「找到一项任务,越大的模型反而表现越差,你就有机会拿走 10 万美元的奖金。」这是纽约大学的几位研究人员组织的一项另类竞赛。
![]()
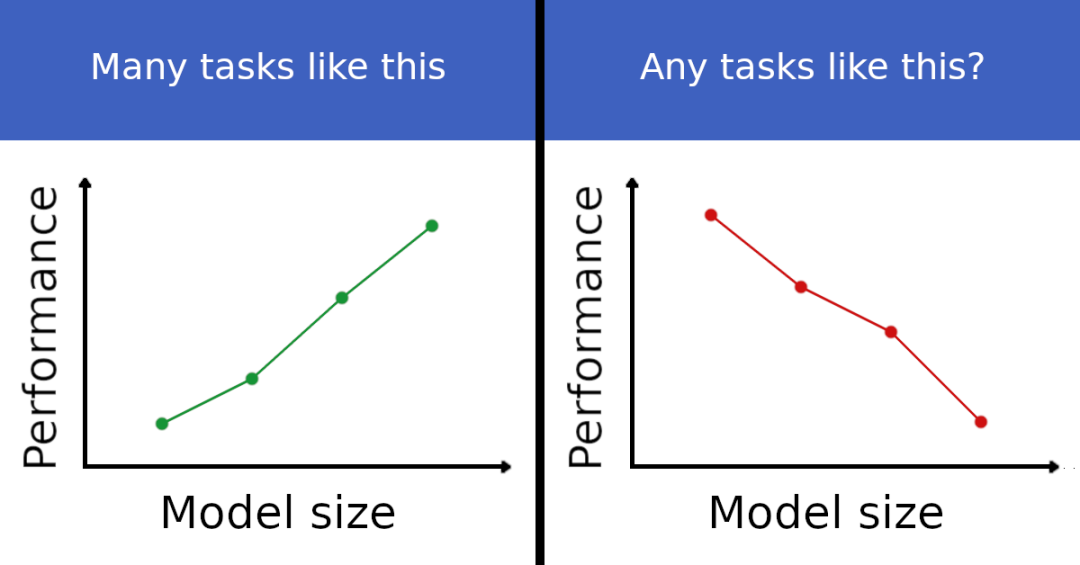
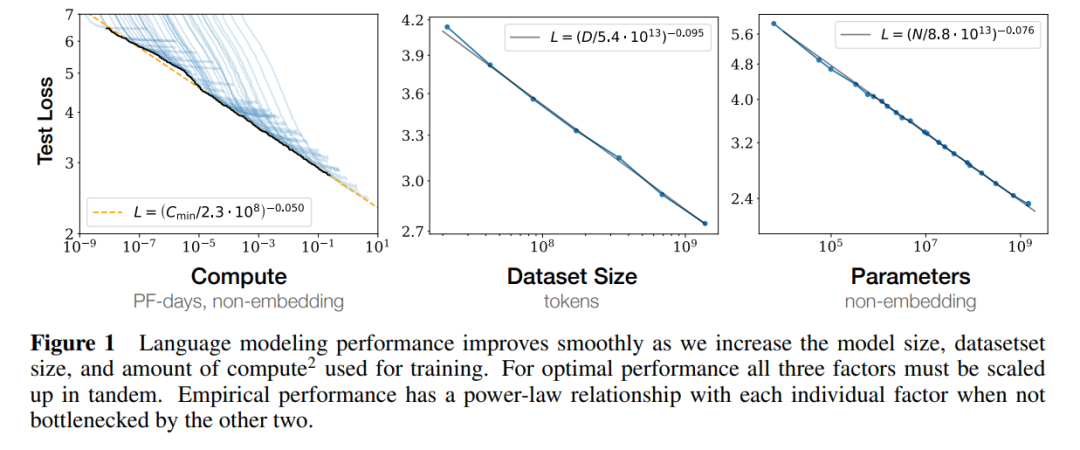
随着语言模型变得越来越大(参数数量、使用的计算量和数据集大小都变大),它们的表现似乎也原来越好,这被称为自然语言的 Scaling Law。
![]()
但是,这些模型也有自己的缺陷,比如存在偏见、可能产生看似合理实则错误的信息。这项竞赛的目的就是要找到一些大模型不擅长的例子。
组织者将这些现象称为 inverse scaling。这样的例子似乎并不常见,但确实也能找到了一些。比如在问答任务中,如果在提问的同时加上你的信仰,大模型会更容易受到影响。其他可能的例子还包括模仿 prompt 中的错误 / bug 或重复常见的错误概念。这些例子能让我们了解当前语言模型预训练和缩放范式的潜在问题,还可以为改进预训练数据集和目标提供灵感。
比赛共有两轮,第一轮截止时间是 2022 年 8 月 27 日,第二轮截止时间是 2022 年 10 月 27 日。
![]()
-
确定一个疑似显示了 inverse scaling 的任务;
-
-
使用 Colab notebooks,用 GPT-3/OPT 测试你的数据集的 inverse scaling。
提交的作品将根据 AnthropicAI(一家非营利 AI 安全研究公司)提供的一系列私人模型进行评估,奖项将由一个匿名评审团决定。
其中,一等奖一名,奖金为 10 万美元;二等奖五名,奖金 2 万美元;三等奖 10 名,奖金为 5000 美元。总奖金池为 25 万美元。
比赛结束后,组织方将撰写一份结果调查报告,并发布一个包含已接受任务的基准,获奖者将被邀请为论文的共同作者。
![]()
项目链接:https://github.com/inverse-scaling/prize
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com