腾讯AI开源框架Angel 3.0重磅发布:超50万行代码,支持3种算法,打造全栈机器学习平台

概述
-
Angel是一个基于Parameter Server(PS)理念开发的高性能分布式机器学习平台,它具有灵活的可定制函数PS Function(PSF),可以将部分计算下推至PS端。PS架构良好的横向扩展能力让Angel能高效处理千亿级别的模型。 -
Angel具有专门为处理高维稀疏特征特别优化的数学库,性能可达breeze数学库的10倍以上。Angel的PS和内置的算法内核均构建在该数学库之上。 -
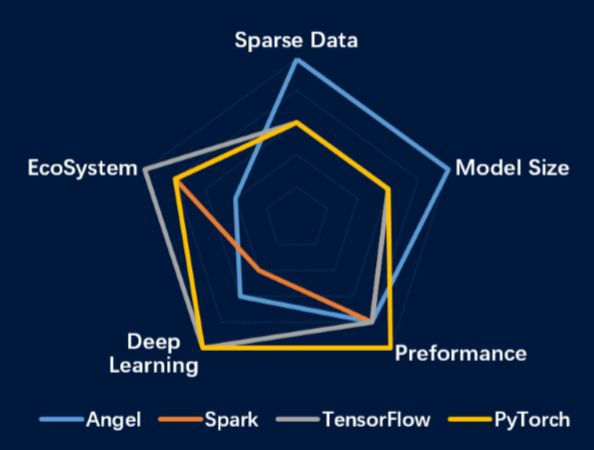
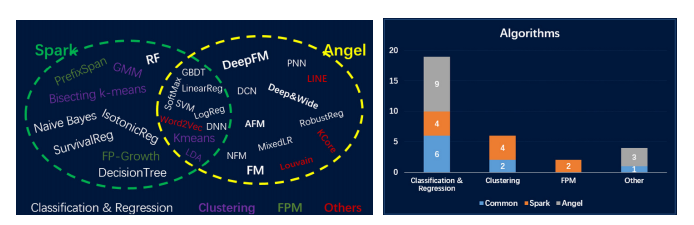
Angel擅长推荐模型和图网络模型相关领域(如社交网络分析)。图1是Angel和几个业界主流平台在稀疏数据,模型维度,性能表现,深度模型和生态建设几个维度的对比。Tensorflow和PyTouch在深度学习领域和生态建设方面优势明显,但在稀疏数据和高维模型方面的处理能力相对不足,而Angel正好与它们形成互补,3.0版本推出的PyTorch On Angel尝试将PyTorch和Angel的优势结合在一起。
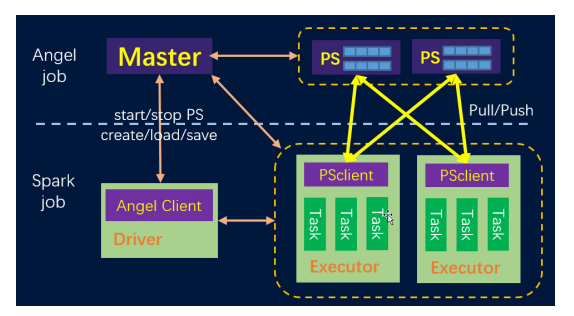
Angel系统架构
