语言模型及Word2vec与Bert简析


语言模型可以对一段文本的合理性概率进行估计,对信息检索,机器翻译,语音识别等任务有着重要的作用。就以前的学习笔记,本文简单总结了NLP语言模型word2vec和bert分享给大家,疏漏之处,望请指出, 后期会详细解析各类语言模型理论及应用,敬请期待。
语言模型可以对一段文本的合理性概率进行估计,对信息检索,机器翻译,语音识别等任务有着重要的作用。
1.1 语言模型是什么
语言模型的定义
给定一个词序列,W = w1,w2, … , wm,计算这个词序列能够组成一句合理自然语言的联合概率 P(W):
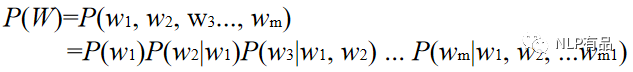
将句子的概率分解为各个单词条件概率的乘积,如果文本较长, 条件概率的估算会非常困难(维数灾难),所以就规定当前词只和它前面的n个词有关,与更前面的词无关,每一个词只基于其前面N个词计算条件概率 —— N-gram语言模型,一般N取1到3之间。
语言模型的通俗理解
给定一组单词序列,将单词排列组合成一段文本,判断该文本是否是一句人话:
单词序列:[我, 狗, 被, 了, 咬]
组合成句:
(1)我被狗咬了 P=0.5
(2)被我狗咬了 P=0.2
(3)狗被我咬了 P=0.03
常用的语言模型主要有两类:统计语言模型和神经网络语言模型
统计语言模型
HAL (Hyperspace Analogue to Language method)
LSA (Latent Semantic Analysis)
N-Gram
神经语言模型
CBOW (Continuous Bag-Of-Words Model)
Skip-gram (Continuous Skip-gram Model)
2. 神经语言模型 Word2vec 与 Bert
神经语言模型可直接用于NLP任务,随着深度学习的快速发展,语言模型也更多的应用于NLP模型的预训练,常用的预训练模型有:
Word2vec (Google)
Glove (Facebook)
ELMO (AllenNLP艾伦人工智能研究所)
GPT (OpenAI)
BERT (Google)
RoBERTa (FaceBook)
AlBert (Google)
MT-DNN (微软)
词集法(one-hot):统计文档总词数建立长度为N的字典,将单词表示为一个N维高度稀疏的向量,词对应位置元素值为1,其他全为0;
词袋法:统计文档总词数N,将单词表示为一个N维高度稀疏的向量,词对应位置元素为词在该篇文档中的词频,其他位置元素值为0;
词的分布式表示法:将词表示为低维度、稠密的向量,主要是通过神经网络训练语言模型得到,如word2vec、glove、BERT等。
顾名思义Word2Vec就是把单词转换成向量,它本质上是一种单词聚类的方法,是实现单词语义推测、句子情感分析等目的一种手段。
Word2Vec 有两种训练方法:用语言模型 CBOW 和 Skip-gram。1)CBOW的核心思想是从一个句子里面把一个词抠掉,用这个词的上文和下文去预测被抠掉的这个词;2)Skip-gram和 CBOW 正好反过来,输入某个单词,要求网络预测它的上下文单词。
训练完成之后,我们一般不需要用来做预测,而是取出模型input层与projection 层之间的参数,来作为我们每个词的向量表示(词向量),用于nlp下游任务的输入或用于NLP模型的词嵌入。

CBOW模型:
Input:输入层,上下文各词的one-hot向量表示;
Projection:投影层,将输入各词对应的词向量求和做累加;
Output:输出层,预测为每个词的概率列表。
优点
(1)将高度稀疏的one-hot词向量映射为底维度的语义向量,有效解决了one-hot词向量高稀疏、高冗余的缺点;
(2)能够较完整的表示词的语义信息,有效解决了one-hot词向量无语义等缺点。
缺点
词的静态表征,不能解决同义词问题,如水果中的“苹果”和苹果公司的“苹果”,词向量表示是一样的,而实际上这两词的意思完全不一样。
2.3 Bert
针对语言理解的深度双向Transformers模型的预训练:论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
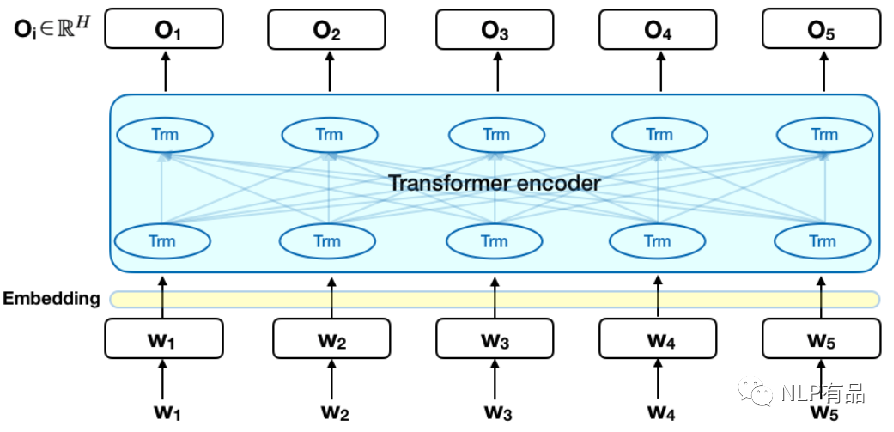

