赛尔原创@EMNLP 2021 | 基于稀疏子网络的领域迁移
论文名称:Less Is More: Domain Adaptation with Lottery Ticket for Reading Comprehension 论文作者:朱海潮,汪泽堃,张恒,刘铭,赵森栋,秦兵 原创作者:朱海潮 论文链接:https://aclanthology.org/2021.findings-emnlp.95/ 转载须标注出处:哈工大SCIR
1. 介绍
机器阅读理解旨在根据给定上下文来回答相关问题,近年来在工业界与学术界均得到了广泛的关注,目前最先进的系统都是基于预训练模型构建的。即便如此,仍然需要大量标注数据才能达到比较理想的结果,对于一些缺乏大规模有标注数据领域和场景,现有模型的迁移效果往往并不令人满意。相关工作[1,2]探索利用无标注的目标领域文本进行领域迁移,但这种方法无法使模型对目标领域的问题进行有效建模。在本文中,我们利用少量的标注数据,通过对在大规模有标注领域上训练过的模型进行迁移,来提高在目标领域上的表现。另一方面,基于Transformer的预训练模型通常包含至少上亿个参数,如BERT Base的大小为110M。鉴于目标领域只有少量的标注数据,调整全部参数以适应目标领域非常困难,而且也是不必要的。另外,有研究[6]表明大规模稠密的神经网络模型有过参数化(over-parameterized)的趋势。我们探索只利用一小部分参数进行领域迁移,这些参数对应原稠密神经网络模型中的一个稀疏子网络。此外,我们还引入对自注意力模块的分析,来找到更具迁移性的稀疏子网络。最后,我们在多个目标领域上进行了实验,取得超过多种基线方法的效果,我们还对提出的方法进行了仔细的分析。
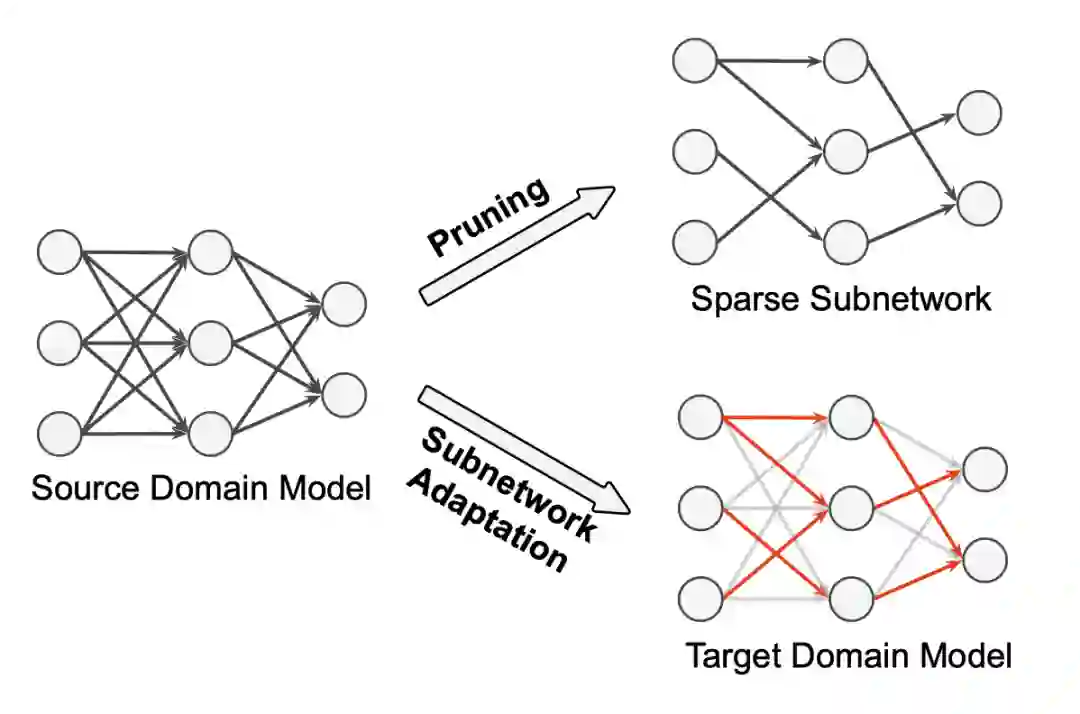
图1. 基于稀疏子网络的领域迁移方法
2. 背景
2.1 Transformer架构
如图2所示,Transformer模型一般由输入嵌入层、输出层和若干结构相同的Transformer层堆叠组成。更具体地,每层由一个多头自注意力模块和前馈模块组成,共包含6个参数矩阵。

2.2 自注意力分析
