学界 | 英特尔提出新型压缩技术DeepThin,适合移动端设备深度神经网络
选自arXiv
作者:Matthew Sotoudeh等
机器之心编译
参与:路雪
近日,英特尔的研究者提出新型深度神经网络压缩技术 DeepThin,适合移动端设备,性能优于其他压缩技术。
论文:DeepThin: A Self-Compressing Library for Deep Neural Networks

论文链接:https://arxiv.org/abs/1802.06944
摘要:随着业界在移动设备上部署越来越大、越来越复杂的神经网络,这些设备的内存和计算资源所面临的压力也越来越大。深度压缩(或深度神经网络权重矩阵压缩)技术为此类场景扩展了应用资源。现有的压缩方法无法高效压缩模型,压缩 1-2% 都比较困难。我们开发了一种新的压缩技术 DeepThin,该技术基于低秩分解领域的现有研究。我们将秩分解和向近似函数添加非线性的重塑过程结合起来,从而识别和打破由低秩近似造成的人工约束。我们将 DeepThin 部署为一个与 TensorFlow 相整合的 plug-gable 库,使用户无缝压缩不同粒度的模型。我们在两个顶尖的声学模型 TFKaldi 和 ZXC DeepSpeech 上评估 DeepThin,将其与之前的压缩方法(剪枝、HashNet 和秩分解)、实证有限研究方法和手动调整模型进行了对比。在 TFKaldi 上,DeepThin 网络的词错率(WER)在几乎所有测试压缩率情况下优于其他方法,平均优于秩分解 60%,优于剪枝 57%,优于等大小的手动调整网络 23%,优于计算成本高昂的 HashNet 6%。在 DeepSpeech 上,DeepThin 压缩网络比所有其他压缩方法的测试损失都低,优于秩分解 28%,优于剪枝 27%,优于手动调整同样大小网络 20%,优于 HashNet 12%。DeepThin 还使推断速度提升了 2 倍到 14 倍,提升幅度取决于压缩率和平台缓存大小。
1 引言和动机
近年来,机器学习算法越来越广泛地应用于消费者产品中,如个人助手中的语音识别。这些算法依赖于大型权重矩阵将网络中的不同节点之间的关系进行编码。完美情况下,这些算法将直接在客户端设备上运行,如 Amazon Echo [20] 和 Google Home [14]。不过,此类设备通常是移动、低功耗设备,因此运行此类对内存、性能和能耗有很高要求的算法并不可行。
为了解决该问题,很多开发者致力于在高性能云服务器上执行推断模型,和在客户端和服务器之间传输模型输入和输出。但是,该解决方案带来了很多问题,如高昂的运算成本、移动网络上的大量数据迁移、用户隐私担忧,以及延迟增加。
近期研究调查了可将模型压缩至能够在客户端设备上直接高效执行的方法。此类压缩方法必须在基本不影响预测准确率、运行时性能或工程时间量的前提下降低模型空间需求。我们的研究基于低秩分解领域的现有研究,我们开发了一种新型压缩方法和 DeepThin 库,该方法:
使用辅助中间矩阵和高效的重新布局操作,解决了机器学习模型参数极低秩矩阵分解的基础对称性问题。
