用自洽性提升大模型推理能力,谷歌解答基准中75%数学问题,比GPT-3提升20%
编辑:小舟、杜伟
近日,谷歌研究者提出一种名为「self-consistency」(自洽性)的简单策略,不需要额外的人工注释、训练、辅助模型或微调,可直接用于大规模预训练模型。
尽管语言模型在一系列 NLP 任务中取得了显著的成功,但它们的推理能力往往不足,仅靠扩大模型规模不能解决这个问题。基于此,Wei et al. (2022) 提出了思维提示链(chain of thought prompting),提示语言模型生成一系列短句,这些短句模仿一个人在解决推理任务时可能采用的推理过程。
现在来自 Google Research 的研究者们提出了一种称为「自洽性(self-consistency)」的简单策略,它显著提高了大型语言模型的推理准确率。

论文地址:https://arxiv.org/pdf/2203.11171.pdf
该论文的作者之一、Google Brain 的创始成员 Quoc Le 今天在推特上发文表示:这种自洽方法能够解决 GSM8K 基准中 75% 的数学问题,大幅超越现有方法。
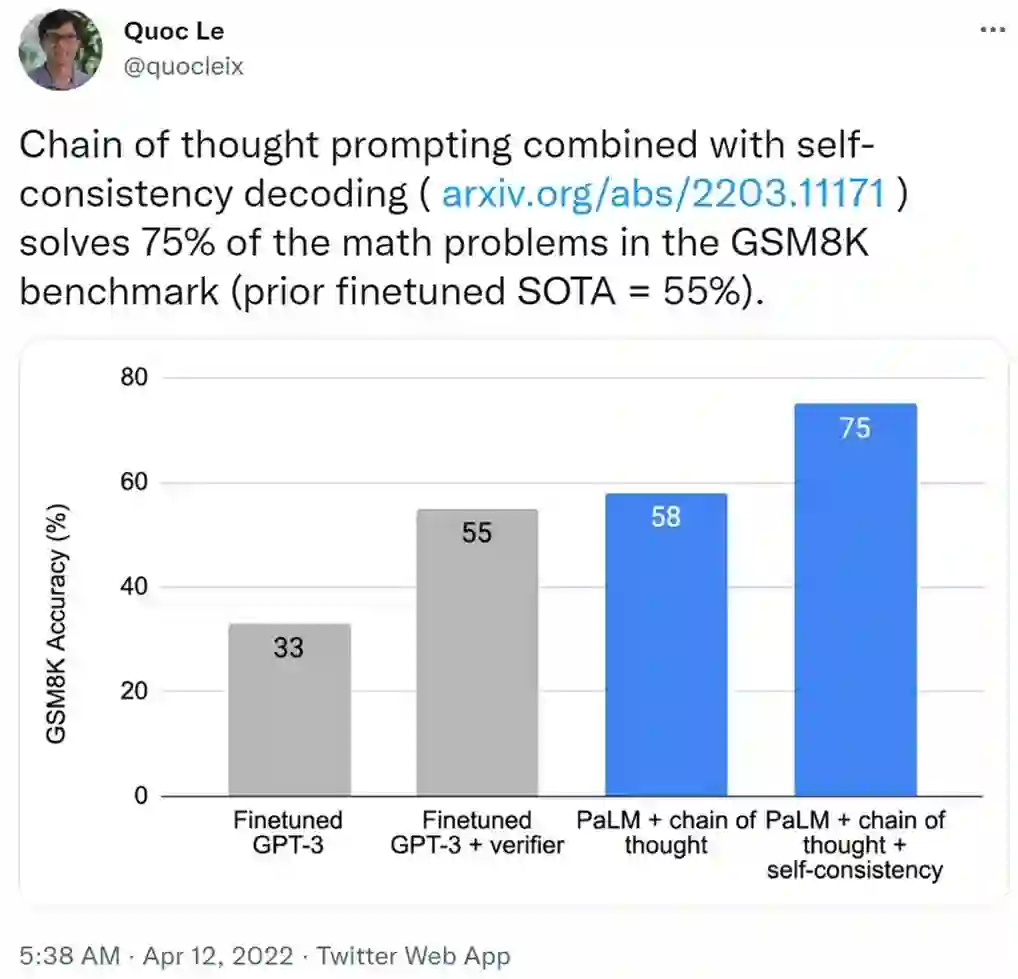
图源:https://twitter.com/quocleix/status/1513632492124663808
简单来说,复杂的推理任务通常有多个能得到正确答案的推理路径,自洽方法通过思维提示链从语言模型中采样一组不同的推理路径,然后返回其中最自洽的答案。
该方法在一系列算术和常识推理基准上评估自洽性,可以稳健地提高各种语言模型的准确性,而无需额外的训练或辅助模型。当与最近的大型语言模型 PaLM-540B 结合使用时,自洽方法将多个基准推理任务的性能提高到 SOTA 水平。