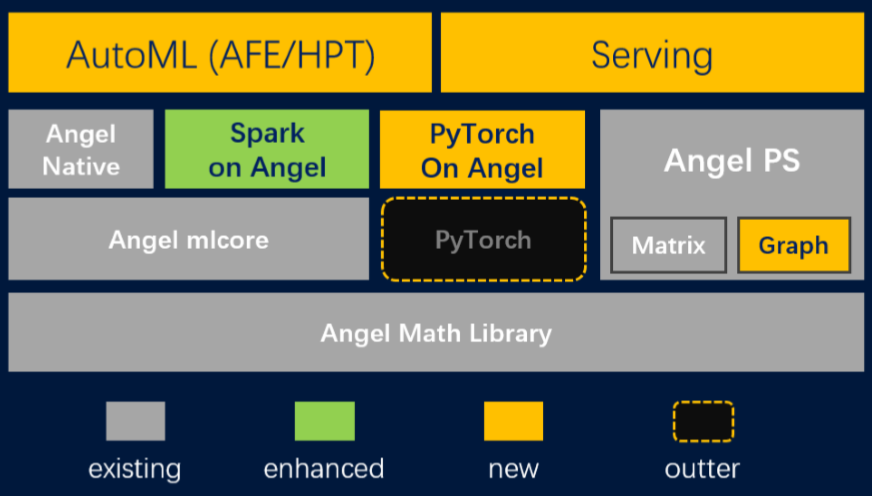
Angel 3.0新特性
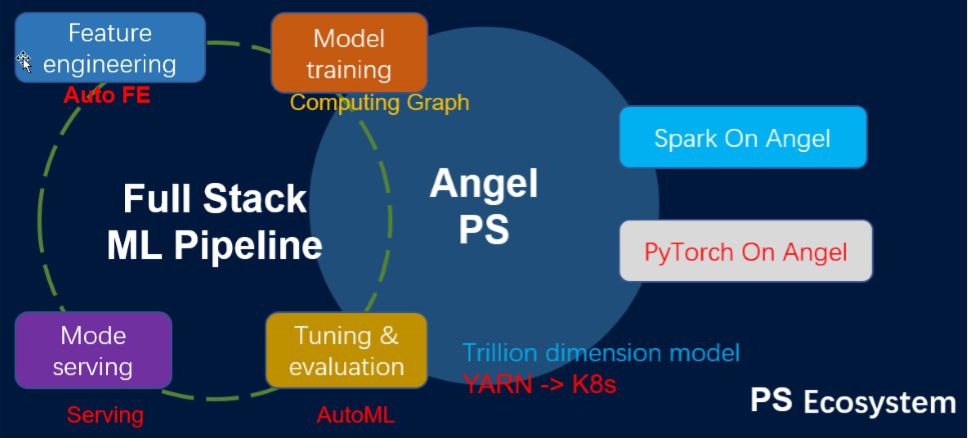
图3 Angel 3.0概览(红色的表示新增特性,白色的表示已有的但在持续改进的特性)
(一)自动特征工程
-
基于统计的运算符,包括VarianceSelector和FtestSelector -
基于模型的运算符,包括LassoSelector和RandomForestSelector
-
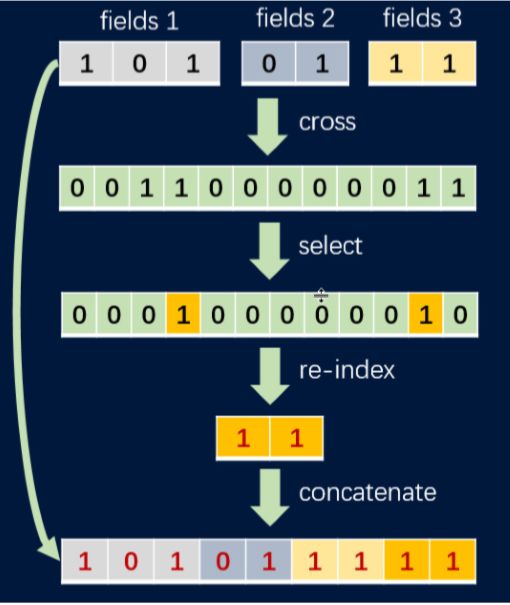
扩增阶段:任意特征的笛卡尔积 -
缩约阶段:特征选择和特征重索引
-
首先任意的输入特征之间通过笛卡尔积生成合成特征。该步骤后,特征数量将以二次方式增加 -
接下来,从合成特征中选择最重要的特征子集(使用例如VarianceSelector和RandomForestSelector) -
然后,重新索引所选择的特征以减少特征空间 -
最后,合成特征与原始特征拼接在一起
|
|
|
|
||
|
|
|
|
|
(二)Spark On Angel (SONA)
-
Spark On Angel中集成了特征工程。在集成的过程中并不是简单地借用Spark的特征工程,为所有的运算支持了长整型索引的向量使其能够训练高维稀疏模型 -
与自动调参无缝连接 -
Spark用户能够通过Spark-fashion API毫不费力的将Spark转换成Angel -
支持两种新的数据格式:LibFFM 和Dummy
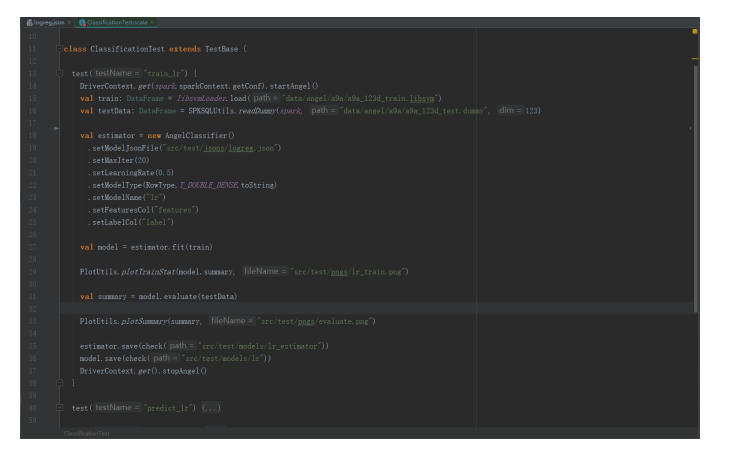
-
在程序开始时启动参数服务器,程序结束时关闭参数服务器 -
将训练集和测试集以Spark DataFrame形式加载 -
定义一个Angel模型并以Spark的参数设置方式为其设置参数。在这个示例中,算法是一个通过JSON定义的计算图 -
使用“fit”方法来训练模型 -
使用“evaluate”方法来评估已训练的模型
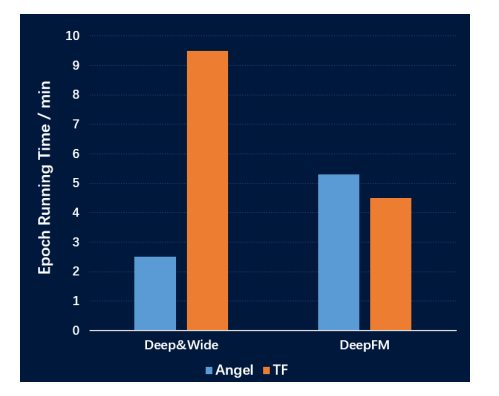
(三)PyTorch On Angel(PyTONA)
-
TensorFlow和PyTorch拥有高效的自动求导模块,但是它们不擅长处理高维度模型和稀疏数据 -
Angel擅长处理高维度模型和稀疏数据,虽然Angel自研的计算图框架(MLcore)也可以自动求导,但是在效率和功能完整性上却不及TensorFlow和PyTorch,无法满足GNN的要求
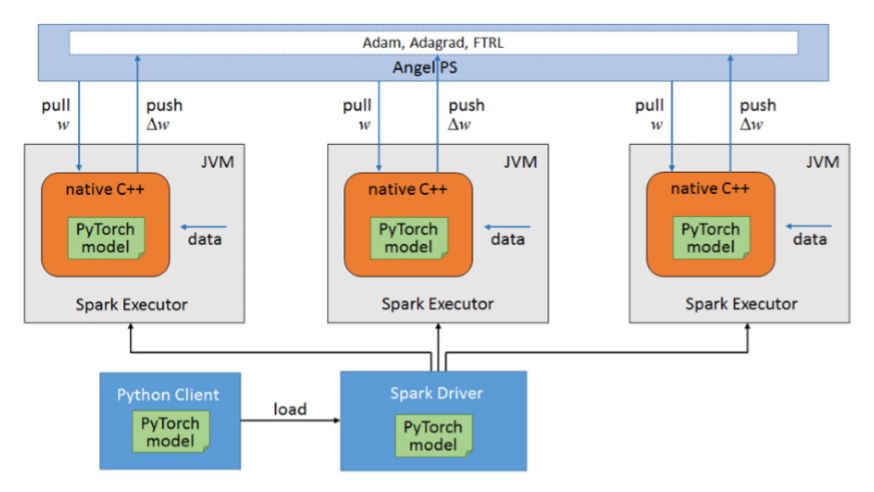
-
Angel PS:存储模型参数,图结构信息和节点特征等,并且提供模型参数和图相关数据结构的访问接口,例如需要提供两跳邻接访问接口 -
Spark Driver:中央控制节点,负责计算任务的调度和一些全局的控制功能,例如发起创建矩阵,初始化模型,保存模型,写checkpoint以及恢复模型命令 -
Spark Worker:读取计算数据,同时从PS上拉取模型参数和网络结构等信息,然后将这些训练数据参数和网络结构传给PyTorch,PyTorch负责具体的计算并且返回梯度,最后Spark Worker将梯度推送到PS更新模型
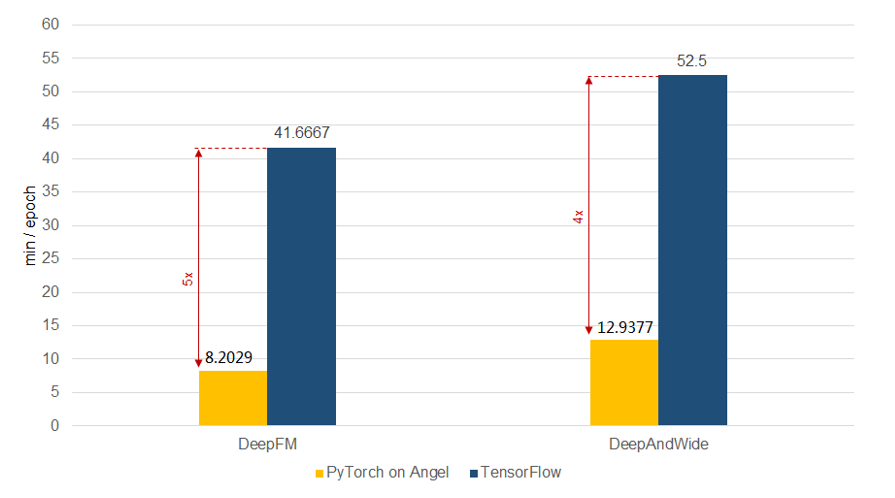
(四)自动超参数调节
-
网格搜索:网格搜索将整个搜索空间切分为网格,假设超参数是同等重要的。这种方式虽然直观,但有两个明显的缺点:1)计算代价随参数数量的增长而呈指数增长;2)超参数的重要程度常常是不同的,网格搜索可能会花费太多精力来优化不太重要的超参数 -
随机搜索:随机采样超参数组合,并评估抽样组合。虽然这种方法有可能关注更重要的超参数,但是仍无法保证找到最佳组合
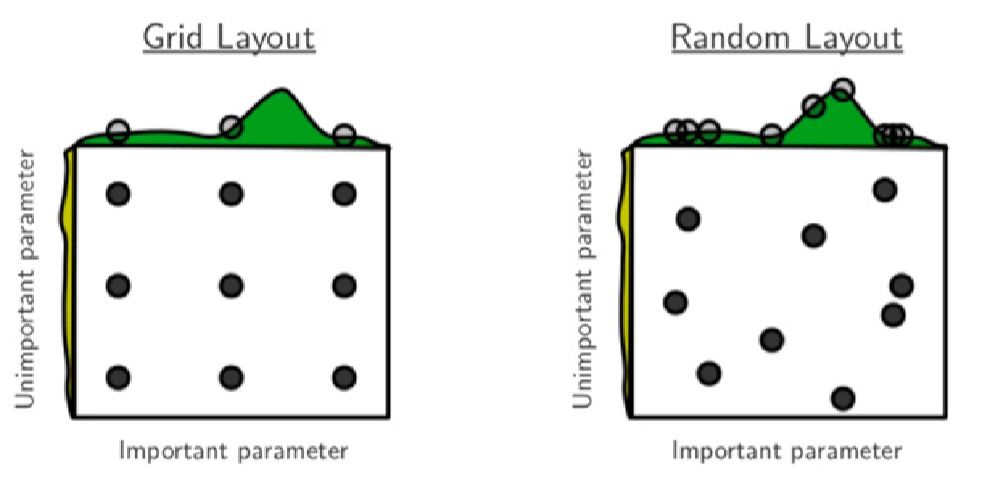
-
代理函数。除了常用的两种模型(高斯过程和随机森林),也实现了EM + LBFGS优化高斯过程内核函数中的超参数 -
效用函数:实现了PI(Probability of improvement),EI(Expected Improvement)和UCB(Upper Confidence Bound)

