新卷积运算 | 倍频程卷积降低CNNs的空间冗余(文末提供源码)
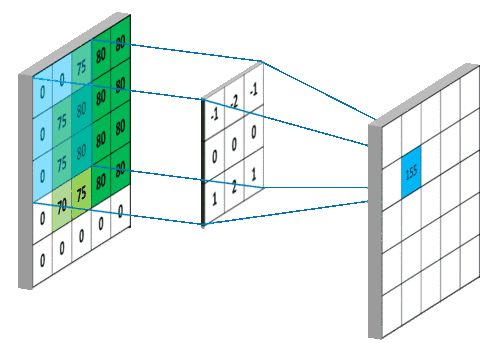

传统的卷积已经普遍被使用,现在陆续出现新的卷积方式,越来越高效,也越来越被他人认可,在性能方面也得到了较大的提升。
今天所要分享的是Facebook和新加坡国立大学联手提出的新一代卷积:OctConv(Octave Convolution),效果惊艳,即插即用。

OctConv如同CNN的“压缩器”,用它替代传统的卷积,不仅在提升效果的同时,还节约计算资源的消耗。
比如说一个经典的图像识别算法,替换其中传统卷积方式,在ImageNet上的识别精度可获得1.2%的提升,同时只需要82%的算力和91%的存储空间,如果对精度没有那么高的要求,和原来持平满足了的话,只需要一半的浮点运算能力就够了。
想实现这样的提升,怕不是要把神经网络改个天翻地覆吧?根本不需要,OctConv即插即用,无需修改原来的网络架构,也不用调整超参数,方便到家。就是这个新一代的卷积,让GAN的主要创造者、AI大牛Ian Goodfellow迫不及待,不仅转发力荐,还表示要持续关注进展,开源时再发推告诉大家。
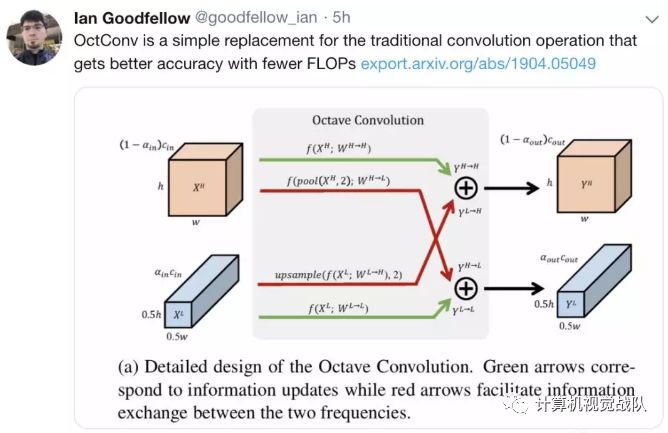
那接下来,我们就开始正式进入今天的主题——OctConv。有兴趣的我们一起来学习探讨,文末还提供了论文下载地址及源码。
在自然图像中,信息以不同的频率传递,其中较高的频率通常用精细的细节编码,而较低的频率通常是用全局结构编码。同样,卷积层的输出特征图也可以看作是不同频率下的信息混合。
本次新技术中,提出将混合特征映射按频率分解,并设计了一种新的倍频程卷积(OctConv)操作,以存储和处理空间上变化较慢、空间分辨率较低的特征映射,降低了内存和计算成本。与现有的多尺度方法不同,OctConv是一个单一的、通用的、即插即用的卷积单元,可以直接替代(Vanilla)卷积,而不需要在网络体系结构中进行任何调整。它也正交和互补的方法,建议更好的拓扑或减少像组或深度卷积信道冗余。
实验表明,简单地用OctConv代替卷积,可以不断提高图像和视频识别任务的精度,同时减少内存和计算量。装备OctConv的ResNet-152在ImageNet上仅需22.2GFLOPs就能达到82.9%的top-1分类精度。
卷积神经网络(Convolutional Neural network, CNNs)在许多计算机视觉任务中都取得了显著的成功,如:
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages
770–778, 2016.K. He, G. Gkioxari, P. Doll´ar, and R. Girshick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017.
X. Wang, R. Girshick, A. Gupta, and K. He. Non-local neural networks. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
近年来在降低DenseNet模型参数(F. Tung and G. Mori. Clip-q: Deep network compression learning by in-parallel pruning-quantization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7873–7882, 2018.)和特征图通道维数(Y. Chen, Y. Kalantidis, J. Li, S. Yan, and J. Feng. Multi-fiber networks for video recognition. In Proceedings of the European Conference on Computer Vision (ECCV), pages 352–367, 2018.)的固有冗余方面,其效率不断提高。然而,CNNs生成的特征图在空间维度上也存在大量冗余,每个位置独立存储自己的特征描述符,忽略了可以一起存储和处理的相邻位置之间的公共信息。

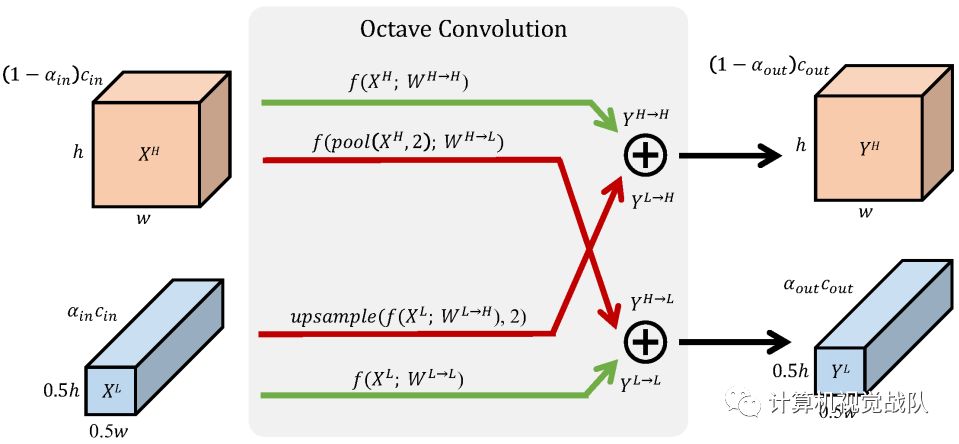
如上图所示,自然图像可以分解为描述平稳变化结构的低空间频率分量和描述快速变化精细细节的高空间频率分量。同样,我们认为卷积层的输出特征映射也可以分解为不同空间频率的特征,并提出了一种新的多频特征表示方法,将高频和低频特征映射存储到不同的组中,如下图左所示。
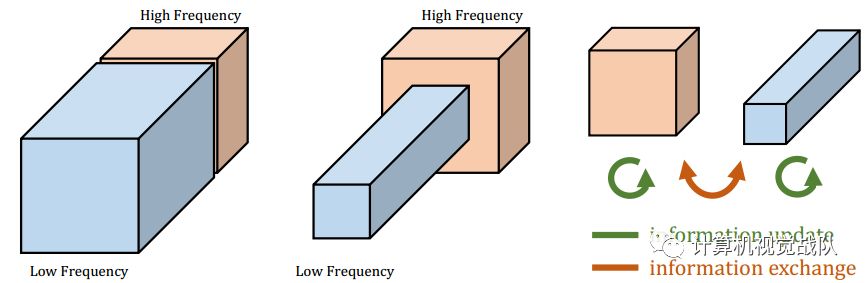
因此通过相邻位置间的信息共享,可以安全降低低频组的空间分辨率,减少空间冗余,如上图中所示。适应新的特征表示,推广了Vanilla convolution,并提出Octave Convolution(OctConv)将张量特征图包含两个频率和一个octave部分,频率和提取信息直接从低频图不需要解码的高频,如上图右所示。作为普通卷积的替代品,OctConv消耗的内存和计算资源大大减少。此外,OctConv对低频信息进行相应的(低频)卷积处理,有效地扩大了原始像素空间的感受野,从而提高了识别性能。
动机
最后,以一种通用的方式设计了OctConv,使它成为即插即用的卷积的替代品。OctConv主要集中在多个空间频率加工特征图和减少空间冗余、正交和现有互补的方法,专注于构建更好的CNN拓扑,减少channel-wise冗余卷积特征图和减少冗余在浓密的模型参数。
还将进一步讨论OctConv在group、depth-wise和3D卷积情况下的一体化。此外,与利用多尺度信息方法不同的是(C.-F. Chen, Q. Fan, N. Mallinar, T. Sercu, and R. Feris. Big-little net: An efficient multi-scale feature representation for visual and speech recognition. Proceedings of the Seventh International Conference on Learning Representations,
2019.),OctConv可以很容易地作为即插即用单元来替代CNN卷积,而不需要改变网络架构或进行超参数调优。
对于普通的卷积方法,以W表示k×k的卷积核,X和Y分别表示输入和输出张量,X和Y的映射关系为:
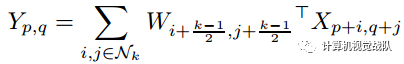
其中,(p, q)是X张量中的位置坐标,(i, j)表示所取的近邻范围。而OctConv的目标是分开处理张量中的低频和高频部分,同时实现高频和低频分量特征表示之间的有效通信,将卷积核分成两个分量:
W=[WH, WL]
同时实现高低频之间的有效通信,因此输出张量也将分成两个分量:
Y=[YH, YL]
YH=YH→H+YL→H,YL=YL→L+YH→L
其中YA→B表示从A到B的特征映射后更新的结果。YH→H和YL→L是频率内的信息更新,YL→H和YH→L是频率间的信息更新。因此YH不仅包含自身的信息处理过程,还包含从低频到高频的映射。为了计算这些项,将卷积核每个分量进一步分为频率内和频率间两个部分:
