精心设计的 GNN 只是“计数器”?

(本文阅读时间:8 分钟)
长期以来,问答(QA)问题都是人工智能和自然语言处理领域中一个基本且重要的课题,层出不穷的研究工作都试图赋予问答系统具有人类水平的推理能力。然而,人类的推理过程是极为复杂的,为了接近这样复杂的推理,目前最前沿的方法一般会使用预训练的语言模型(LM)来获取和利用其隐含的知识,再辅以精心设计的图神经网络(GNN)来对知识图谱进行推理。但是关于 GNN 模块在这些推理中到底发挥了哪些功能,仍需要进一步深入研究。
为此,微软亚洲研究院和佐治亚理工的研究员们剖析了最前沿的相关方法,并且发现一种极其简单、高效的图神经计数器就能在主流的知识问答数据集中取得更好的效果。同时,研究员们还揭示了当前基于知识推理的 GNN 模块很有可能只是在完成简单的推理功能如计数。(点击阅读原文,查看论文)

论文链接:https://arxiv.org/abs/2110.03192
知识的获取和推理是问答(QA)任务的核心, 而这些知识被隐式编码于预训练语言模型(LM)或者显式存储在结构化的知识图谱(KG)里。当前的 LM 在预训练过程中都会使用大规模的语料库,其中蕴含极其丰富的知识,这就使得 LM 稍加微调(finetune)就可以在各种 QA 数据集上取得不错的表现。
但是,LM 更依赖于共现(co-occurrance),这在处理推理问题时捉襟见肘,并缺乏可解释性。而与之互补的 KG 尽管需要人工整理且规模受限,但它可以直接显示存储特定的信息和关系,从而具备可解释性。
如何在 QA 里将二者结合起来扬长避短是近年来的热点话题,最前沿的工作大多采用了两个步骤来处理知识图谱:
1. Schema graph grounding。在知识图谱里检索与 QA 文本提及的实体相关联的子图,这个子图包含带有概念文本的节点和代表关系的边以及邻接矩阵。
2. 图建模推理(Graph modeling for inference)。用设计精巧的 GNN 模块对这个子图进行建模推理。
这里的 GNN 模块通常会设计得比较复杂,比如 KagNet 用了 GCN-LSTM-HPA 即基于路径的分层注意力机制(HPA)来耦合 GCN 与 LSTM,从而对基于路径的关系图进行表征;再如 QA-GNN 则在以 GAT 网络为主体的同时,用 LM 将 QA 文本编码到图中,成为一个单独的节点,从而与图中其它概念和关系进行联合推理。
随着 QA 系统变得越来越复杂,研究员们也不得不进一步思考一些基本问题:这些 GNN 模型是不够复杂还是过于复杂了?它们究竟在推理中扮演了哪些关键的角色?
为了回答这些问题,研究员们首先分析了现在最先进的基于 GNN 的 QA 系统及其推理能力。基于发现,研究员们设计了一种图计数网络。这个网络不光简单高效,而且在 CommonsenseQA 和 OpenBookQA 这两个基于推理的主流数据集上都达到了更优的效果。

图 1 :研究员们分析发现当前 GNN 在 QA 中扮演的关键角色是对边进行计数,于是便设计了一种高效且具有解释性的图计数模块来对 QA 进行推理。

图 2:研究员们用剪枝方法 SparseVD 作为工具对 QA 里的 GNN 各个模块进行分析,发现边的信息相关层极为重要,而其它很多层存在过参数化的现象。
基于分析结论,研究员们设计了一个极其简单且高效的基于计数的Graph Soft Counter(GSC)。如图3所示,相较于其他主流的 GNN 如 GAT,GSC 只有两个基本部件:边编码器(Edge encoder)和图计数层(Graph Soft Counter Layer),并且节点和边上的隐层维度也减少到1,这意味着在途中流动的全是单个的数字,可以将它们解释为边和节点的重要性分数。亦如图4的算法一所示,GSC 极度简化 massage passing 的过程为最基本的两个操作即 propagation 和 aggregation,从而将这些重要性分数加总到 QA context 中心节点,并作为选项的分数进行输出。

图 3:GSC 层交替更新边和节点上的计数分数

图 4:算法一:将边信息进行编码后,GSC 层执行 message passing 将分数汇总到中心节点即为图分
值得一提的是,GSC 层内部是完全无参数的,这也使得它非常高效。如表1所示,GSC 的可学习参数量少于其它 GNN 模块的百分之一,并且由于没有使用初始的Node Embedding,GSC 的模型存储大小更是小了五个数量级。再如表2所示,GSC 在时间和空间复杂度上也都极其高效。

表 1:GSC 仅使用了邻接矩阵和边/节点类型信息,且参数极少

表 2:GSC 在时间和空间复杂度上都极其高效
除了简单高效,GSC 的表现也很突出。研究员们在 CommonsenseQA 和 OpenBookQA 这两个基于推理的主流数据集上进行了实验。论文中提出的基线既有未使用 KG 的 LM 本身,也有其它使用 GNN 来处理 KG 的其他前沿方法。如表3~5所示,GSC 方法在两个数据集上都占有优势,并且在OpenBookQA 官方排行榜上位居第一,甚至超过了 UnifiedQA(11B)这个拥有110亿参数的巨无霸模型。

表 3:GSC 在 CommonsenseQA 数据集上优于其它基于 GNN 的方法
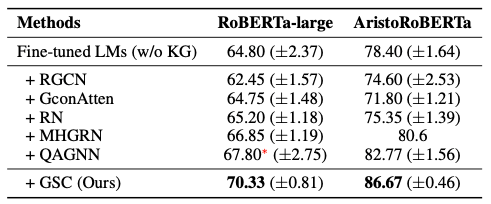
表 4:GSC 在 OpenBookQA 数据集上优于其它基于 GNN 的方法

表 5:GSC 在 OpenBookQA 官方排行榜上排名第一,甚至超过了 UnifiedQA
本篇论文的分析和提出的方法,揭示了当前复杂的基于 GNN 的 QA 系统很可能只是在执行一些基础的推理功能比如计数这一现象。如何打造一个面面俱到的 QA 系统以达到人类的推理水平仍是一个丞待解决的宏大命题。
你也许还想看: