即插即用,Triplet Attention机制让Channel和Spatial交互更加丰富(附开源代码)

极市导读
本文介绍了一种新的注意力机制——Triplet Attention,它通过使用Triplet Branch结构捕获跨维度交互来计算注意力权重,是一个即插即用、简单高效的注意力模块。>>加入极市CV技术交流群,走在计算机视觉的最前沿

https://arxiv.org/abs/2010.03045
1、简介和相关方法
最近许多工作提出使用Channel Attention或Spatial Attention,或两者结合起来提高神经网络的性能。这些Attention机制通过建立Channel之间的依赖关系或加权空间注意Mask有能力改善由标准CNN生成的特征表示。学习注意力权重背后是让网络有能力学习关注哪里,并进一步关注目标对象。这里列举一些具有代表的工作:
2、CBAM(Convolutional Block Attention Module)
3、BAM(Bottleneck Attention Module)
4、Grad-CAM
5、Grad-CAM++
6、 -Nets(Double Attention Networks)
7、NL(Non-Local blocks)
8、GSoP-Net(Global Second order Pooling Networks)
9、GC-Net(Global Context Networks)
10、CC-Net(Criss-Cross Networks)
11、SPNet
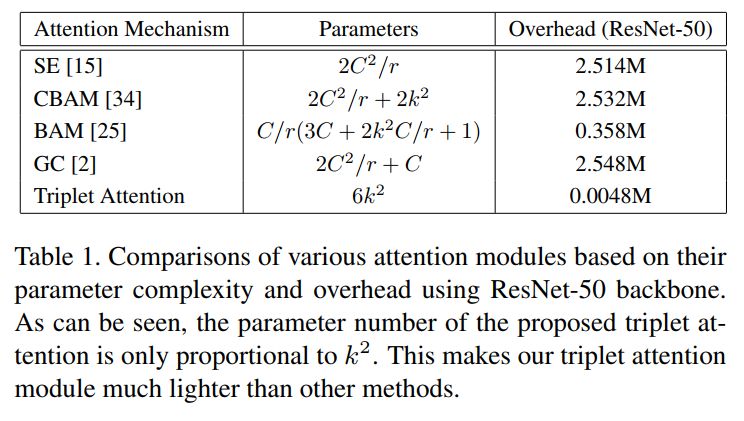
以上大多数方法都有明显的缺点(Cross-dimension),Triplet Attention解决了这些缺点。Triplet Attention模块旨在捕捉Cross-dimension交互,从而能够在一个合理的计算开销内(与上述方法相比可以忽略不计)提供显著的性能收益。