(五)Angel Serving
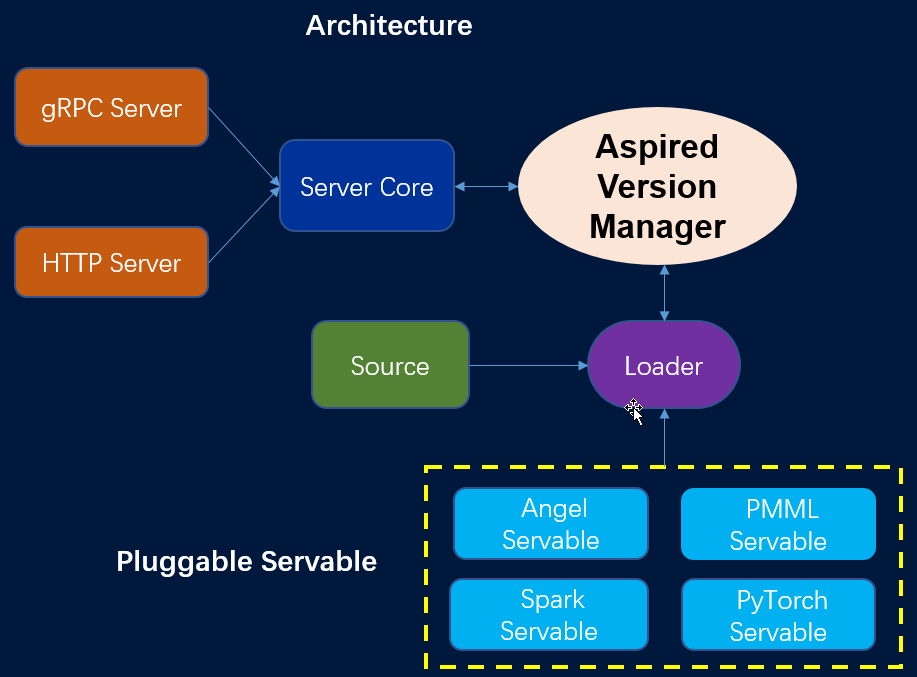
QPS: 每秒请求数
总的请求数以及成功请求总数
请求的响应时间分布
平均响应时间
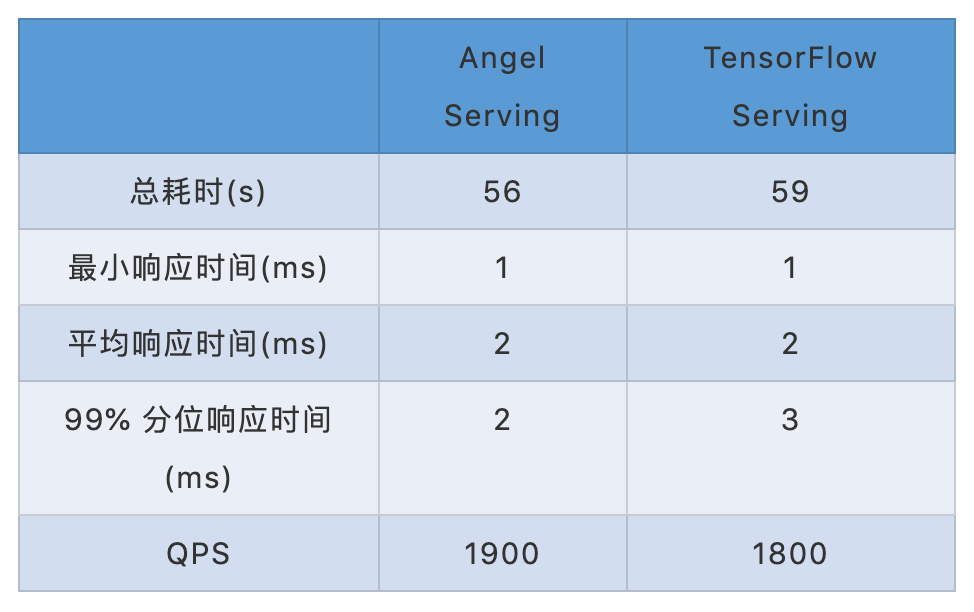 表3 Angel Serving和Tensorflow Serving性能对比
表3 Angel Serving和Tensorflow Serving性能对比
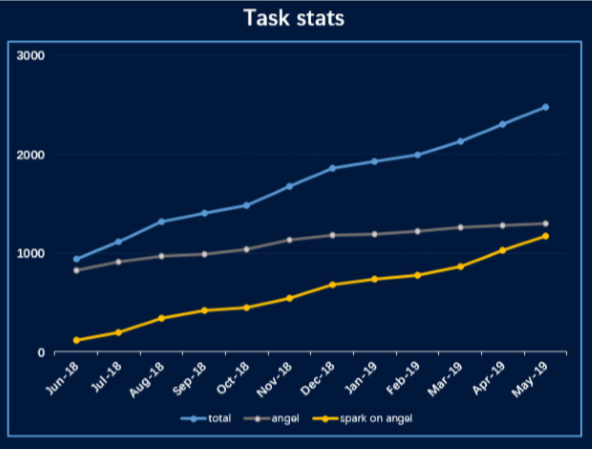
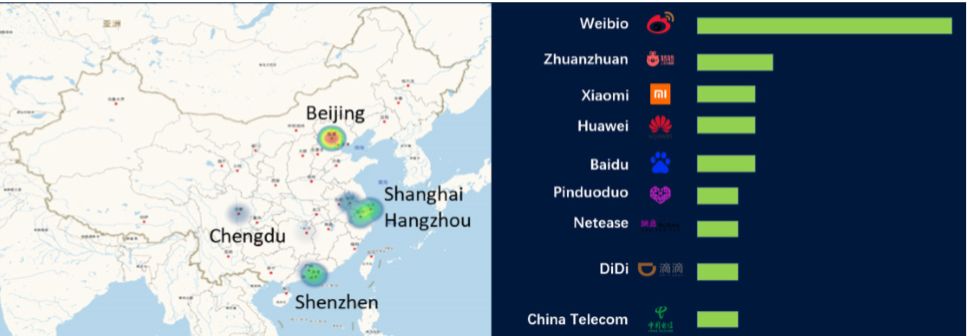
Angel使用情况
-
Angel的绝大部分用户来自中国,主要分布在北京,上海,杭州,成都和深圳等互联网行业比较发达的城市。 -
有超过100家的公司和科研机构在使用或测试Angel,其中包括了中国最顶级的IT公司:微博,华为和百度等。
Angel开源

案例
一:腾讯短视频推荐
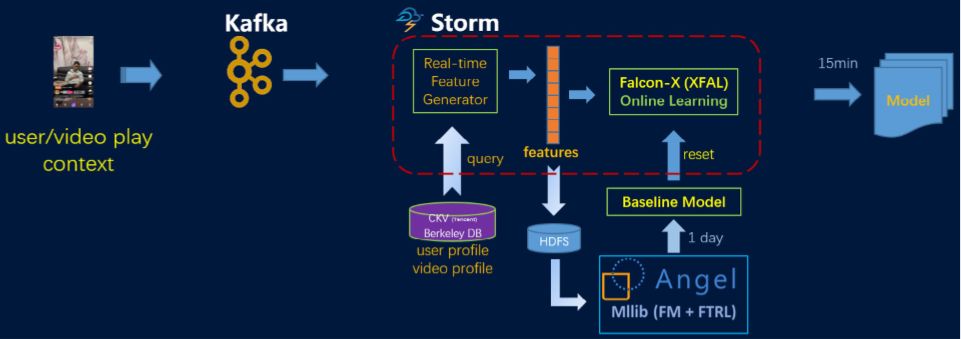
二:金融反欺诈
![]()
图 18 金融反欺诈数据处理流程
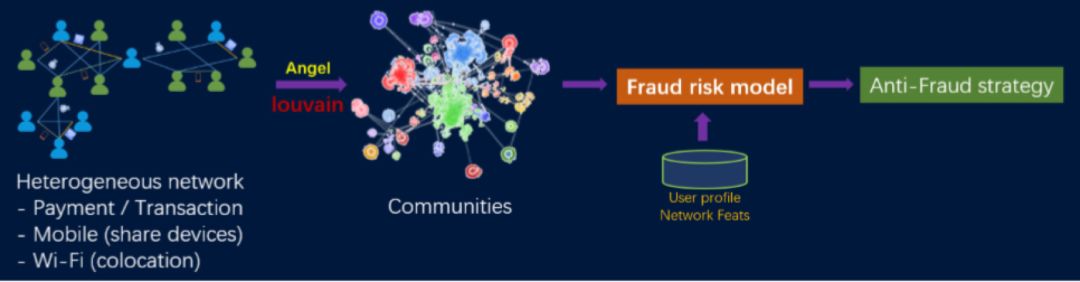
-
交易关系: 用户A和用户B之间如存在交易关系表明他们之间曾出现过交易行为 -
