442个作者100页论文!谷歌耗时2年发布大模型新基准BIG-Bench | 开源
白交 发自 凹非寺
量子位 | 公众号 QbitAI
一篇AI论文,442个作者。
其中还专门留了一章节写作者贡献。
100页里超过一半都是参考文献……
不是,现在都流行这样式儿的论文吗?
这不,谷歌最新发布的论文——Beyond The Imitation Game: Quantifying And Extrapolating The Capabilities Of Language Models。
于是作者那一栏就变成了这样……

来自132个机构的研究学者,耗时两年提出了一个大语言模型新基准BIG-bench。
并在此基础上评估了OpenAI的GPT模型,Google-internal dense transformer架构等,模型规模横6个数量级。
最终结果显示,模型性能虽然随着规模的扩大而提高,但跟人类的表现相差还很远。
对于这项工作,Jeff Dean转发点赞:Great Work。

大语言模型新基准
来康康这篇论文究竟说了什么。
随着规模的扩大,模型的性能和质量都有一定的改进,这当中可能还存在一些变革性影响,但这些性能此前都没有很好的描述。
现存的一些基准都有一定的局限性,评估范围比较狭窄,性能分数迅速达到饱和。
比如SuperGLUE,在该基准推出后的18个月内,模型就实现了“超过人类水平”的性能。
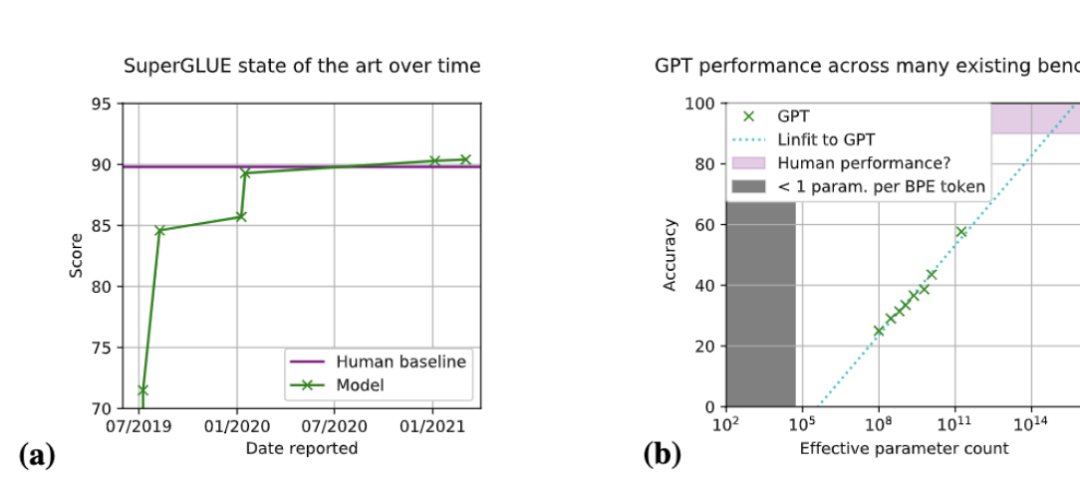
基于这样的背景,BIG-bench就诞生了。
目前它由204个任务组成,内容涵盖语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等方面的问题。
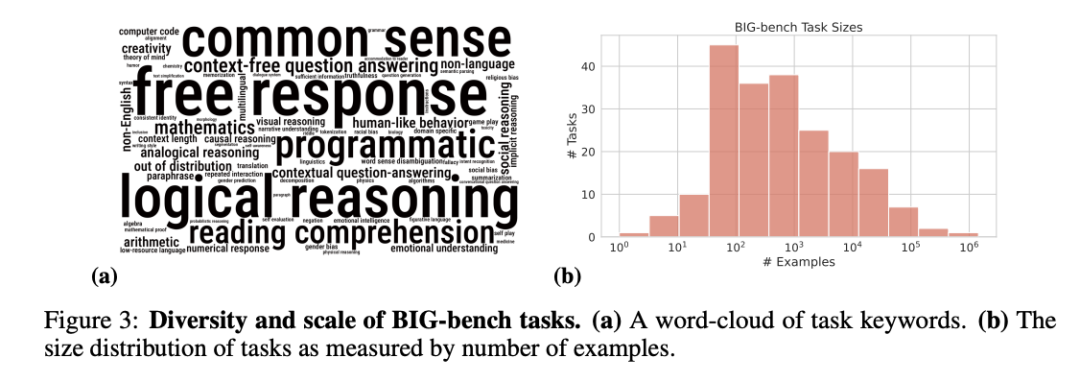
此外还有个人类专家评审团,也执行了所有任务,以提供基线水平。
为了方便更多机构使用,研究人员还给出了BIG-bench Lite,一个小型但有代表性的任务子集,方便更快地评估。

以及开源了实现基准API的代码,支持在公开可用的模型上进行任务评估,以及新任务的轻量级创建。
最终评估结果可以看到,规模横跨六个数量级,BIG-bench上的总体性能随着模型规模的扩大、训练样本数量的增加而提高。
但跟人类基线水平相比,还是表现得比较差。
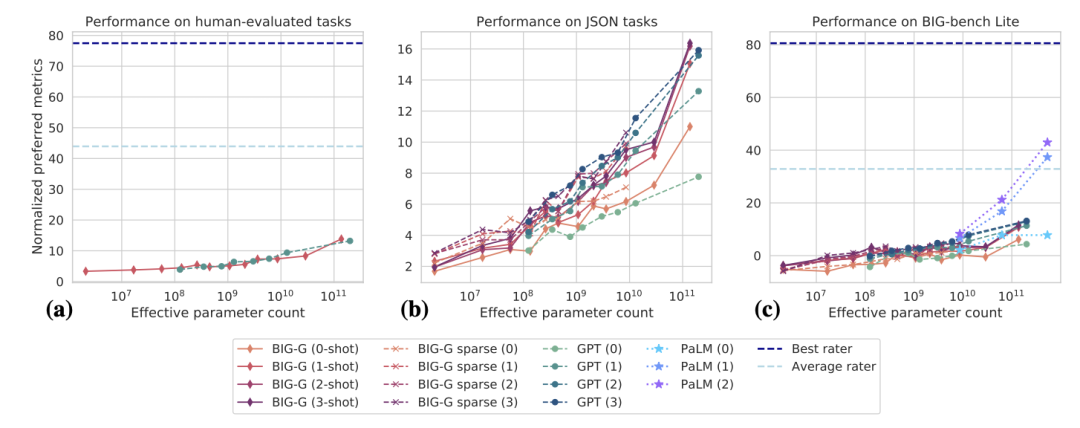
