笔记 || AlphaStar学习笔记总结
深度强化学习实验室报道
作者:陈雄辉
编辑:DeepRL
AlphaStar是RL处理复杂决策问题的又一大新闻了。从War3到SC2,RTS一直是我的业余最爱,最近读了一下paper,也share一下里面使用的一些比较有趣的技术。@田渊栋 老师和 @张楚珩。
0.1 TL;DR
如果让我总结AlphaStar中成功的关键的话,我觉得有以下几点:
-
专家数据充分地用在了强化学习的各个过程中,有效降低了问题的复杂度。 -
Adversarial + population-based training 两种技术的综合使用,产生了较为鲁棒的策略; -
深度学习各领域近期的多项突破性研究在AlphaStar架构得到了充分整合应用,使得其学习算法到网络结构都有足够的能力来处理星际这样的复杂表征与决策问题
下面文章按照这三点进行展开介绍
0.2 StarCraft II 的问题和挑战
AlphaStar作用于星际争霸这款经典即时战略类游戏,简单来说,这是一个类军事对抗的游戏,游戏分为敌我双方,我方玩家作为一个指挥官,需要做4件事:
-
指挥手下的军队占领“资源产出据点”,采集“资源”; -
消耗拥有的资源“资源”,完成:建造“基础设施”、发展“科技”和产出各种“不同能力的军事单位” 三项工作。产出军事单位是最终目标,不同的基础设施和科技可以产生不同的军事单位,或为指定的军事单位增加某种能力; -
双方军事单位交战时,玩家需要实时控制自己的军事单位的布局(站位)、攻击目标、攻击形式,以最少损失去消灭敌方尽可能多的单位。 -
不同的军事单位存在相克关系,玩家需要不断侦查对手的军事单位和建筑布局,判断对手的生产战略,进而调整自己的指挥策略,以克制对手,为更好达到3. 的目的服务;
玩家最终目标是利用自己的军事单位,消灭所有敌方的军事单位和基础设施,从而赢得比赛。AlphaStar的目标是训练出一个可以战胜所有可能的策略的最强策略网络。作为一个强化学习的问题,其之所谓困难, 至少有以下几个原因:
-
鲁棒性要求高 这是一个有很强的策略与反策略的游戏,学习打败某种策略相对容易,学习一个可以应对多种战术的策略非常难,这件事情无法直接通过简单的self-play 来解决; -
复杂的感知任务 智能体需要感知的信息有三维游戏世界地图信息、大量的军事单位、每一个军事单位和建筑的属性信息以及自身的一些资源属性信息; -
复杂的动作和决策空间 游戏动作维度本身很高,观测信息是部分可知的(我们无法完全知道对手目前的状态),且一场游戏的决策步数非常多,且策略过程非常复杂。
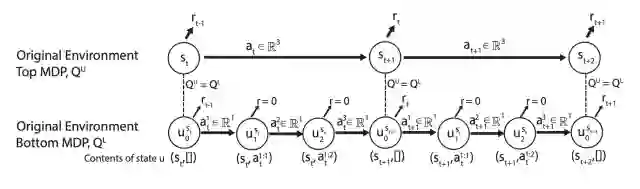
0.3 MDP建模
-
结构化建模动作空间:选择动作类型(攻击,行走,建造)->选择执行单位 -> 选择目标 -> 确定下一次动作执行时间 -
观测空间:所有可见的单位和其属性信息(考虑战争迷雾,不考虑屏幕信息)。小地图信息
整个交互过程如下:
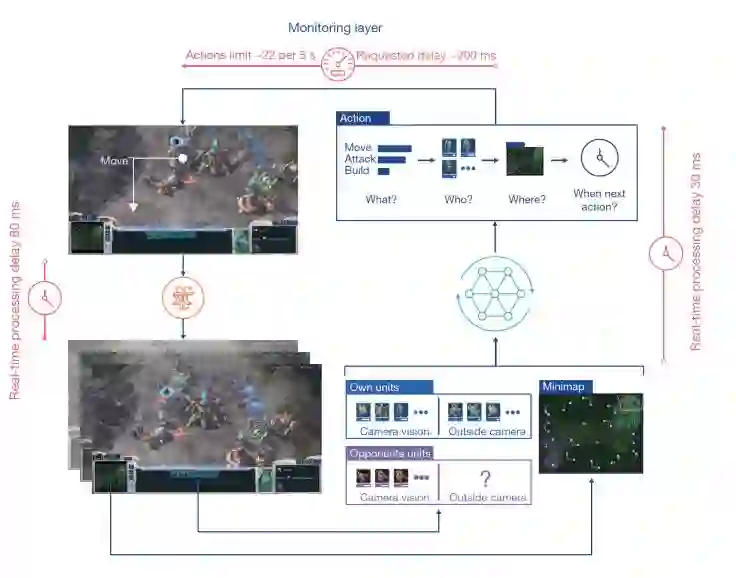
AlphaStar整体技术路线其实并不复杂:首先监督学习进行预训练,然后强化学习进行后续对抗训练。但是要真正得到AlphaStar的效果,其中便有很多门道,下面按照前面说的三个部分来进行具体来介绍ALphaStar的一些技术细节
1. 鲁棒训练:Adversarial + population
