谷歌Jeff Dean团队发文,探讨「学习模型」如何替代传统索引结构
原文来源:arxiv-vanity
作者:Tim Kraska、Alex Beutel、Ed H. Chi、Jeffrey Dean、Neoklis Polyzotis
「雷克世界」编译:嗯~阿童木呀、多啦A亮、我是卡布达
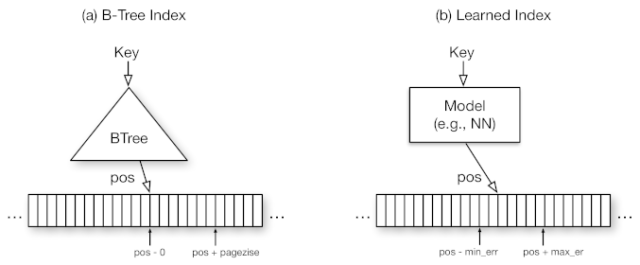
索引就是模型:B-Tree-Index可以看作是一个能够将一个键映射到排序数组中记录所在位置的模型;哈希索引(Hash-Index)是一个能够将键映射到未排序数组中记录所在位置的模型;BitMap-Index则是一个用以指示数据记录是否存在的模型。在这篇探索性的研究论文中,我们从这个前提出发,假设所有现有索引结构都可以被其他类型的模型所代替,其中也包括我们称之为学习索引的深度学习模型。其中的关键思想是,一个模型可以学习查找键的排序顺序或结构,然后使用这个信号对记录的所在位置或存在进行有效地预测。我们从理论上分析了在哪些条件下,学习索引架构的表现要优于传统索引结构,并描述了在学习索引结构设计方面所存在的主要挑战。最初的研究结果表明,通过使用神经网络,我们能够在速度上超越缓存优化B-Trees达到70%,同时还在真实数据集中节省了数量级内存。更重要的是,我们相信,通过用学习模型取代数据管理系统的核心组件这一想法对于未来的系统设计有着深远的影响,而我们这项研究只是提供了一些可能的表现。
无论何时需要高效的数据访问,索引结构都能给予满足,并且存在多种选择以满足各种访问模式的不同需求。例如,B-Trees是区间请求(range requests)的最佳选择(例如,在一定的时间范围内检索所有记录);在基于键的查找中,哈希映射(Hash-Maps)在性能上难以找到对手;而布隆过滤器(Bloom-filters)通常用于检查是否存在记录。由于索引对于数据库系统和许多其他应用程序的不言而喻的重要性,过去几十年来,它们已经被广泛地进行调优以提高内存、高速缓存和/或CPU效率。
然而,所有这些索引都是通用数据结构,假设数据分布最差,而且没有利用真实数据中普遍存在的模式。例如,如果目标是建立高度调谐的系统,用以存储和查询具有连续整数键(例如,键1到100M)的固定长度记录,那么将不使用传统的B-Trees索引来覆盖键,因为键本身可以用作抵消,使其成为一个O(1)而不是O(logn) 操作来查找任意键或一系列键的开始。同样的,索引内存的大小也会从O(n)减少到O(1)。也许令人惊讶的是,对于其他数据模式,相同的优化仍然是可能的。换句话说,了解精确的数据分布可以高度优化数据库系统所使用的几乎任何索引。
当然,在大多数真实用例中,数据并不完全遵循已知的模式,而为每个用例构建专门解决方案的工程工作量通常都是极其高的。然而,我们认为,机器学习打开了一个学习模型的机会,它可以反映数据模式和相关性,从而能够以较低的工程成本自动合成我们称之为学习索引的专业索引结构。
在本文中,我们探讨了包括神经网络在内的学习模型在多大程度上可以用来代替传统的索引结构,从B-Trees到Bloom-filters。这似乎与直觉相反,这主要是因为机器学习不能提供我们传统上与这些索引相关联的语义保证,并且因为最强大的机器学习模型——神经网络,传统上被认为是非常昂贵从而难以进行评估的。然而,我们认为,这些明显的障碍并没有像它们表面上那么具有问题性。相反,我们使用学习模型的建议可能会带来巨大的好处,特别是在下一代硬件上,所带来的益处不可小觑。
在语义保证方面,索引已经在很大程度上被学习模型所取代,这使得用其他类型的模型来代替它们也变得非常简单,如神经网络。例如,可以将B-Trees视为一个模型,它将一个键作为输入,并预测数据记录所在位置。一个Bloom-filter是一个二进制分类器,它基于一个键来预测一个键是否存在于某个集中。很明显,存在细微但重要的区别。例如,一个Bloom-filter可能有假阳性,而不是假阴性。然而,正如我们将在本文中展示的那样,通过全新的学习技术和/或简单的辅助数据结构,解决好这些差异性事非常有可能的。
在性能方面,我们观察到每个CPU都拥有强大的SIMD功能,并且我们推测许多笔记本电脑和手机也将很快拥有图形处理单元(GPU)或张量处理单元(Tensor Processing Unit,TPU)。此外,相较于通用指令集而言,它更容易对神经网络所使用的受限(并行)数学运算集进行扩展,因此我们可以合理地推测,CPU-SIMD/GPU/TPU的功能将越来越强大。因此,执行神经网络的高昂成本在未来可以忽略不计。例如,英伟达和谷歌的TPU已经能够在一个周期内完成即使不是上万次也要有数千次的神经网络操作。此外,有人声称,到2025年CPU的性能将提高1000倍,而基于摩尔定律(Moore’s law)的CPU在本质上将不复存在。通过利用神经网络取代分支重索引结构,数据库可以从这些硬件的发展趋势中受益。
值得注意的是,我们并不认为学习索引结构可以完全替代传统索引结构。相反,我们论述了一种建立索引的新方法,它完善了现有的研究,并且可以说,它为该领域数十年的研究开辟了一个新方向。虽然,我们的关注点在于只读分析工作负载,但我们也概述了如何将这一想法拓展至写入繁重工作负载(write-heavy workloads)的加速索引。此外,我们简要地概述了如何使用相同的原则来取代数据库系统的其他组件和操作,其中包括排序和连接。如果成功的话,这可能导致与当前数据系统的开发方式完全不同。
结论与未来研究
研究结果表明,学习索引可以通过利用被索引数据的分布提供显著效益。这为许多有趣问题的研究打开了一扇大门。
多维索引
坦白讲,对学习索引而言,最激动人心的研究方向是将其扩展到多维索引结构。尤其是神经网络模型,非常擅长捕捉复杂的高维度关系。在理想状态下,这个模型能够预估由任意属性组合过滤后的记录所有位置。
超越索引:
学习算法
或许令人惊讶的是,CDF模型不仅具有索引能力,在加速排序(speed-up sorting)和连接方面同样拥有潜力。例如,加速排序(speed-upsorting)的基本思路是使用一个现有的CDF模型F,将粗略的排序按顺序排列,将几近完美的排列数据进一步修正,比如,插入排序(insertion sort)。
GPU/TPU
最后,正如本文中多次提及的那样,GPU/TPU将使得学习索引的思想更加可行。但与此同时,GPU/TPU也面临其自身的挑战,其中最重要的是高调用延迟(high invocation latency)。虽然我们可以合理地认为,根据前面所展示的异常压缩比率,所有的学习索引都适用于GPU/TPU,但这中间任需要2-3微秒的时间来调用他们的所有操作。同时,机器学习加速器与CPU的集成越来越好,通过使用诸如批量请求(batching requests)这样的技术,调用的成本可以被分摊,所以我们不认为调用延迟是一个真正的障碍。
总而言之,我们已经证明,相较于最先进的数据库索引而言,机器学习模型有潜力展现出更大优势。我们坚信这将对未来的研究提供卓有成效的指导。
原文链接:https://www.arxiv-vanity.com/papers/1712.01208v1/
未来智能实验室致力于研究互联网与人工智能未来发展趋势,观察评估人工智能发展水平,由互联网进化论作者,计算机博士刘锋与中国科学院虚拟经济与数据科学研究中心石勇、刘颖教授创建。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎支持和加入我们。扫描以下二维码或点击本文左下角“阅读原文”