2、本文方法
2.1、分析
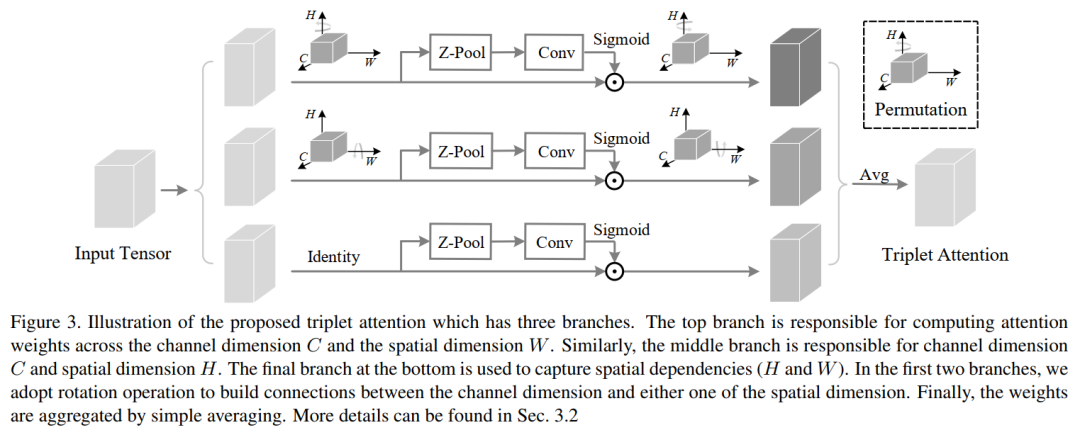
2.2、Triplet Attention
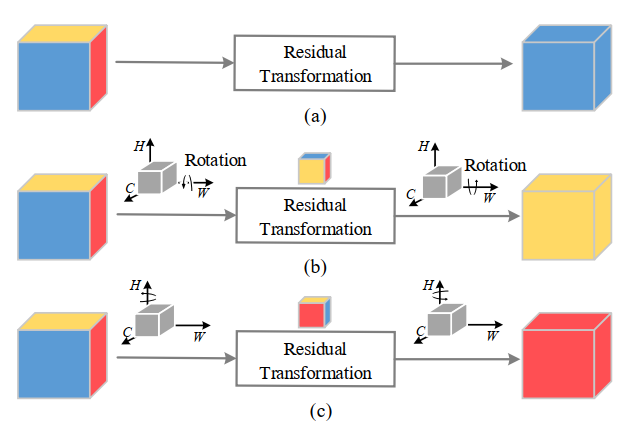
1、Cross-Dimension Interaction
2、Z-pool

class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat((torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=11)
3、Triplet Attention
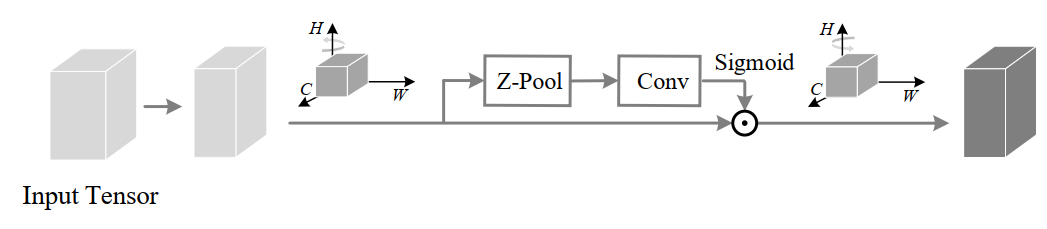
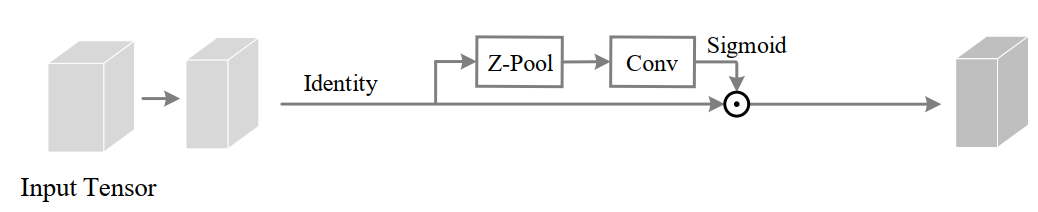 输入张量
的通道通过Z-pool将变量简化为2。将这个形状的简化张量(2×H×W)简化后通过核大小k定义的标准卷积层,然后通过批处理归一化层。输出通过sigmoid激活层生成形状为(1×H×W)的注意权值,并将其应用于输入
,得到结果
。然后通过简单的平均将3个分支产生的精细张量(C×H×W)聚合在一起。
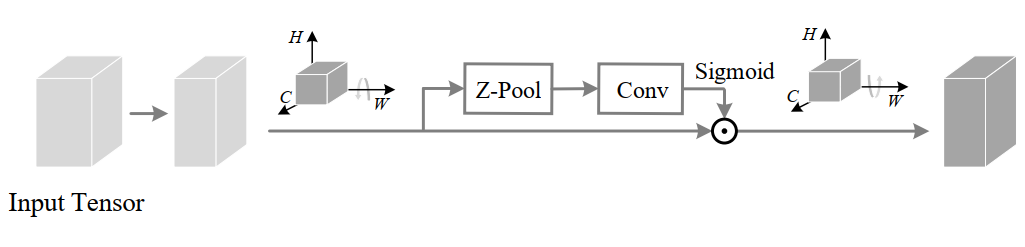
输入张量
的通道通过Z-pool将变量简化为2。将这个形状的简化张量(2×H×W)简化后通过核大小k定义的标准卷积层,然后通过批处理归一化层。输出通过sigmoid激活层生成形状为(1×H×W)的注意权值,并将其应用于输入
,得到结果
。然后通过简单的平均将3个分支产生的精细张量(C×H×W)聚合在一起。
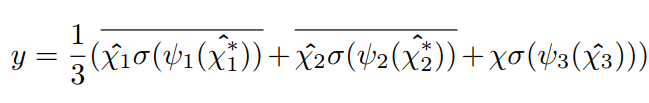