有许多工作[3,4]尝试分析解释Transformer模型的行为,最近,Hao[5]等人提出一种新的分析方法AttAttr可以估计每个自注意力头对模型输出的贡献。本文采用此方法对在不同阅读理解领域数据集上微调过的BERT模型进行分析,如图3所示,我们发现重要的注意力头在不同的领域上呈强正相关分布,即在一个领域上重要的自注意力头,也极有可能在其它领域上也非常重要。基于这一发现,我们提出了本文的面向阅读理解任务的少样本领域迁移方法。

3. 方法
我们在大规模标注数据的源领域上训练过的Transformer模型迁移到只有少量标注数据的目标领域上。在迁移时,我们通过减枝来识别只包含少量参数的稀疏子网络,并只对子网络的参数进行更新来适应目标领域,在寻找子网络时,通过引入自注意力归因,来同时考虑参数的结构化与非结构化的重要性。
3.1 子网络识别
Magnitude Pruning是一种简单有效的非结构化减枝方法,这个方法根据参数的绝对值大小进行减值。我们以该方法为基础,通过迭代的方式分若干步来逐渐删减参数到目标数量,并且每次删减部分参数后,都会对网络进行一定步数的训练,恢复模型在源领域上的效果,然后再进行下一步的参数删减。在本文中,我们只对每层Transformer层中的6个参数矩阵进行删减,其余的参数矩阵和偏置完全保留。
此外,在进行参数的重要性比较以选择要删减的参数时,通常有两种策略,一种是所有参数一起进行全局比较,另一种是只在参数矩阵内部进行局部比较。在我们对参数矩阵的分析中发现,不同的参数矩阵的绝对值均值分布有较大的差异,若采用全局减枝,最后的结果会很大程度上被均值差异影响,而局部比较则最后所有参数矩阵具有相同的稀疏度,并且忽略了参数矩阵本身的所在模块的重要性。所以,我们提出一种分组比较策略,根据不同参数矩阵的均值进行分组,在组内进行全局比较,具体地,将均值相当的参数矩阵分为一组,最后划分为三组。
根据之前对阅读理解任务的自注意力分析发现,Transformer中的不同自注意力头对于模型最后的预测并不是同等重要的,并且重要性的分布在不同的领域上高度正相关。所以,我们引入自注意力归因来补充Magnitude Pruning,以期得到能够更好的迁移到目标领域的子网络。具体地,在进行每一步减枝时,我们先估计出当前模型中不同注意力的重要性得分并进行归一化,以此作为对参数绝对值进行缩放,需要注意的是,同一个注意力头中的参数矩阵共享同一个重要性得分。此外,还通过超参数 来控制归因得分对最后参数重要性的影响。总体来说,通过这种方式,我们同时考虑到了参数的非结构化与结构化重要性,整体算法如图4所示。