整合了流行和常用的 TensorFlow 框架,使用户无缝压缩不同粒度的模型。我们在该库中实现了之前的压缩技术,以对比不同压缩方法的准确率损失。
在同样大小的网络上,比其他压缩方法的准确率更高。
在我们基于 MKL [11] 的自定义 C++ TensorFlow 操作帮助下,实验证明其推断性能加速比未压缩的模型提高 2 倍到 14 倍。
3. DeepThin 压缩模型
标准的深度神经网络包含一系列有序连接的层级(layer),输入数据依次通过各层直到获得想要的输出。每个层计算先前层输出与当前层权重矩阵之间的矩阵乘积。在计算完矩阵乘积之后,将结果加上偏置项并馈送到非线性激活函数而得到输出。
对有时间依赖性的数据,可使用循环神经网络。尽管有很多不同类型的 RNN,但它们都涉及一种包含若干(通常 3 或 4)类似于上述计算步骤的模型。这样的模型要比寻常的 DNN 更具参数效率,但仍旧需要特别大的权重矩阵来获得优秀的准确率,因此它们可以从压缩方法中得到巨大收益。
对视觉数据而言,卷积神经网络从输入数据中学习到滤波器组(权重),来提取常见特征。每层的正向传播步骤都类似于上面描述的层运算。在此论文中,我们重点放在了 RNN 和前馈 DNN。然而,把 DeepThin 压缩方法应用到 CNN 也没有任何基础限制。
在该研究中,我们将该压缩方法单独应用到每层的权重矩阵。具备非线性激活函数 a、权重 W、偏置项 B 的单个层可定义为:Y = a(X.W + B) (1),其中 W 和 B 是必须存储在该网络内的可学习参数。B 的大小与 W 相比可以忽略不计,因此这里我们只考虑 W 参数的压缩(不过我们在评估中也压缩偏置项)。
DeepThin 架构可压缩任意存储大型权重矩阵(如公式 1 中的 W)的模型,不过准确率会有些微损失。
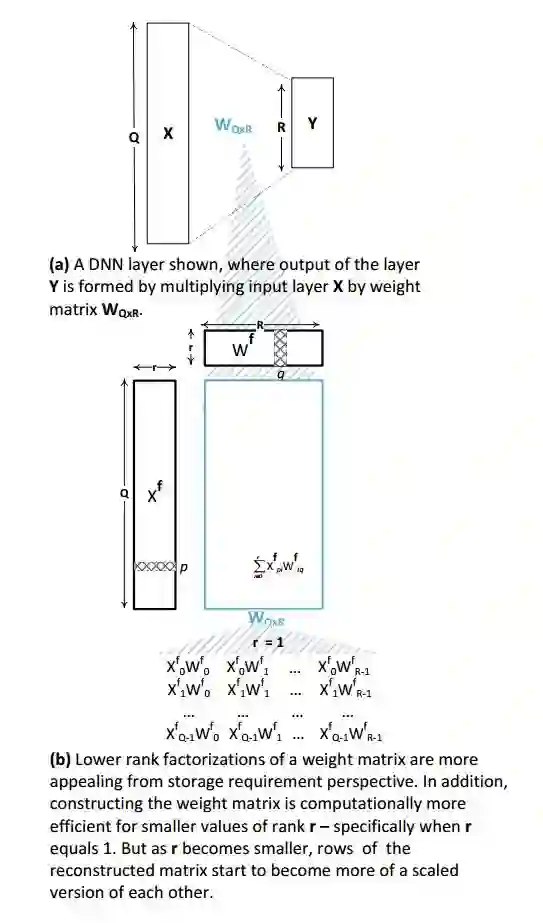
图 1. 权重矩阵的低秩分解:随着 r 变小,重构矩阵的行和列对应地实现缩放。
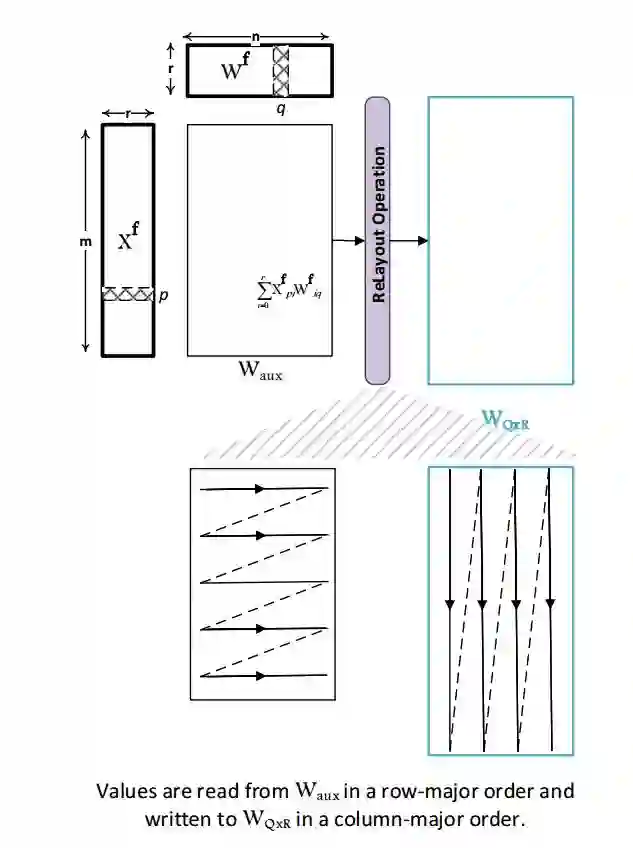
图 2. 打破分解创建的人工结构约束。该变换具备两个可学习参数:低秩因子 X^f 和 W^f。
6 准确率结果

表 1. 与其他四种压缩方法相比,DeepThin 的平均提升。TFKaldi 数值是关于词错率下降,DeepSpeech 数值是关于测试误差减少。这里,我们看到不同的压缩方法在不同的数据集上各有偏重,而 DeepThin 在几乎所有测试情况中打败了其他压缩方法。
7 性能结果
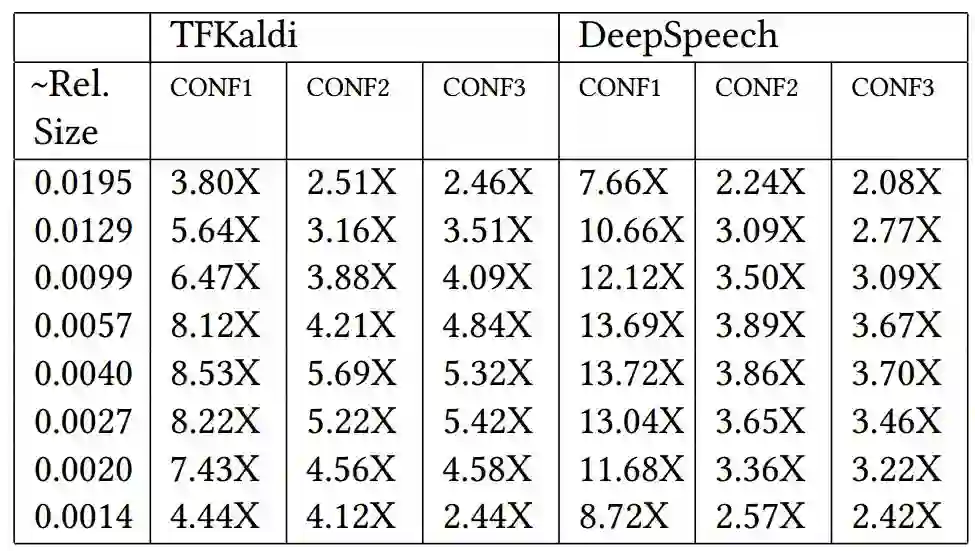
表 2. TFKaldi 和 DeepSpeech 上,DeepThin 模型在不同压缩大小和机器情况中的执行速度对比。不同机器之间的压缩大小略有不同,但是准确程度在 0.0001 以内。所有结果都以比未压缩的基线模型速度「X faster」的形式呈现。我们发现最大的提升来自缓存较小的平台,使用 DeepThin 可持续降低所有测试配置中的执行时间,使之更适合延迟和电量使用比较重要的环境。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com