该方法是完全无监督的,预训练语言模型直接可用,不需要额外的人工注释,也不需要任何额外的训练、辅助模型或微调。
该研究在三种大型语言模型上评估一系列算术推理和常识推理任务的自洽性,包括 LaMDA-137B (Thoppilan et al., 2022)、PaLM-540B (Chowdhery et al., 2022) 和 GPT-3 175B (Brown et al., 2020)。研究者发现,对于这几种规模不同的语言模型,自洽方法都能显著提高其推理能力。与通过贪心解码(Wei et al., 2022)生成单一思维链相比,自洽方法有助于在所有推理任务中显著提高准确性,如下图 2 所示。
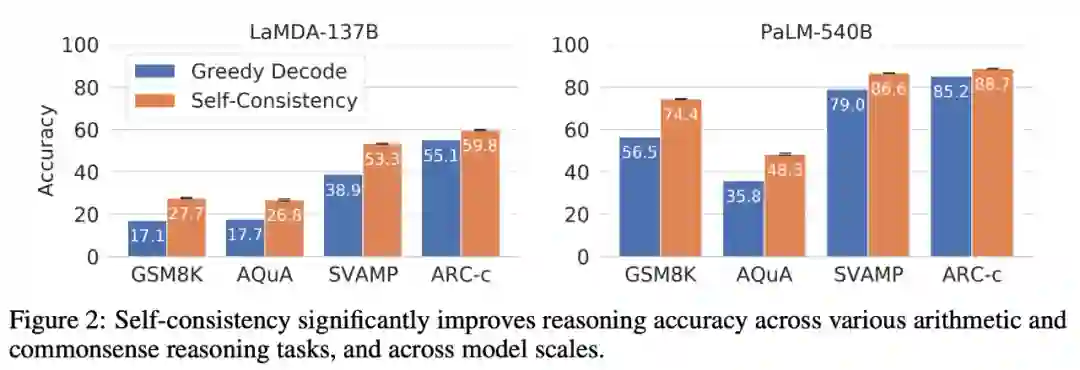
多样化推理路径上的自洽
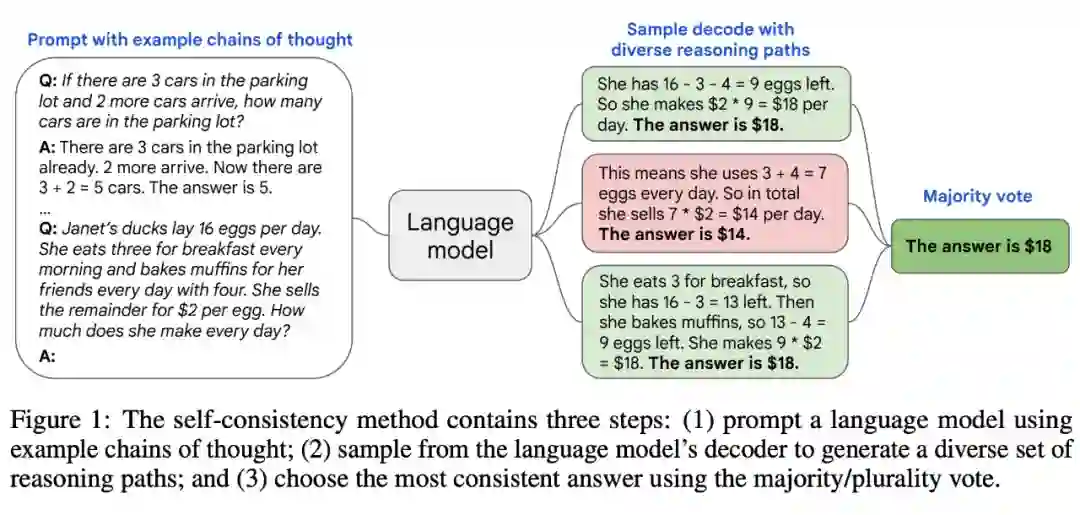
人类的一个突出特征是思维方式不同。人们会很自然地假设,在需要深思熟虑的任务中,可能有几种解决方法,所有这些方法都会得出相同的正确答案。因此,研究者建议可以通过从语言模型解码器采样以在语言模型中模拟这一过程。
如下表 1 所示,一个模型可以为一个数学问题生成多个可能的回答,这些回答最终得出相同的正确答案(如输出 2、4 和 5)。由于语言模型不是完美的推理器,模型也可能产生错误的推理路径或者在某一个推理步骤中出错(例如输出 1 和 3 中),这种解决方案不太可能得出相同的答案( 表 1 中的 26 和 14)。