图4. 稀疏子网络识别算法
3.2 子网络迁移
通过上述步骤后,最后剩下的参数即为找到的子网络的结构,在进行领域适应时,我们保留得到的结构,但将参数回滚到减枝前,即源领域模型上的状态,在后续的参数更新时只更新子网络对应的参数,其余参数不进行梯度更新。但需要注意的是,所有的参数均参与前向计算过程。
4. 实验及分析
4.1 数据集
在我们的实验中,以SQuAD为源领域数据集,通过对五个目标领域数据集采样来模拟少样本领域迁移的场景,具体的领域数据集信息如表1所示。
表1. 数据集特征及统计信息

4.2 基线方法
-
Zero-Shot 不进行迁移,直接在目标领域上进行预测。 -
Fine-tuning 微调源领域模型的全部参数进行领域适应。 -
EWC(Elastic Weight Consolidation) 一种正则化算法,使得参数在更新时不至大幅偏离原始参数。 -
Layer Freeze 只调整Tranformer模型接近输出层的若干层的参数,其余参数则保持不动。 -
Adapter 保持源领域模型的参数不动,通过添加并调整额外的adapter模块来进行领域适应。
4.3 实验结果与分析
如表2所示,当使用1024条目标领域标注数据,并将用于领域迁移的参数数量限定在21M时,本文提出的Alter在4个目标领域上取得了超过基线方法的效果。其中,我们的方法和Layer Freeze还有Adapter调整数量相当的参数量来进行领域适应。在NQ数据集上,当使用42M参数时,我们的方法与Fine-tuning表现相当。进一步地,当不对参数数量进行限制时的实验结果如图5-8所示,除NQ外我们的方法也均取得了超过基线方法的效果,并且通常只需要完整模型的20%-30%的参数即可。

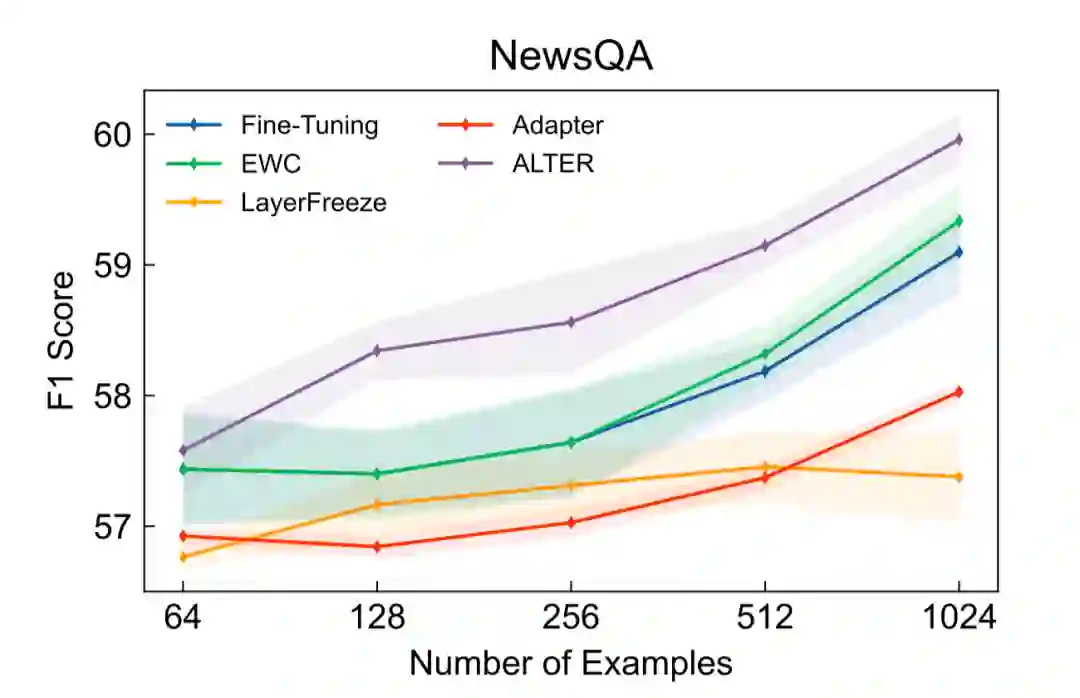 图5. NewsQA实验结果
图5. NewsQA实验结果
 图6. TriviaQA实验结果
图6. TriviaQA实验结果
 图7. TweetQA实验结果