-
Token Embedding : 词特征(词向量)的嵌入,针对中文,目前只支持字特征嵌入; Segment Embedding:词的句子级特征嵌入,针对双句子输入任务,做句子A,B嵌入,针对单句子任务,只做句子A嵌入;
Position Embedding:词的位置特征,针对中文,目前最大长度为 512;
Bert 的预训练包含两项任务:语言模型和句子对关系判定。
双向语言模型:随机将输入中15%的词遮蔽起来,通过其他词预测被遮盖的词(这就是典型的语言模型),通过迭代训练,可以学习到词的上下文特征、句法特征等,保证了特征提取的全面性,这对于任何一项NLP任务都是尤为重要。
句子对判定:输入句子A和句子B,判断句子B是否是句子A的下一句,通过迭代训练,可以学习到句子间的关系,这对于文本匹配类任务显得尤为重要。
真正的双向:使用双向 Transformer,能同时利用当前单词的上下文信息来做特征提取,这与双向RNN分别单独利用当前词的上文信息和下文信息来做特征提取有本质不同,与CNN将上下文信息规定在一个限定大小的窗口内来做特征提取有本质不同;
动态表征:利用单词的上下文信息来做特征提取,根据上下文信息的不同动态调整词向量,解决了word2vec一词多义的问题;
并行运算的能力:Transformer组件内部使用多头注意力(Multi-headed attention)机制,能同时并行提取输入序列中每个词的特征,这与RNN依赖于时间单向串行提取特征有本质区别;
易于迁移学习:使用预训练好的BERT,只需加载预训练好的模型作为自己当前任务的词嵌入层或者直接用来做NLP任务,不需对代码做大量修改或优化。
2.3.4 Bert 怎么用
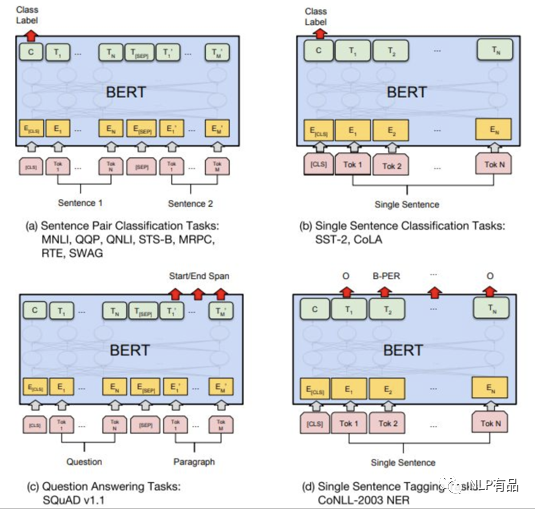
可以将Bert看做一个文本编码器,可以应用在各类NLP上下游任务网络构建中作为文本嵌入层使用。如上图(a)文本匹配任务;(b)文本分类任务;(c)抽取式问答任务;(d)序列标注任务。其中Bert微调的具体用法:
序列标注
加载预训练Bert模型;
取输出字向量:
embedding = bert_model.get_sequence_output();
然后构建后续网络。
文本分类和文本匹配任务
加载预训练BERT模型;
取输出句向量:
output_layer=bert_model.get_pooled_output();
然后构建后续网络。
下次更新内容可能包括:中文NLP各类任务简介 • 下、传统文本匹配算法解读(附代码)、NLP竞赛平台一览其中之一,敬请期待♥♥♥。
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
深度学习如何入门?这本“蒲公英书”再适合不过了!豆瓣评分9.5!【文末双彩蛋!】
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。




