内存用量1/20,速度加快80倍,腾讯QQ提出全新BERT蒸馏框架,未来将开源
机器之心发布
机器之心编辑部
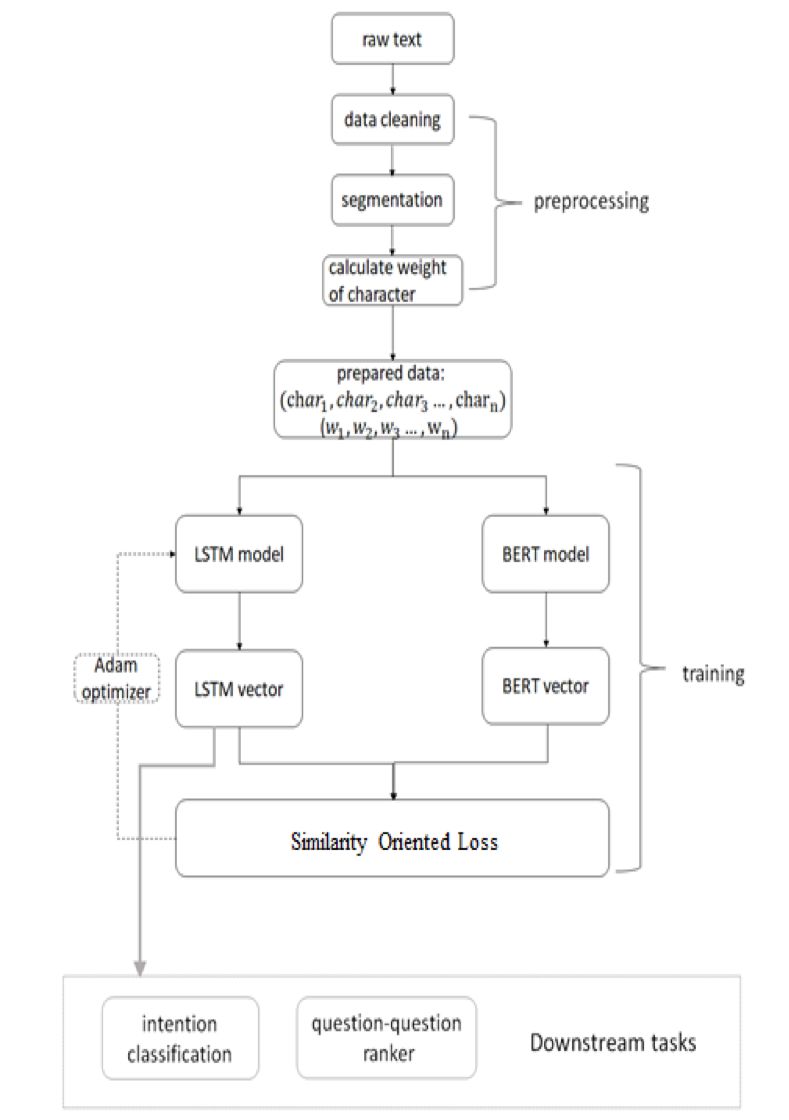
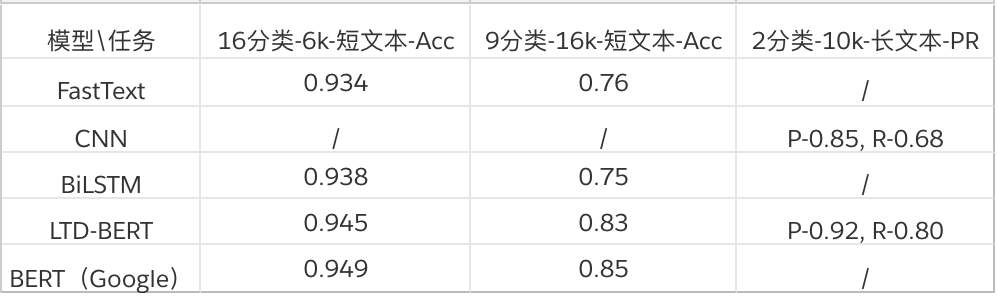
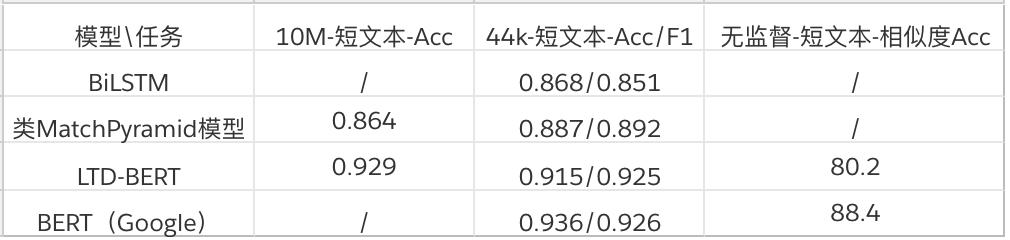
腾讯 QQ 团队研究员对 BERT 进行了模型压缩,在效果损失很小的基础上,LTD-BERT 模型大小 22M,相比于 BERT 模型内存、存储开销可降低近 20 倍,运算速度方面 4 核 CPU 单机可以预测速度加速 80 余倍。相关代码和更多结果将在近期开源。
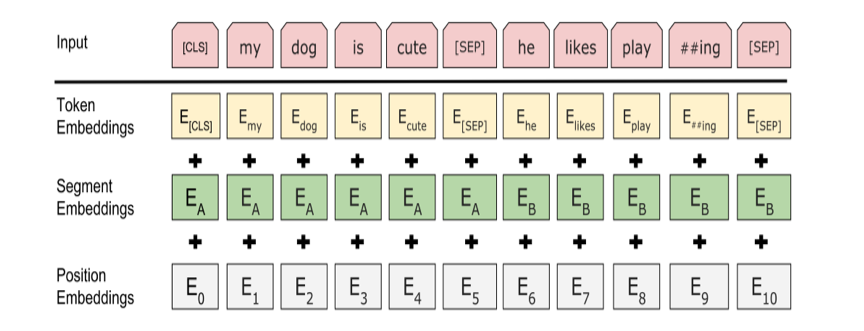
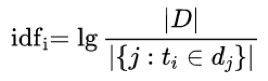
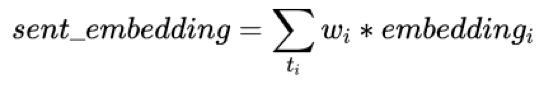
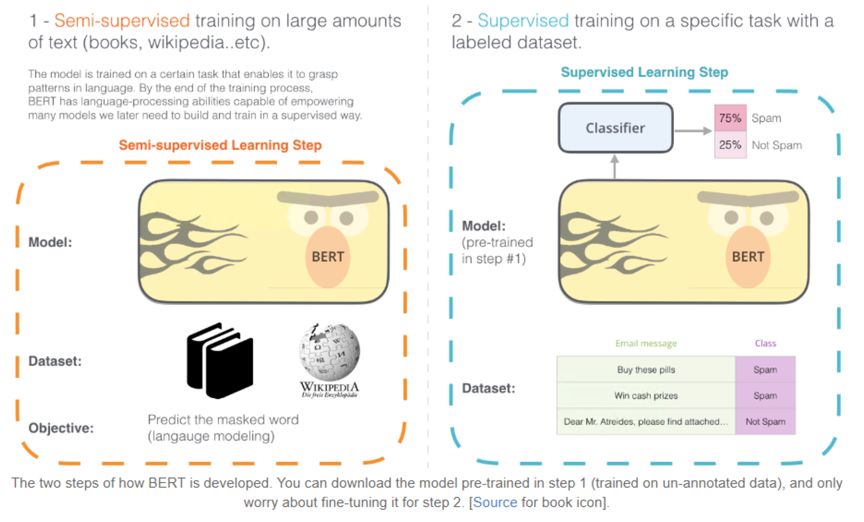
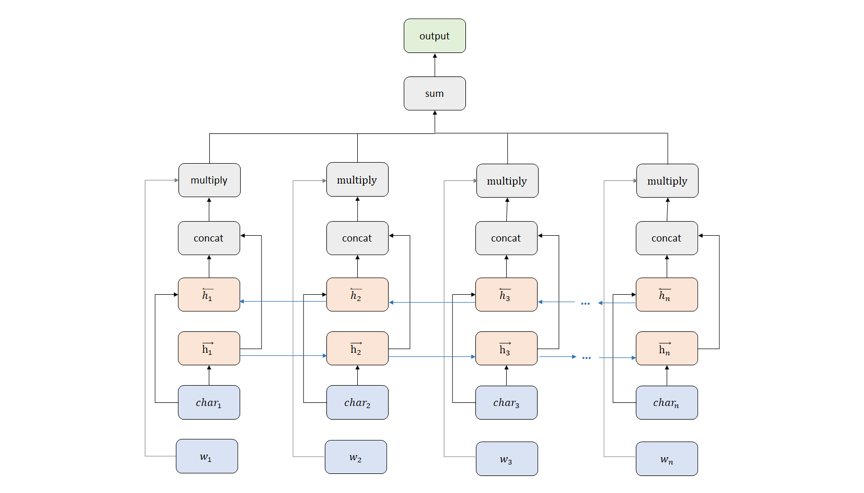
如下图 2 中所示的 BERT 训练流程,这部分工作更关注在右侧 Supervised 部分。而 BERT 的突破很大程度上依赖与图中左边弱监督过程中从大量文本数据学习到的语义建模能力,因此这里 LTD-BERT 的初衷是希望 Student 模型能够将这部分能力蒸馏过来,所以不对 Student 网络建立目标任务,Student 的目标仅为拟合 Teacher 网络的 sentence vector,不再去关注 Teacher 网络的预训练任务。通过合适的 loss function 设计,实验验证简单的 Student 网络可以较好的拟合 BERT 产生的句向量,并运用于各类 Task。
登录查看更多
相关内容

Arxiv
5+阅读 · 2019年9月26日
Arxiv
8+阅读 · 2019年3月22日
Arxiv
4+阅读 · 2018年4月23日
Arxiv
4+阅读 · 2018年3月30日





相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2019年9月26日
Arxiv
8+阅读 · 2019年3月22日
Arxiv
4+阅读 · 2018年4月23日
Arxiv
4+阅读 · 2018年3月30日