图7. TweetQA实验结果
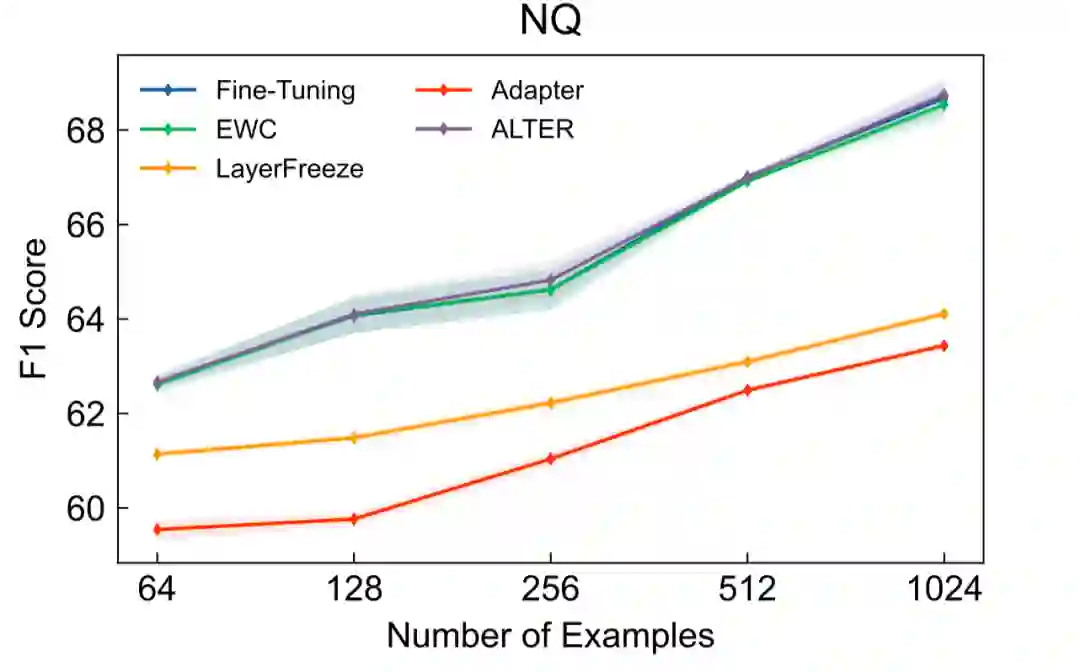 图8. NQ实验结果
图8. NQ实验结果
图9展示了引入自注意力头来帮助寻找稀疏子网络的结果,通过对比可以发现,在使用不同数量的目标领域标注数据及不同规模的参数进行领域迁移时,自注意力头均能够帮助找到迁移效果更好的子网络。
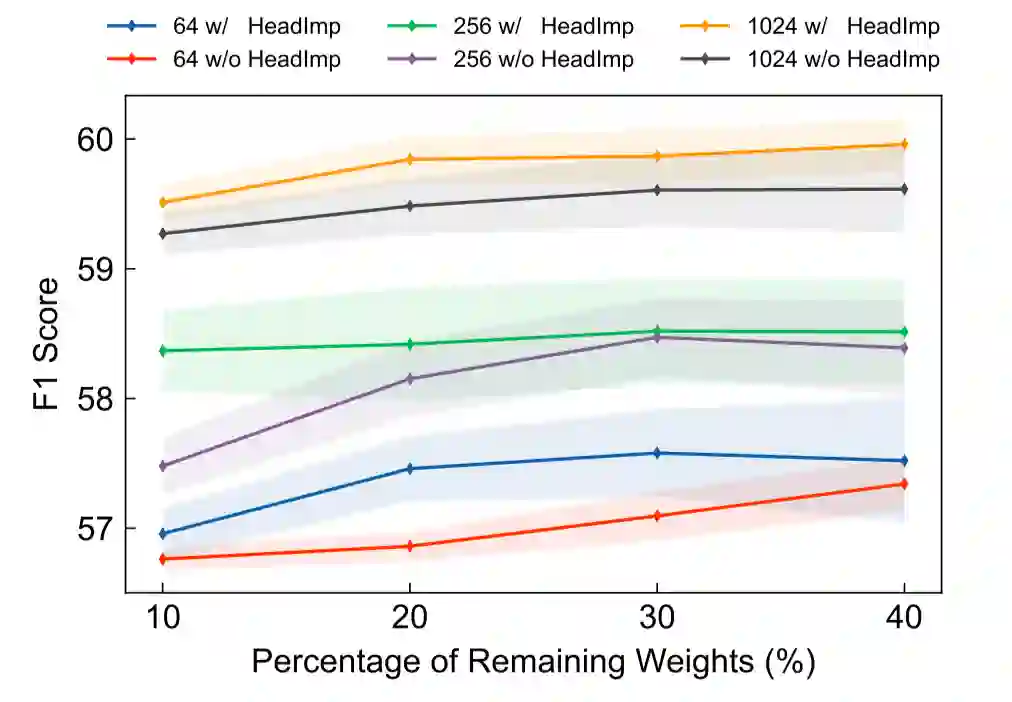
为了探究不同的子网络识别方法得到的结构对迁移效果的影响,我们进行尝试了以下四种候选方法:
-
Random 随机选取目标数量的参数 -
Magnitude 只根据参数的绝对值大小进行选择 -
Salvage 采用与本文提出的相同的流程,但采用相反的策略选择参数,即使用原本被减掉的参数进行迁移 -
AttrHead 采用结构化减枝的方式得到,将若干自注意力头的参数整体剪掉,对于前馈层的参数则仍采用非结构化的方式减枝
实验结果如表3所示,使用不同方法得到的子网络大小一致,不同的方法的效果差别并不明显,但均超过了调整全部参数的方法。对比Salvage和Alter,我们发现使用对模型输出影响更大的参数的效果更好。通过与AttrHead方法进行比较,我们可以发现,重要性得分较低的自注意力头中绝对值较大的参数对领域迁移也有用。

5. 结论
在本文中,我们针对少样本阅读理解领域迁移提出了一种简单而有效的方法Alter,该方法只使用过参数化的源领域模型中的一部分参数进行目标领域迁移,我们还引入了自注意力归因来识别子网络以取得更好的迁移效果,通过进一步探索不同的子网络识别方法,发现除了使用更少的参数以外,子网络的结构也非常重要。
6. 参考文献
[1] Huazheng Wang, Zhe Gan, Xiaodong Liu, Jingjing Liu, Jianfeng Gao, and Hongning Wang. Adversarial domain adaptation for machine reading comprehension. EMNLP 2019.
[2] Yu Cao, Meng Fang, Baosheng Yu, and Joey Tianyi Zhou. Unsupervised domain adaptation on reading comprehension. AAAI 2020.
[3] Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. What does BERT look at? an analysis of BERT’s attention. ACL 2019 Workshop BlackboxNLP.
[4] Olga Kovaleva, Alexey Romanov, Anna Rogers, and Anna Rumshisky. Revealing the dark secrets of BERT. EMNLP 2019.
[5] Yaru Hao, Li Dong, Furu Wei, and Ke Xu. Self-attention attribution: Interpreting information interactions inside transformer. AAAI 2021.
[6] Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. A convergence theory for deep learning via overparameterization. PMLR 2019.
[7] Paul Michel, Omer Levy, and Graham Neubig. Are sixteen heads really better than one?. NeurIPS 2019.
[8] Victor Sanh, Thomas Wolf, and Alexander M. Rush. Movement pruning: Adaptive sparsity by finetuning. NeurIPS 2020.
[9] Jonathan Frankle and Michael Carbin. 2019. The lottery ticket hypothesis: Finding sparse, trainable neural networks. ICLR 2019.
本期责任编辑:赵森栋
理解语言,认知社会
以中文技术,助民族复兴


