高性能涨点的动态卷积 DyNet 与 CondConv、DynamicConv 有什么区别联系?
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
上个月初次看到华为的DyNet一文时,第一感觉这不又是一次CondConv的翻版吧。为什么说又呢?因为之前看到MSRA的DynamicConv时已经产生过了类似的感觉。之前一直没时间静下来思考三者之间的区别所在,正好最近有空,故而花点时间来分析一下。
CondConv: https://arxiv.org/abs/1904.04971
DynamicConv: https://arxiv.org/abs/1912.03458
DyNet: https://arxiv.org/abs/2004.10694
1. CondConv
在常规卷积中,其卷积核参数经训练确定且对所有输入样本“一视同仁”;而在CondConv中,卷积核参数参数通过对输入进行变换得到,该过程可以描述为:
其中
一个样本依赖加权参数。在CondConv中,每个卷积核
具有与标准卷积核参数相同的维度。
常规卷积的容量提升依赖于卷积核尺寸与通道数的提升,将进一步提升的网络的整体计算;而CondConv则只需要在执行卷积计算之前通过多个专家对输入样本计算加权卷积核。关键的是,每个卷积核只需计算一次并作用于不同位置即可。这意味着:通过提升专家数据量达到提升网络容量的目的,而代码仅仅是很小的推理耗时:每个额外参数仅需一次乘加。
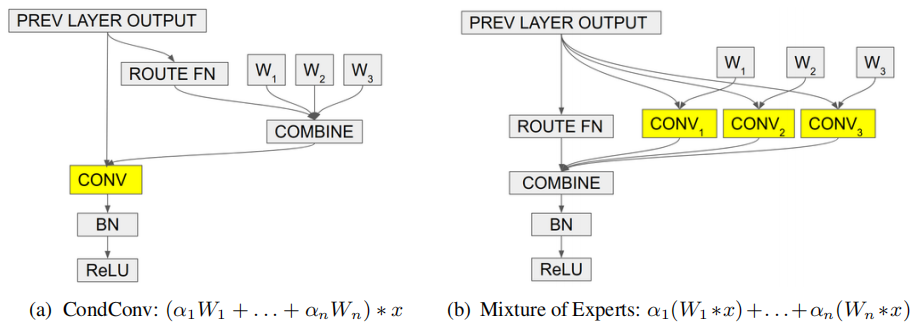
CondConv等价于多个静态卷积的线性组合,见上图b。因此它具有与n个专家同等的容量,但计算更为高效。而这其中最关键是:加权参数
。它必须具有数据依赖,否则CondConv将等价于静态卷积。那么如何设计该数据依赖型参数呢
?作者采用三个步骤计算该参数:
所提CondConv可以对现有网络中的标准卷积进行替换,它同时适用于深度卷积与全连接层。
很明显,这里所提的
CondConv就是一种标准的动态滤波器卷积,只不过它这里卷积核设计方式与已有其他动态滤波器卷积存在一些区别,但本质不变:数据依赖性。
2. DynamicConv
动态卷积的目标在于:在网络性能与计算负载中寻求均衡。常规提升网络性能的方法(更宽、更深)往往会导致更高的计算消耗,因此对于高效网络并不友好。
作者提出的动态卷积不会提升网络深度与宽度,相反通过多卷积核融合提升模型表达能力。需要注意的是:所得卷积核与输入相关,即不同数据具有不同的卷积,这也就是动态卷积的由来。