模型的鲁棒性是强化学习,也是机器学习经常要面对的问题。星际争霸也是对模型鲁棒性要求极高的场景,你可能很容易发现可以克制你目前的对手的一种战术,但是应对任何战术都能找到应对措施则是更困难的问题。AlphaStar的解决策略鲁棒性问题综合使用两种思路:
-
Population Based Training:Agent对手是一个League而不是自己(即self-play),League是一组对手策略池,这个对手池内的每个对手可能有完全不同的策略(战术)。Agent训练目标是要打败League中所有对手,而不是单纯做self-play打败自己当前的对手; -
Adversarial Training:对抗策略的整体目标是使得League更为robust(即没有策略可以打败League的全部策略),进而使得与League对抗的Main Agent更为robust。
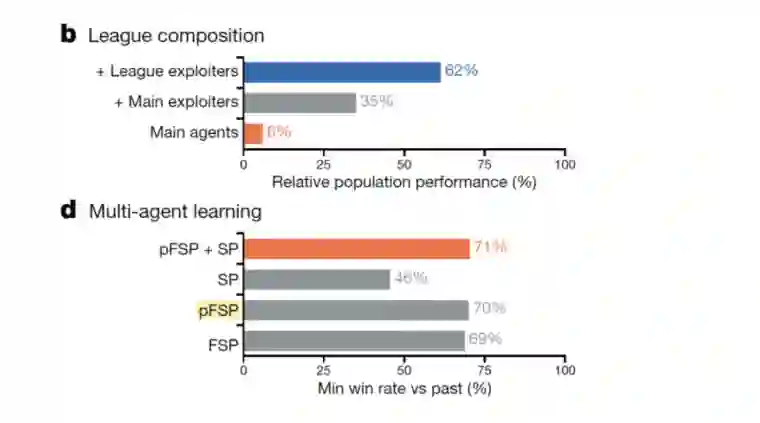
两个方法对于性能的提升起到了关键作用:下图 b中“+Main Exploiters”和“+League Exploiters”是增加了对抗训练后的相对性能,对比算法“Main agents” 只使用自我博弈策略作为League进行训练;d中pFSP和FSP便是增加了基于population的训练的相对性能,对比算法是直接进行self-play(SP)。
1.1 Prioritized fictitious self-play :一种种群策略采样机制
pfsp包括两个关键词,fictitious self-play和Priority。fictitious self-play agent需要打败历史上的所有对手,而不是仅仅打败自己。即我的对抗目标是一个对手集合Priority 我们在选择对手进行对抗时,越困难的对手有越大的优化权重,而不是所有对手有相同的权重进行优化,具体而言:
-
我们保存了一个payoff estimation,表示和池子里的player 对打的胜率矩阵,每一轮对抗后会进行更新 -
利用pay off estimation 来为任意两个player 选取的概率赋予权重,越困难的player有更高的权重被选取到。概率如下所示:

PS如果说 FSP 是 一个max-avg 的操作,PFSP则像是 一个soft 的max-min的操作,这本身也隐含了对抗训练的思想。
1.2 Adversarial:三组对抗目标生成三种对手池
AphaStar训练时有三种类型的对手池集合(Main Agents, League Exploiter, Main exploiters),区别只训练的目标不同。下面具体介绍三种对手池的训练方式:Main Agents: 训练目标是一个最强鲁棒策略,也是最后部署的策略。其具体训练目标有三种:
-
Main Agents 作为对手进行Self-Play (35%) -
所有league(包括三种对手集合)(50%) -
被遗忘的策略(历史的Main agent, 现在难以打败的),缺陷策略(stronger Main exploiters) (15%)
League exploiters 与League对抗,用于寻找League都无法打败的策略(比如发现一种新的进攻体系),也就是寻找历史Memory的弱点,不要求该策略是robust的,通过将找到的策略加入League,使得League更加鲁棒
Main exploiters 与当前Main Agents(的集合)进行对抗,用于寻找Main Agent的弱点,不要求该策略是robust的,但是该对抗策略可以使得Main Agent更加鲁棒,具体目标有两种:
-
50%概率,或者和当前Main Agent 胜率低于20%时,与Main Agent的集合使用PFSP进行对抗 -
50%概率与当前的Main Agent进行对抗
三种对训练方式都定期(2 *10^9 steps)将自己的权重快照加入League;另外,League Exploiter 和Main Exploiters 能够有70%概率击败他的对手时,将权重快照加入League中。
除了main agents 以外,Agent加入League后,会有一定概率重置为监督学习学到的智能体,其学习到的策略和人类策略差距太大,这个我认为主要是避免一些没必要的策略(e.g., 人类不可能使用的策略没有必要去想办法战胜)的对抗训练开销。
2. 专家数据的充分使用
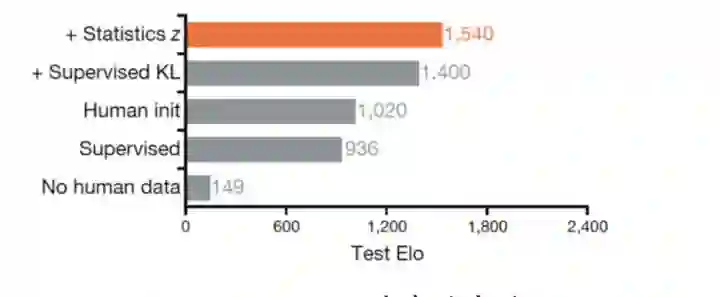
DeepMind对AlphaStar做了一组关于Expert Data的消融实验,结果非常有趣。下图横轴是性能指标,纵轴是不同的实验设置。我们可以得到以下几个结论:
-
没有人类数据的强化学习,在复杂环境中是很难有效果 -
仅仅使用监督学习,便可以达到不错的效果(是人类选手黄金段位的水平) -
充分利用人类数据后,AlphaStar的性能又提高了60% (Supervised KL, Statistics z)
可以看到人类数据在其中扮演了非常重要的作用。
那么如何利用人类数据,AlphaStar给出了一些不错的实践方向,整体来看有以下几点:
-
监督学习预训练模型 -
用人类数据约束探索行为,缩小探索空间,避免产生大量无效的探索/无用的采样; -
利用人类数据构造伪奖赏(pseudo-reward),引导策略(一定程度地)模仿人类行为,缓解稀疏奖赏的问题,加速策略训练; -
用人类数据约束对抗环境的生成,避免生成与真实情况差异过大的环境/对抗策略,缩小鲁棒训练时所需要的population的规模。
其中第一点使用了课程学习的trick,先使用天梯积分在3500(Top 22%)水平玩家的录像进行训练;最后再用天梯6200的水平玩家的录像进行策略微调。第四点在1.2 中已经提到过。第二、三两个主要通过一个统计量z实现的,下面具体介绍这个统计量
统计量 和基于 的辅助学习
是从人类对局数据抽取出来的统计量,包括:
-
1)建造顺序数据:比如建筑、升级的顺序等 ; -
2)累计数据:比如各个单位建造量等。
在强化学习和监督学习的过程中,所有的策略都会 conditional on。在强化学习的过程中,首先从replay 里面随机sample human data,得到对应的统计量 ,接着:
-
约束动作空间 基于该统计量,学习过程有一个loss用于最小化和有监督版本智能体的 KL,保证学习到的策略要一定程度相近于监督学习的模仿策略版本。 -
设计伪奖赏(pseudo-reward):根据累计统计量z和当前的游戏进行过程的累计统计量 的差异来计算pseudo-rewards,具体包括:
-
-
建造顺序计算编辑距离(edit distance); -
-
累计数据计算汉明距离(Hamming distance)
从这里可以看,AlphaStar一定程度上说是一种模仿学习上的成功。他所学到的是基于人类(顶尖人类)的对战轨迹下的一个鲁棒可泛化的策略。每次的对局所sample的 统计量 ,已经一定程度上限制的该智能体本场replay的整体策略选择范围(由建造顺序和单位累计顺序大致决定),AlphaStar做的是给定的策略选择范围 内学习如何应对其他对手策略。