设备关系:用户A和用户B之间如存在设备关系表明他们曾共享过同一个设备 -
Wi-Fi关系:用户A和用户B之间如存在Wi-Fi关系表明他们曾通过一个Wi-Fi连接到互联网
小结
-
自动特征工程:新增特征选择和组合方法,将特征合成、选择和重新索引以pipeline的形式呈现,用来迭代生成高阶合成特征 -
新的计算引擎: -
SONA(加强):特征工程支持索引为Long类型的向量;所有的算法被封装成Spark风格的APIs;SONA上的算法可以作为Spark的补充 -
PyTONA(新):PyTONA作为图学习算法的引擎被引入,目前支持GCN和GraphSage,同时也支持推荐领域的算法。PyTONA采用Python作为交互,因此是用户友好的 -
自动机器学习:Angel3.0引入了3种超参数调节算法:网格搜索、随机搜索和贝叶斯优化 -
Angel模型服务:Angel提供一个跨平台的模型服务框架,支持Angel、PyTorch和Spark的模型,性能上与TensorFlow Serving相当 -
支持Kubernetes:Angel3.0支持Kubernetes,从而可以在云上运行
-
腾讯内部:用户数和任务数增加1.5倍 -
腾讯外部:超过100多家公司和机构使用Angel -
开源贡献:4200多个star, 8个子项目,1100多个fork,2000多次commits
(*本文为 AI科技大本营原创文章,转载请联系微信 1092722531)