WH=WH→H+WL→H,WL=WL→L+WH→L
张量参数可以用更形象的方式表示:
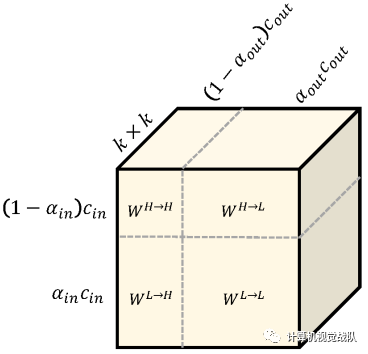
这种形式有些类似于完全平方公式a^2+b^2+ab+ba,两个平方项WH→H、WL→L是频率内张量,两个交叉项是频率间张量WL→H、WH→L:
输出张量的计算方式和前面普通卷积的方式相同:
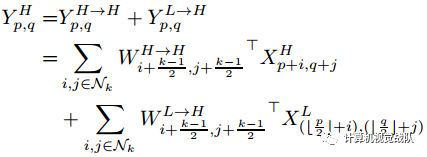
对于频率间通信,我们可以再次将特征张量x h的下采样折叠成卷积,如下所示:
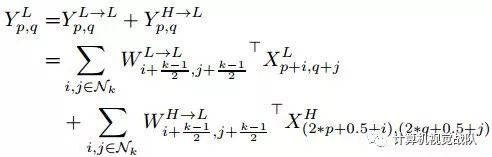
OctConv的另一个非常有用的特性是低频特征映射有较大的感受野。与普通卷积相比,有效地将感受野扩大了2倍。这会进一步帮助每个OctConv层从远处捕获更多的上下文信息,并且有可能提高识别性能。
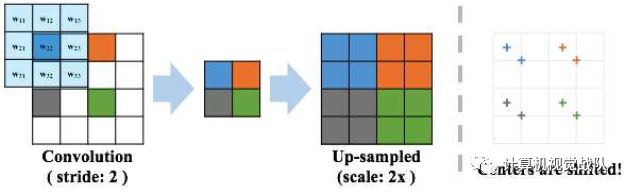
stride卷积会导致过采样后的特征图不对齐,如上图所示,stride卷积后的上采样将导致整个特征映射向右下角移动,将移位映射与未移位映射相加时,就会出现问题。因此,使用平均池化来近似这个值,用于本技术的其余部分。
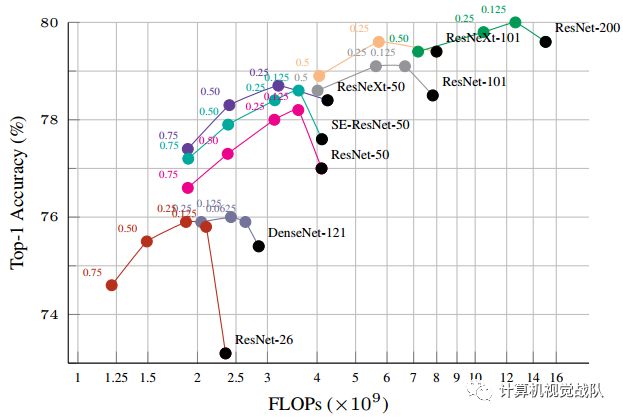
在ImageNet数据库上的Ablation study结果
表1 ResNet-50的结果
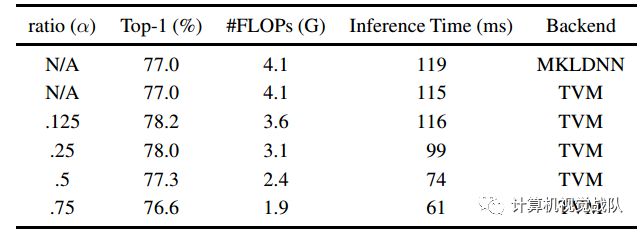
表2 在ImageNet上进行下采样和inter-octave连接的Ablation
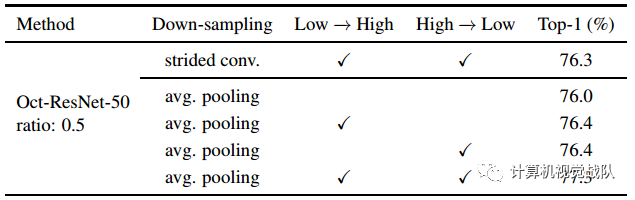
表3 ImageNet分类精度
还有更多的实验结果,见文末的论文链接
针对传统CNN模型中普遍存在的空间冗余问题,提出一种新颖的Octave Convolution提高了模型的效率。Octave卷积具有足够的通用性,可以代替常规的卷积运算,可以在大多数二维和三维CNNs中使用,无需调整模型结构。除了节省大量的计算和内存外,Octave Convolution还可以通过在低频段和高频段之间进行有效的通信,增大感受野的大小,从而获得更多的全局信息,从而提高识别性能。
在图像分类和视频动作记录方面进行了广泛的实验验证了新方法在识别性能和模型效率之间取得更好权衡的优越性。

论文地址:https://export.arxiv.org/pdf/1904.05049
源码:https://github.com/terrychenism/OctaveConv/
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。
我们开创一段时间的“计算机视觉协会”知识星球,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

微信学习讨论群也可以加入,我们会第一时间在该些群里预告!