也就是说,当假设推理过程正确,即使它们是多样化的,在最终答案中往往比不正确的推理过程具有更高的一致性。

研究者提出通过一种自洽(self-consistency)方法来利用这种直觉。具体步骤如下:
首先,使用一组手动编写的思维链示例对语言模型进行提示;
接着,从语言模型的解码器中采样一组候选输出,生成一组不同的候选推理路径;
最后,通过在生成的答案中选择最自洽的答案来集成结果。
在实验调查中,研究者发现思维链提示与相结合,会比单独使用仅考虑单一生成路径的思维链产生好得多的结果。
实验结果
研究者进行了一系列实验,以在不同的算术和常识推理基准上将提出的自洽方法与现有方法进行比较。结果发现,该方法极大地提高了每种语言模型的推理准确性,涵盖了广泛的模型尺度。
具体地,他们评估了不同推理路径上的自洽性,即自洽性(多路径)(Multipath)。结果取 10 次运行的平均值,在每次运行中独立于解码器对 40 个输出进行采样。比较的基线是贪心解码单个思想链,称为贪心解码(Single-path),之前已被用于大型语言模型中的解码。
算术推理结果如下表 2 所示。对于 LaMDA-137B,自洽性策略在每个任务上较贪心解码(Single-path)均实现了显著的性能提升,在 AddSub、ASDiv、AQuA 和 GSM8K 任务上获得接近 10% 绝对准确率提升,在 MultiArith 和 SVAMP 任务上分别提升了 23.9% 和 14.4%。
对于更大的 PaLM540B 模型,自洽性策略显著提升性能,在 ASDiv、AQuA、SVAMP 和 GSM8K 上实现了 7.9%、12.5%、7.6% 和 17.9% 的显著增益。
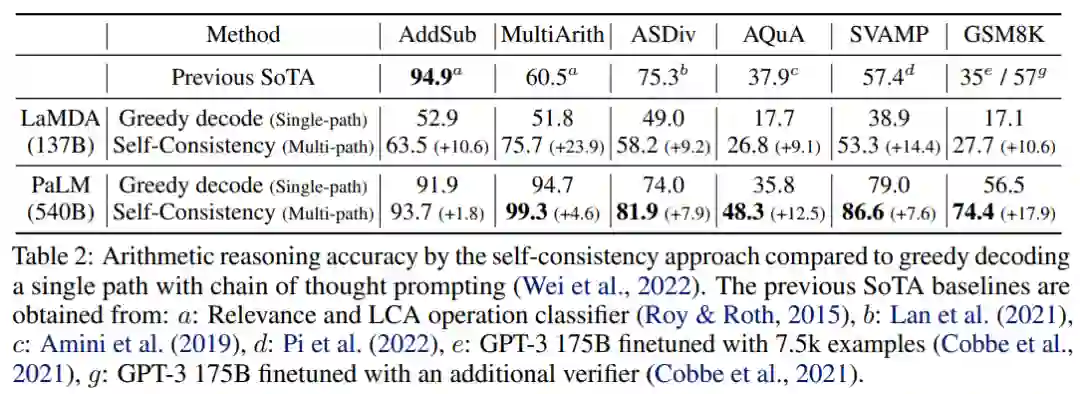