3. 多项前沿技术的综合应用
3.1 感知层设计
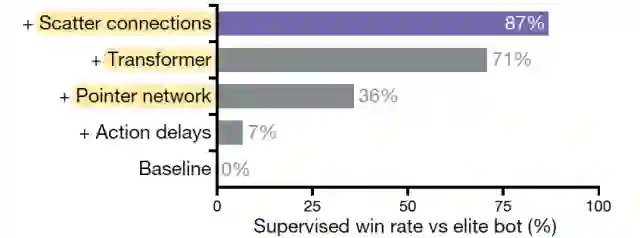
AlphaStar结合了很多近年来深度学习各个领域流行的研究成果来处理星际这个复杂问题。AlphaStar的实践验证,可为我们复用这些技术到其他类似领域提供很好的积淀。其网络结构如下图所示, 说几个我感兴趣的(详细结构的可以查看其公布的伪代码):
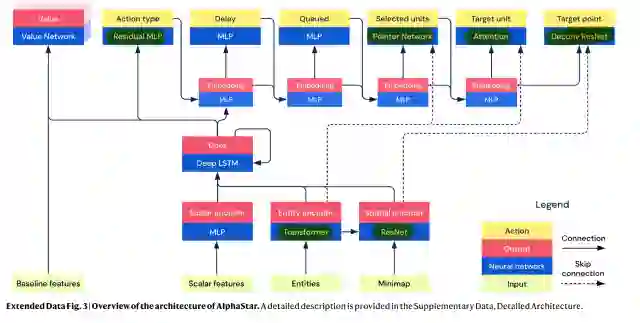
-
attention mechanism / transformer : Attention 和Transformer应该都很熟悉,这里是处理多个单位和其属性的(相关性)信息和其编码(用在了observation 的encoding 和 action 的decoding上),这个也是在NLP上经过实践检验的一个结构了,其潜在应用还是很广泛的。 -
scatter connections: 这部分用于combine不同类型的特征 e.g., images, lists, and sets. 但是该部分的结构细节在论文中似乎没有被提及 -
LSTM: 处理部分可观测问题,这个在介绍过的OpenAI处理魔方问题 上也做了同样的使用 -
auto-regressive policy: 处理结构化动作采样的问题,将一个state要做的一个N维动作决策,转化为N个1维的动作序列进行处理(e.g., 先选择单位,再选择该单位的目标位置)
-
point network: PointNet原本是处理点云(Point Cloud)的一个网络结构,点云的结构一般来说是扫描物体的XYZ坐标 + 点内的特征信息(比如RGB信息等),这里应该是将星际中每一个单位(unit)特征信息和其所在的地图位置(XYZ),构造成一个”点云“,带入PointNet进行编码处理。 -
ResNet/Decconv ResNet处理像素信息,用在了小地图的编码以及target point action的选择上。
消融实验可以看出这几个结构对算法性能都起到了比较关键性的影响(尤其是Pointer network和Transformer)
3.2 决策层设计
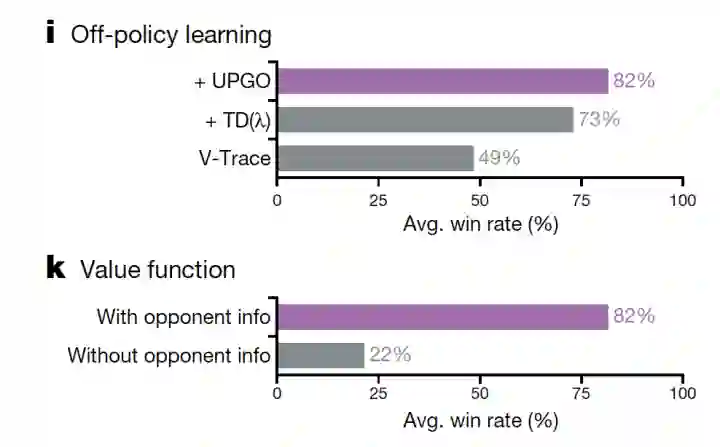
主要用了以下4个技术:
-
V-trace Off policy的训练算法选用的是ACER ,做的一个改进是:在各个维度的动作时相互独立的假设下来计算importance sampling ratio,避免corrections truncate the trace early的问题 -
TD(lambda) value func的计算和更新使用了TD(lambda)技术 -
With Opponent info value func在训练的时候,使用了对手信息来进行辅助训练(这么做是因为value function 对于最后部署是不必要的,使用对手信息可以更好的学出value值,这个在之前讲过的OpenAI处理机械手臂的文章也使用到了 ) -