◆
福利时刻
◆
入群参与每周抽奖~
扫码添加小助手,回复:大会,加入福利群,参与抽奖送礼!

大会5折优惠票倒计时 2 天! 团购还享立减优惠,倒计时 2 天!此外,伯克利大学名师精髓课程移师北京。《动手学深度学习》作者、亚马逊首席科学家李沐线下亲授「深度学习实训营」,免费GPU资源,现场还将限量赠送价值85元的配套书籍一本,先到先得。原价1099元,限时专享CSDN 独家福利价199元!识别海报二维码,即刻购票~

推荐阅读
2019 AI ProCon日程出炉:Amazon首席科学家李沐亲授「深度学习」
玩嗨的2亿快手“老铁”和幕后的极致视觉算法
与旷视、商汤等上百家企业同台竞技?AI Top 30+案例评选等你来秀
从不温不火到炙手可热:语音识别技术简史
入门大爆炸式发展的深度学习,你先要了解这6个著名框架
用Python的算法工程师们,编码问题搞透彻了吗?
Python冷知识,不一样的技巧带给你不一样的乐趣
我是如何通过开源项目月入 10 万的?
撬动百亿台设备,让物联网“造”起来!
程序员离无人值班有多远?

登录查看更多
相关内容

Arxiv
9+阅读 · 2019年10月12日
Arxiv
8+阅读 · 2018年8月22日


相关VIP内容
相关资讯
相关论文
Arxiv
9+阅读 · 2019年10月12日
Arxiv
8+阅读 · 2018年8月22日