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes,eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 )
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
kernel_size = 7
self.compress = ChannelPool()
self.spatial = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = torch.sigmoid_(x_out)
return x * scale
class TripletAttention(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max'], no_spatial=False):
super(TripletAttention, self).__init__()
self.ChannelGateH = SpatialGate()
self.ChannelGateW = SpatialGate()
self.no_spatial=no_spatial
if not no_spatial:
self.SpatialGate = SpatialGate()
def forward(self, x):
x_perm1 = x.permute(0,2,1,3).contiguous()
x_out1 = self.ChannelGateH(x_perm1)
x_out11 = x_out1.permute(0,2,1,3).contiguous()
x_perm2 = x.permute(0,3,2,1).contiguous()
x_out2 = self.ChannelGateW(x_perm2)
x_out21 = x_out2.permute(0,3,2,1).contiguous()
if not self.no_spatial:
x_out = self.SpatialGate(x)
x_out = (1/3)*(x_out + x_out11 + x_out21)
else:
x_out = (1/2)*(x_out11 + x_out21)
return x_out
4、Complexity Analysis
3、实验结果
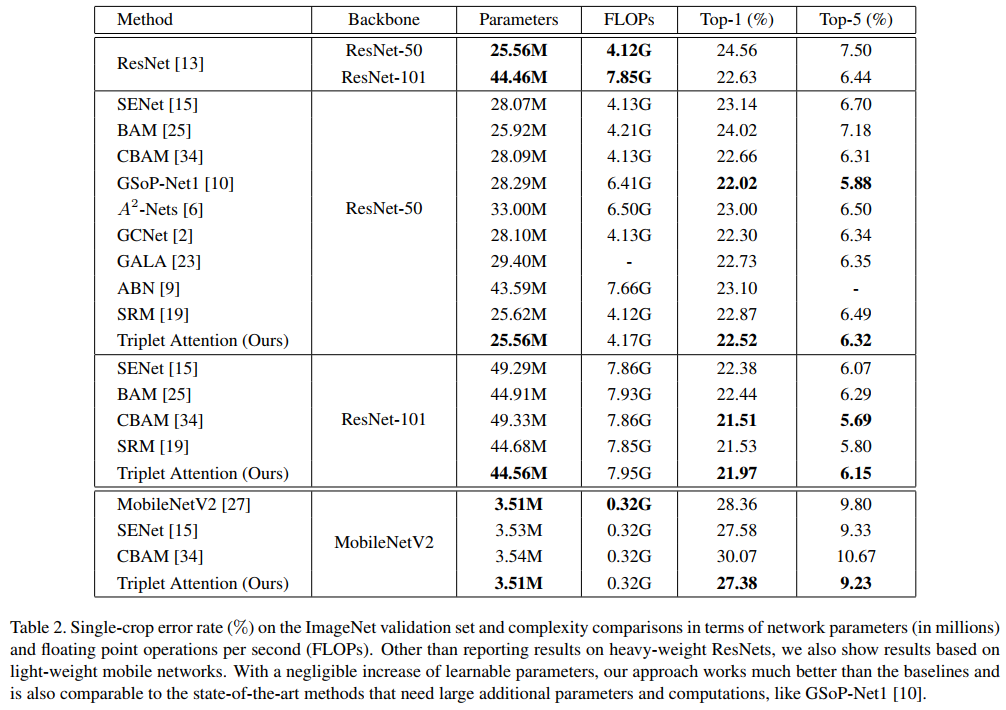
3.1、图像分类实验
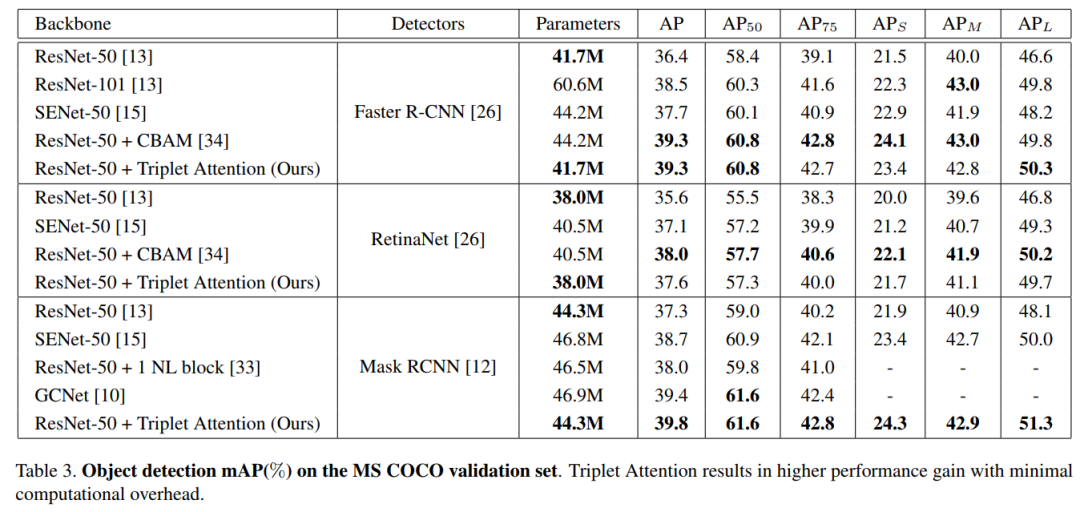
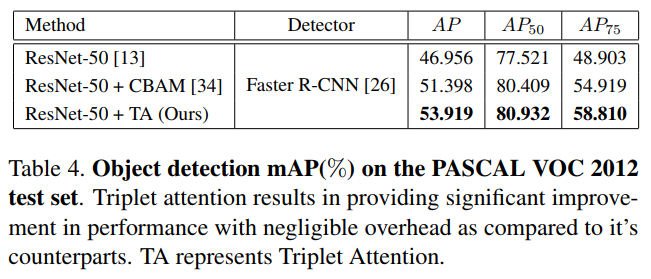
3.2、目标检测实验
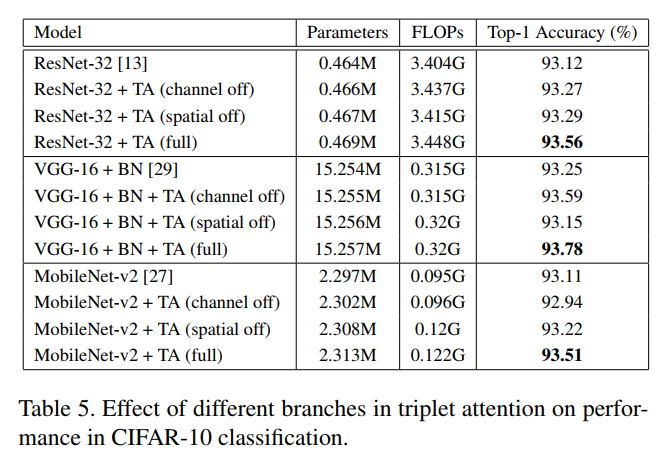
3.3、消融实验
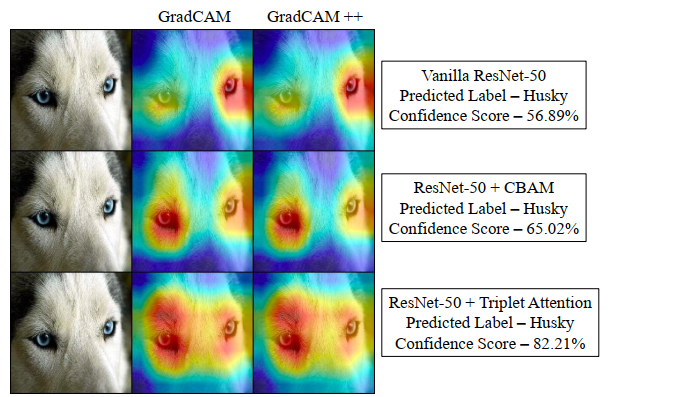
3.4、HeatMap输出对比
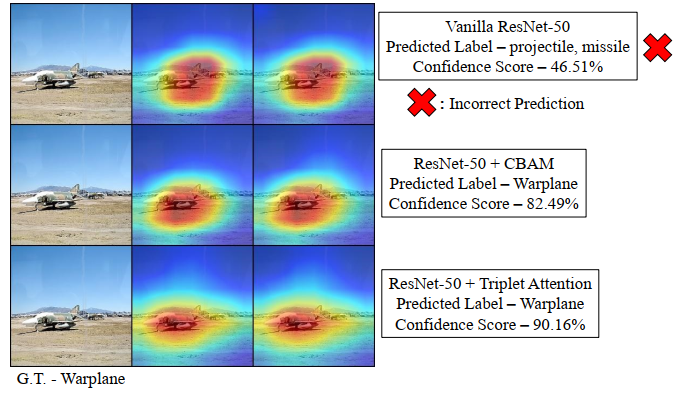
4、总结
在这项工作中提出了一个新的注意力机制Triplet Attention,它抓住了张量中各个维度特征的重要性。Triplet Attention使用了一种有效的注意计算方法,不存在任何信息瓶颈。实验证明,Triplet Attention提高了ResNet和MobileNet等标准神经网络架构在ImageNet上的图像分类和MS COCO上的目标检测等任务上的Baseline性能,而只引入了最小的计算开销。是一个非常不错的即插即用的注意力模块。
References
推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛正式开赛!