upgoing policy update (UPGO) 处理稀疏奖赏的问题, 这是一个类似Self-imitation Learning思想 技术 : 首先 self-imitation learning (SIL)的思路,是为了更充分利用采集到的具有高奖赏的轨迹,以达到稀疏奖赏下提高学习效率的效果。具体而言,SIL会把单条轨迹的MC 采样的return值和 estimated value 进行比较,若该Return 是大于estimated value 的return, 则直接用该MC return进行 value function和策略的更新,而不是经过TD的方法进行逐步的更新value,再用更新的Value去调整策略,以达到更强的信号去模仿该轨迹的效果,具体而言, SIL的目标如下:

UPGO做的是基本一样的,只是操作粒度从整个trajectory的维度,变成了在每一个timestep的维度。具体而言,他在回溯计算timestep的reward的时候,如果 ,即reward起到了相对于当前策略更优性能,则 , 否则 。 取决于 时间步的性能,可能是MC-return,也可能是estimated value 。

对应消融实验结果如下图:
总结
-
总的来说,AlphaStar虽然取得了很好的效果,但是这个一定程度上是因为 充分的利用了专家知识的缘故。一方面告诉我们:你在做的项目的模型效果不好?有时候可能只是我们还没挖掘出专家数据的全部潜力;一方面也说明:RL目前的学习手段依然要直接学习到复杂策略,还有一定难度; -
对于训练一个鲁棒的策略,使用种群式的训练和对抗训练,都是值得采用的思路。其实这两种方法在其他方向都有很多的工作。我们经常对模型进行对抗攻击,来找到模型的漏洞;也会利用对抗的方式构造新的样本,利用对抗样本进行模型微调,产生更鲁棒的模型。我们也经常利用多样化的环境训练模型(比如Multi-task learning,Domain Randomization等),避免我们的模型过拟合于当前的环境或当前的数据集而缺乏泛化能力。 -
一些关键性的算法trick的采用,有效提升了整体性能,有些时候,我们距离那个看似难以达成的目标,只差一个“combination”
作者:陈雄辉,南京大学博士
文章来源:https://zhuanlan.zhihu.com/p/97720096?utm_source=wechat_timeline&utm_medium=social&s_s_i=T71GXrq%2BETO54%2BHA8volBgvzg0FuLF9hn6rJ%2BgMcyEw%3D&s_r=1&from=timeline
完
第51篇:全网首发最全深度强化学习资料(永更)
第50篇:30+个必知的《人工智能》会议清单
第49篇:《强化学习导论》代码/习题答案大全
第48篇:Exploration-Exploitation难题解决方法
第47篇:2019年-57篇深度强化学习文章汇总
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第14期论文: 2020-02-10(8篇)
第13期论文:2020-1-21(共7篇)
第12期论文:2020-1-10(Pieter Abbeel一篇,共6篇)
第11期论文:2019-12-19(3篇,一篇OpennAI)
第10期论文:2019-12-13(8篇)
第9期论文:2019-12-3(3篇)
第8期论文:2019-11-18(5篇)
第7期论文:2019-11-15(6篇)
第6期论文:2019-11-08(2篇)
第5期论文:2019-11-07(5篇,一篇DeepMind发表)
第4期论文:2019-11-05(4篇)
第3期论文:2019-11-04(6篇)
第2期论文:2019-11-03(3篇)
第1期论文:2019-11-02(5篇)


