【清华ACL2020长文】KdConv:多领域知识驱动的中文多轮对话数据集
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要6分钟
跟随小博主,每天进步一丢丢


整理:机器学习算法与自然语言处理公众号
编辑 | 贾伟


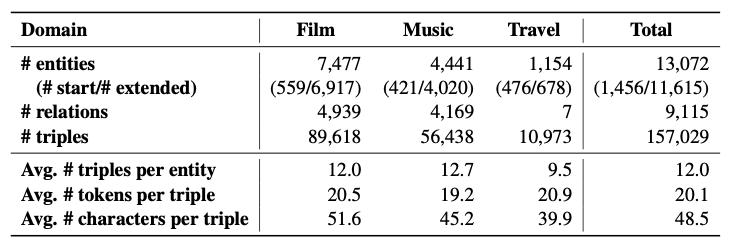
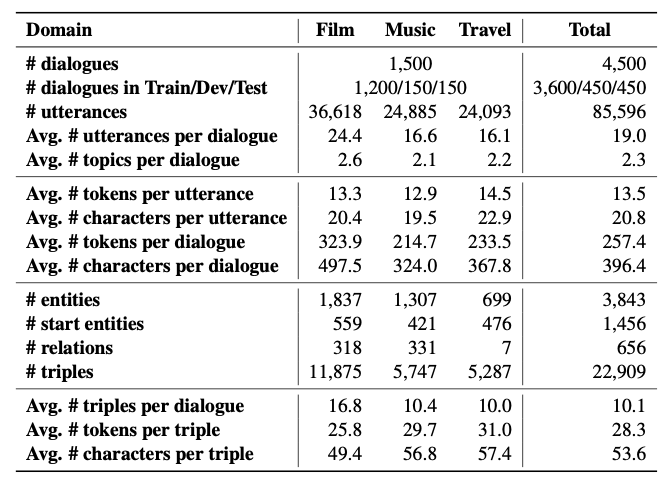
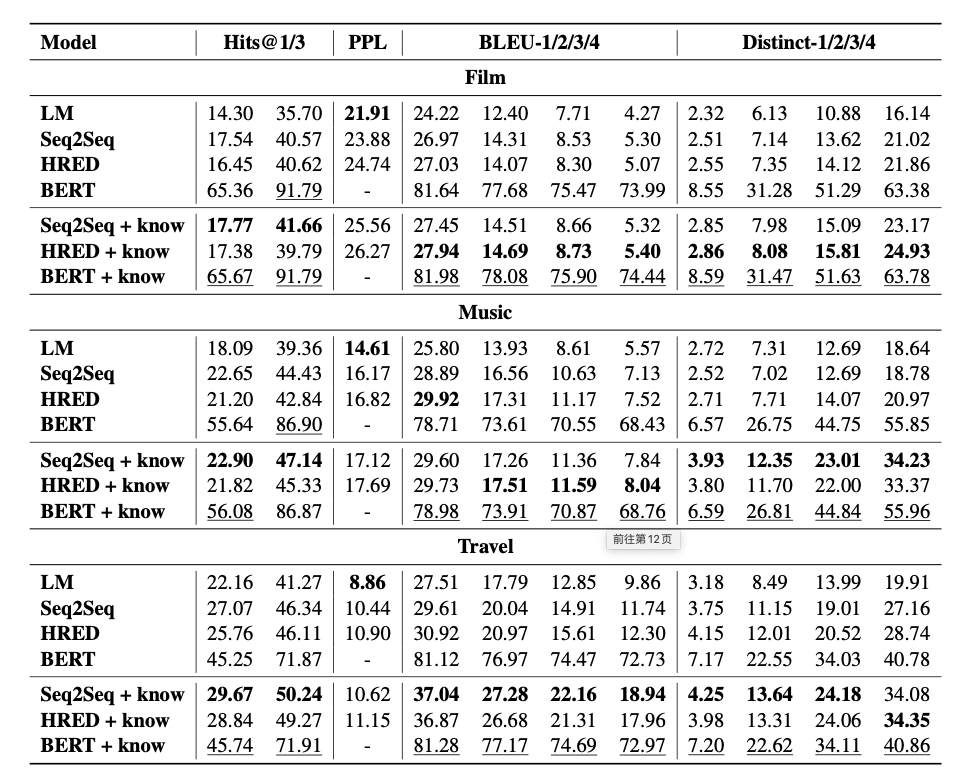


登录查看更多
相关内容


相关VIP内容
相关资讯
相关论文