常识推理结果如下表 3 所示。对于 LaMDA-137B 模型,自洽性策略显著提升所有任务的准确率,其中 StrategyQA 和 CommonsenseQA 的绝对准确率提升了 2%-5%,ARC easy set 和 ARC challenge set 的绝对准确率分别提升了 4.0% 和 4.7%。
同样地,更大的 PaLM540B 模型也实现了持续收益,StrategyQA 上提升了 6.3%,ARC-challenge 上提升了 3.5%。
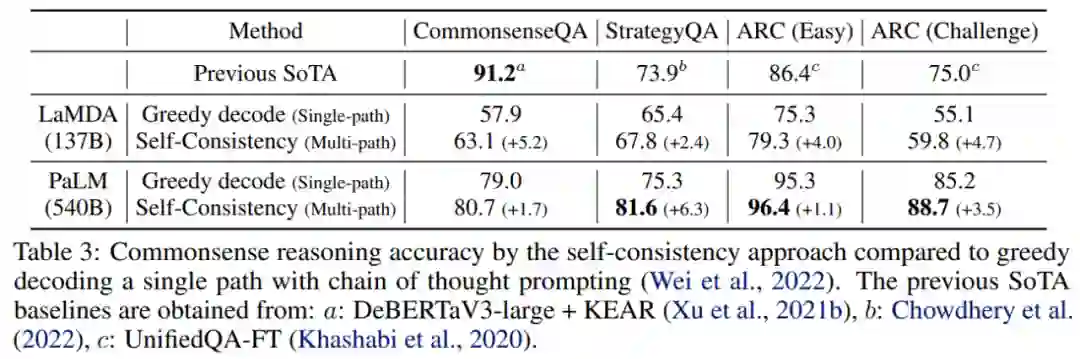
下图 3 中通过对来自解码器的不同数量的推理路径进行采样,展示了自洽性与贪心解码(Single-path)的性能比较。可以看到,采样更多数量(如 40 个)的推理路径始终会产生更好的性能,再次强调了在推理路径中引入多样性的重要性。
该研究将自洽方法和基于集成的方法进行小样本学习来比较二者的性能。结果如下表 5 所示,与自洽方法相比,基于集成的方法获得的增益要小得多。

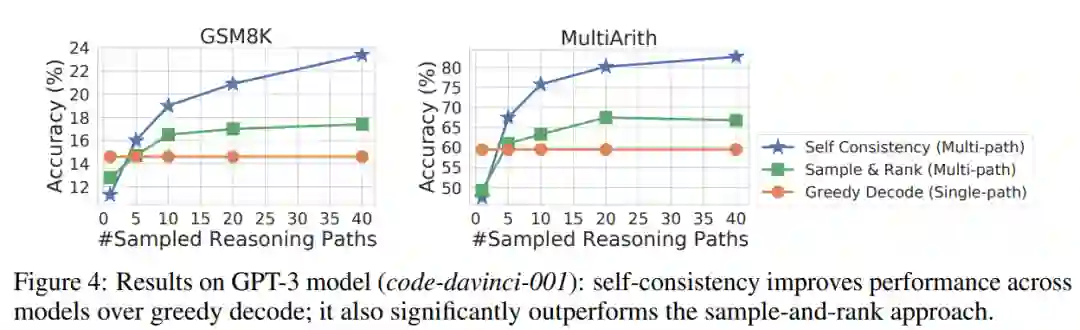
另一种提高生成质量的常用方法是采样排序(sample-and-rank),其中从解码器中采样多个序列,然后根据每个序列的对数概率或基于额外训练的重排序器进行排序。
该研究使用 GPT-3 模型得到了如下图 4 所示的结果。虽然采样排序方法通过额外的采样序列和排序提高了准确性,但与自洽方法相比,增益要小得多。
更多细节内容请参阅论文原文。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