具体在一些任务上,模型性能会随着规模的增加而平稳地提高。但有时候,会在特定规模上突然出现突破性表现。
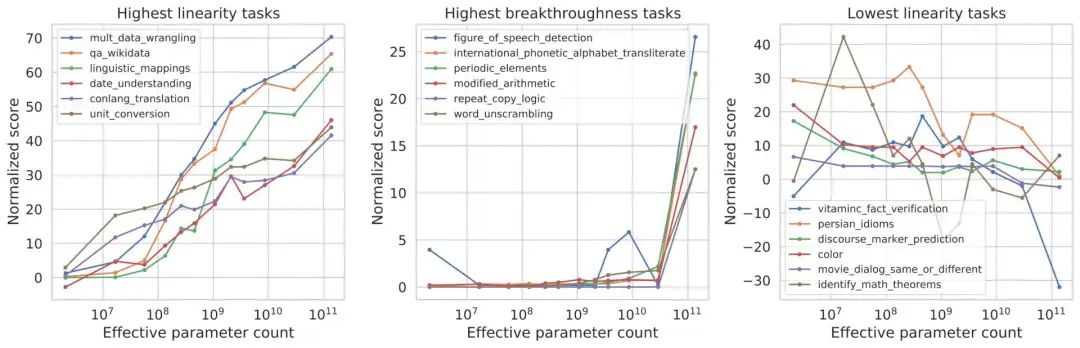
此外,它还可以评估模型存在的社会偏见。
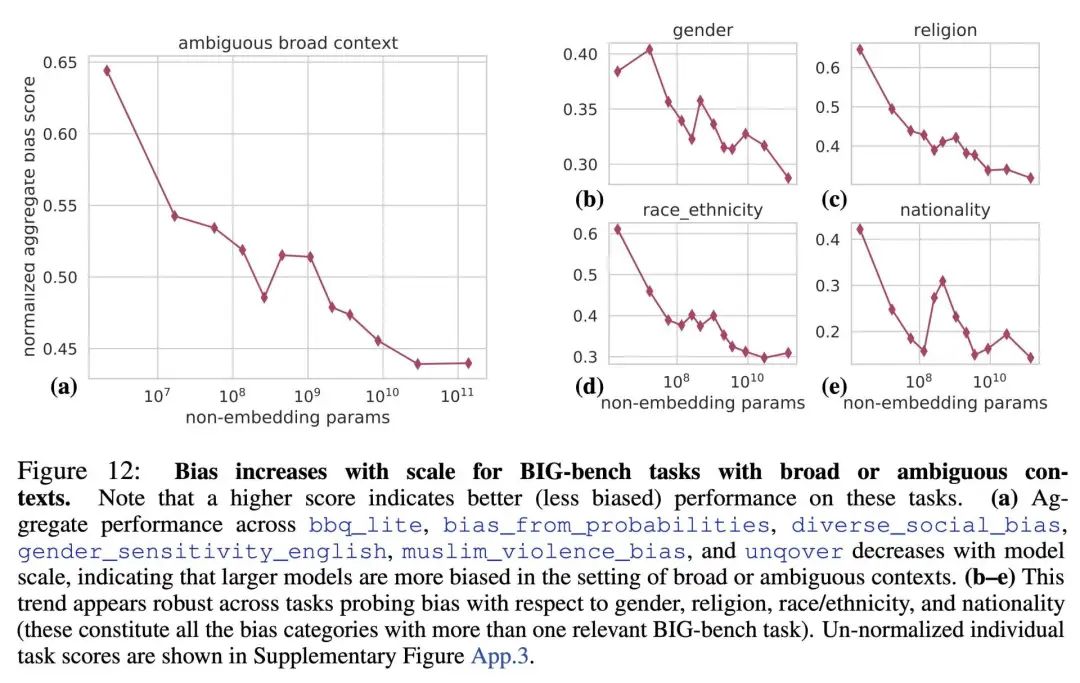
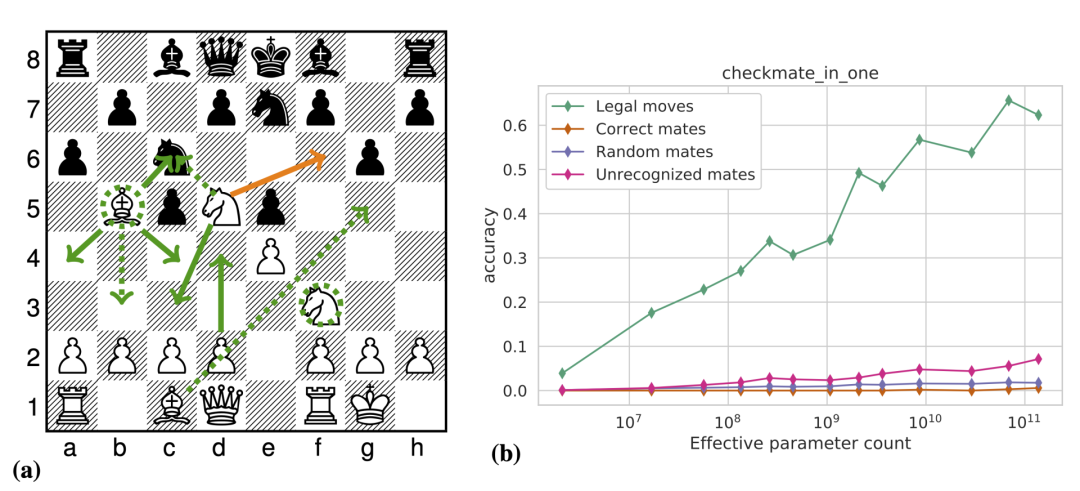
此外,他们还意外发现模型还可以get一些隐藏技能。比如,如何在国际象棋中合乎规则的移动。
作者贡献写了14页
值得一提的是,可能因为作者过多,论文最后还专门留了一章写作者贡献。
洋洋洒洒的写了14页,其中包括核心贡献者、Review的、提供任务的……

剩下的,还有50页的参考文献。
好了,感兴趣的旁友可戳下方链接康康论文。
论文链接:
https://arxiv.org/abs/2206.04615
GitHub链接:
https://github.com/google/BIG-bench
参考链接:
https://twitter.com/jaschasd/status/1535055886913220608
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