2.1 Dynamic Perceptron
首先,作者定义传统的感知器为 ,其中 分别表示权值、偏置以及激活函数;然后,作者定义动态感知器如下:
其中 表示注意力权值。注意力权值并非固定的,而是随输入变化而变化。因而,相比静态卷积,动态卷积具有更强的特征表达能力
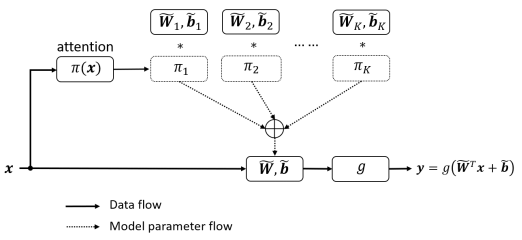
相比静态感知器,动态感知器具有更大的模型。它包含两个额外的计算:(a)注意力权值计算;(2)动态权值融合。尽管如此,这两点额外计算相比感知器的计算量可以忽略:
2.2 Dynamic Convolution
类似于动态感知器,动态卷积同样具有K个核。按照CNN中的经典设计,作者在动态卷积后接BatchNorm与ReLU。
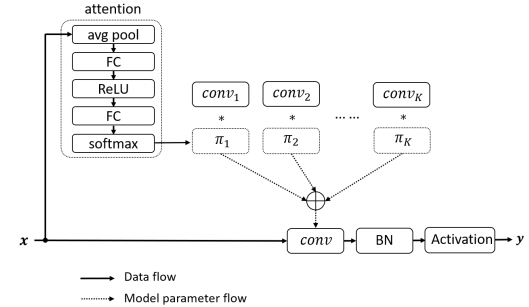
-
注意力:作者采用轻量型的 squeeze and excitation提取注意力权值 ,见上图。与SENet的不同之处在于:SENet为通道赋予注意力机制,而动态卷积为卷积核赋予注意力机制。 -
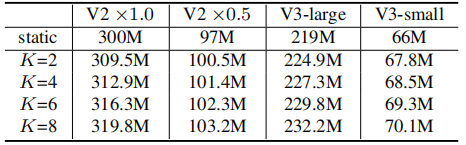
核集成:由于核比较小,故而核集成过程是计算高效的。下表给出了动态卷积与静态卷积的计算量对比。从中可以看到:计算量提升非常有限。
-
动态CNN:动态卷积可以轻易的嵌入替换现有网络架构的卷积,比如1x1卷积, 3x3卷积,组卷积以及深度卷积。与此同时,它与其他技术(如SE、ReLU6、Mish等)存在互补关系。
Training Strategy
训练深层动态卷积神经网络极具挑战,因其需要同时优化卷积核与注意力部分。下右图蓝线给出了DY-MobileNetV2的训练与验证误差,可以看到收敛较慢且性能仅为64.8%还不如其静态卷积版本的65.4%。
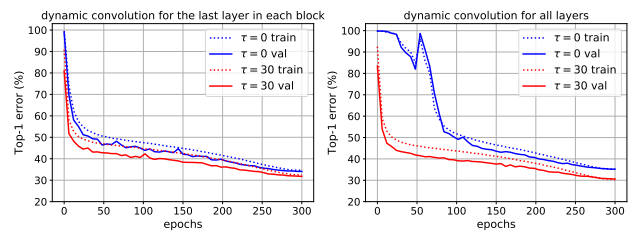
作者认为注意力的稀疏使得仅有部分核得到训练,这使得训练低效。这种低效会随着网络的加深而变得更为严重。为验证该问题,作者在DY-MobileNetV2变种模型(它仅在每个模块的最后1x1卷积替换为动态卷积)上进行了验证,见上左图。可以看到训练收敛更快,精度更高(65.9%)。
为解决上述问题,作者提出采用平滑注意力方式促使更多卷积核同时优化。该平滑过程描述如下:
从上图可以看到,改进的训练机制可以收敛更快,精度更高。
3. DyNet
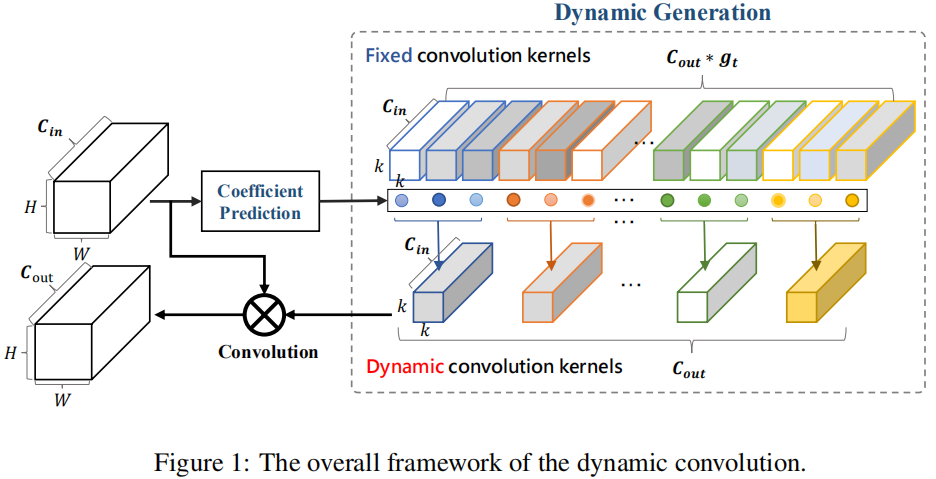
