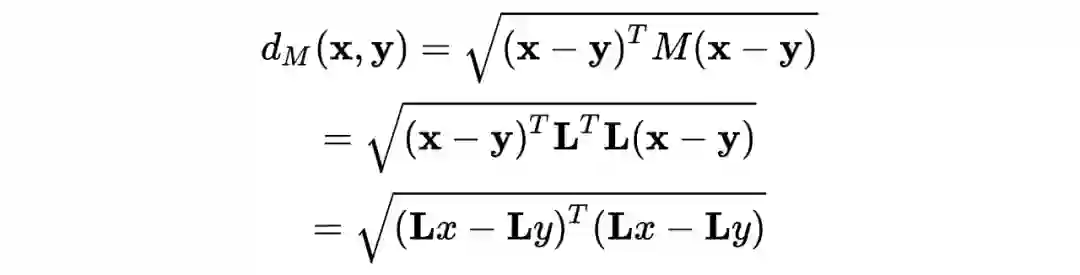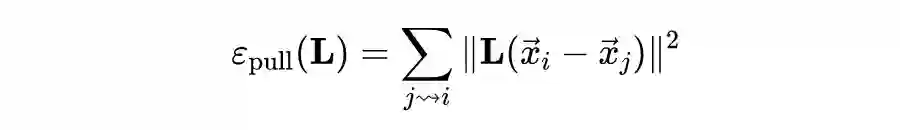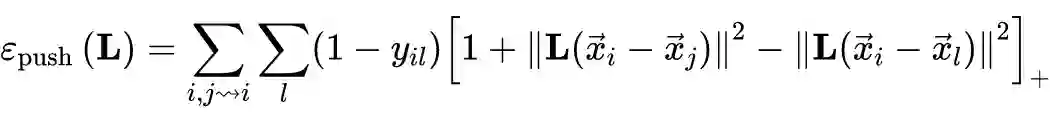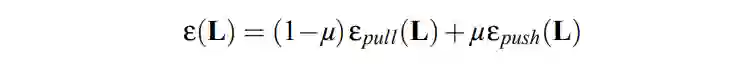distance metric learning 相关的研究大约始于二十年前,要认真算起来的话,其代表性的开山之作应该是 2002 年 Eric Xing 与 Andrew Ng、Michael Jordan 等人(真是每个名字都是大佬啊 hhh)合作在 NIPS 上发表的题为“Distance metric learning with application to clustering with side-information”的论文:
▲ Weinberger K Q, Saul L K. Distance metric learning for large margin nearest neighbor classification[J]. Journal of machine learning research, 2009, 10(2).
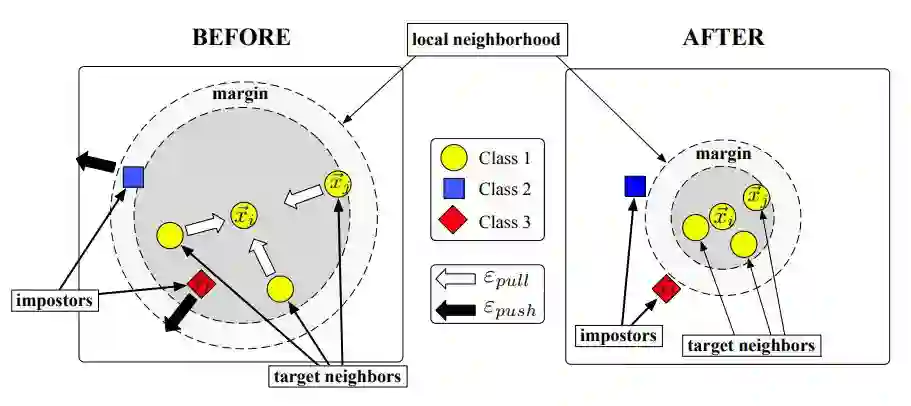
在左图所示原空间中,以 样本为例,离其最近的三个同类别样本(target neighbors)形成的圈子中,有其他类别的样本存在,这意味着如果在原空间使用欧氏距离结合 KNN 算法,容易受到所谓的入侵者(impostors)的影响。所以 LMNN 的核心思想就是通过学习一个 distance metric,使其所对应的线性投影矩阵投影到新空间后,最近的数个同类别样本(target neighbors)们被拉得更近、而每个样本的入侵者(impostors)都被推得更远,以致最近的数个同类别样本(target neighbors)围成的圈与入侵者(impostors)的距离有一个边界(margin)(如上面右图所示)。这样的话,经过 LMNN 学习到的 distance metric,采用 KNN 的算法来进行分类,就会有很好的效果了~ 那么,LMNN 是如何实现这一推一拉的呢?这得益于 LMNN 算法中巧妙的 loss function设计。LMNN 算法的 loss function 分为两个部分,一个部分负责拉近最近的数个同类别样本(target neighbors),一部分负责推开每个样本的入侵者(impostors)。 负责拉近的部分被构造为:
▲ j -> i 代表j是i的target neighbors 很显然,这部分通过惩罚同类别样本间的大距离达到拉近同类别样本的效果。负责推开的部分被构造为:
▲ j -> i 代表j是i的target neighbors 其中 代表标准的 hinge loss。如果 是 的 target neighbors,,那自然就不用推开了,此时这一项 loss 为 0;如果 是 的 impostors,,如果括号内大于 0,意味着在投影后的新空间中,仍然有 impostors 入侵到 margin 之内。所以此项 loss 通过惩罚括号内大于 0 的项(impostors 入侵进入 margin)来实现推开的 impostors 的功能。 最终这一推一拉利用一个参数 实现了平衡和调整:
1、Distance Metric Learning: A Comprehensive Survey:http://www.cs.cmu.edu/~./liuy/frame_survey_v2.pdf
2、A Survey on Metric Learning for Feature Vectors and Structured Data:https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/1306.6709.pdf%3Fsource%3Dpost_page---------------------------
Materials
1、A TUTORIAL ON DISTANCE METRIC LEARNING: MATHEMATICAL FOUNDATIONS, ALGORITHMS,
EXPERIMENTAL ANALYSIS, PROSPECTS AND CHALLENGES:https://arxiv.org/pdf/1812.05944.pdf
2、 Distance metric learning for CV: ECCV 2016 tutorial:http://ivg.au.tsinghua.edu.cn/ECCV16_tutorial/
3、Tutorials on metric learning:http://researchers.lille.inria.fr/abellet/talks/metric_learning_tutorial_CIL.pdf
4、Metric learning and some distributed optimization:http://researchers.lille.inria.fr/abellet/talks/metric_learning_distributed_opt.pdf