的伪样本分布是不明确的,这会导致在可见类样本数量有限时,模型表现不佳。
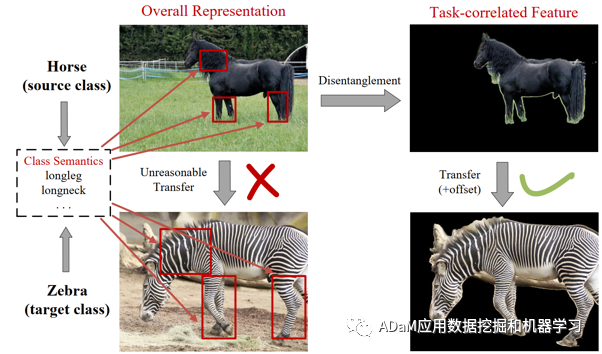
基于以上描述,我们提出了一种非生成式的任务相关解耦和可控伪样本合成模型(TDCSS)。TDCSS主要由两部分组成:(1)任务相关特征解耦模块. 我们根据视觉特征是否对应类语义,以非生成式的方式将整体特征解耦为任务相关特征和任务无关特征。(2)可控伪样本生成模块. 在任务相关特征的基础上,以非生成的方式合成两种类型的伪样本,即边缘伪样本和中心伪样本。这样既可以保证在不同任务场景下所生成伪样本的多样性,还有助于探索不同特性的伪样本在GZSL任务的知识迁移中所起到的作用。此外
,为了准确描述可见类样本数量受限的情景,我们还形式化了一种新的零样本学习场景“Few-shot Seen class and Zero-shot Unseen class learning”(FSZU)。因为在 GZSL任务中,可见类与不可见类之间具有很强的语义关系。因此我们认为ZSL和Few Shot Learning (FSL)共存的情况是合理的。在多个广泛使用的数据集的实验结果显示,我们的TDCSS模型在GZSL和FSZU任务中,均具备更好的性能。