上图给出了作者所提动态卷积的整体框架。它包含系数预测模块与动态生成模块。该系数预测模块是可训练的并用于预测固定卷积核的融合系数;动态生成模块进一步利用所预测的系数生成动态卷积核。所提方法容易执行且“即插即用”,可轻易嵌入到现有网络中。
3.1 Motivation
正如已有网络剪枝技术所提,CNN中的卷积核存在相关性。作者给出了不同网络中特征的distribution of Pearson product-moment correlation coefficient,见下图。模型剪枝技术尝试通过压缩的方式降低相关性,然而难以压缩轻量型网络中的相关性。作者认为这种相关性对于性能保持很重要,因为他们需要通过协同方式得到噪声不相关特征。
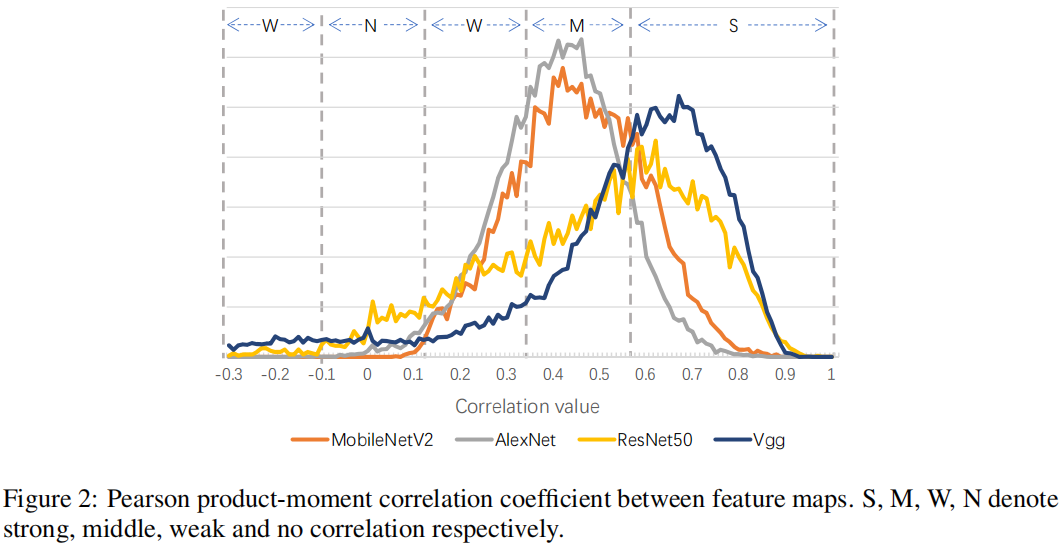
作者通过分析发现:可以通过多个固定核的动态融合得到该噪声不相关特征而无需多个相关核的协同组合。基于该发现:作者提出了动态卷积。
3.2 Dynamic Convolution
动态卷积的目标:学习一组核系数并用于融合多个固定核为一个动态核。作者采用可训练的系数预测模块预测系数,然后采用动态生成模块进行固定核融合。
-
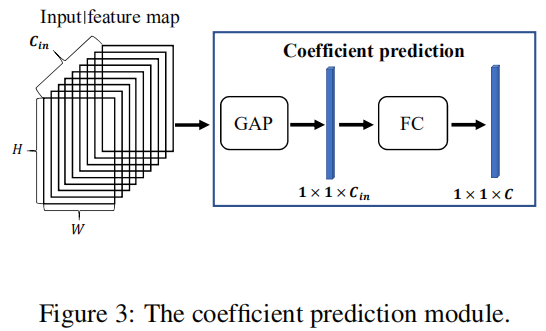
系数预测模块:它可以基于图像内容预测融合系数。该模块示意图见上图,它由全局均值池化与全连接层构成。注:C为固定卷积核数目,等同于后续公式中的 。 -
动态生成模块:对于动态卷积而言,它的权值为 ,对应 个固定核与 个动态核,每个卷积核的形状为 , 表示组数,它是超参数。假定 表示固定核, 表示动态核,动态卷积核的融合过程可以描述为:
-
训练算法:对于所提动态卷积而言,常规的batch训练算法并不适合。这是因为:同一个batch内,不同的输入具有不同的核。因此,作者提出在训练阶段基于系数融合特征,而非核。而这两种方式是等价的,证明如下:
4. 分析
前面已经介绍了CondConv、DynamicConvolution、DyNet的原理,各位有没有感觉到这三者就是一回事?
是的,从本质上来看,三者是相同的,都是根据输入自适应进行多卷积核融合,融合机制也是相同的,确实看不到三者有什么本质上的区别。
当然也存在一些区别,这些区别表现在这样几个方面:
-
出发点是不一样的。CondConv的出发点可以理解为“三个臭皮匠顶个诸葛亮”;DynamicConv的出发点是注意力机制;而DyNet的出发点则是“noise-irelevant feature”。也许这就是所谓的“殊途同归”吧。 -
网络架构搭建不一样。CondConv与DynamicConv是卷积层面的“即插即用”,而DyNet则是Block层面的嵌入。 -
训练方式不一样:CondConv采用的是常规训练并将Batch嵌入到Channels层面采用组卷积实现;DynamicConv则是考虑到训练难度问题(该问题其他两个方法并未提到)并提出了解决方案;DyNet则是考虑到了batch训练方式的不适用,提出训练阶段的特征融合方案。 -
代码开源方面:截止目前只有CondConv进行了开源,而其他两个并未开源; -
模型对比方面:后提出的方案并未与早提出的方法进行对比,比如CondConv最早提出,但是DynamicConv与DyNet均未与其进行对比,DyNet起码还提了一下前两者,而DynamicConv却并未提到CondConv,着实不应该啊。
5. Conclusion
本文所谷歌、华为以及MSRA等大厂提出的多卷积核自适应融合的动态卷积进行了简单介绍,最后从不同角度对比说明了三者之间的区别与联系等。
从时间上来说,谷歌的CondConv最早提出,MSRA的DynamicConvolutin次之,华为的DyNet最后。但DyNet文中有提到:“This technique has been deployed in HUAWEI at the beginning of 2019, and the patent is filed in May 2019 as well”。具体不得而知,但是从paper发表时间来看谷歌的CondConv无疑最早,后两者未与其进行对比说明,不知是何原因,不得而知。
从网络架构角度来说,谷歌的CondConv与MSRA的DynamicConv是简单的“即插即用”;而华为的DyNet则更进一步,在block层面进行调整,更有利于高效网路架构设计。
从开源复现角度来说,谷歌的CondConv进行了开源并提供的预训练模型,而其他两者并无开源代码。从这个角度来看,无疑谷歌的CondConv更显大气,哈哈,私认为“不开源就是耍流氓”,哈哈......
最后,本人还是非常期待MSRA与华为能尽快开源代码与预训练模型,期待...
推荐阅读:

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:AI移动应用-小极-北大-深圳),即可申请加入AI移动应用极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~

