批归一化和Dropout不能共存?这篇研究说可以
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
自批归一化提出以来,Dropout 似乎就失去了用武用地,流行的深度架构也心照不宣地在批归一化上不采用 Dropout。今天介绍的这篇论文另辟蹊径,提出新型 IndependentComponent(IC)层,将批归一化和 Dropout 结合起来,加快模型收敛速度。此外,在 Keras 中只需几行 Python 代码即可轻松实现 IC 层。
作者 | Guangyong Chen等
转自公众号机器之心
现代深度神经网络的高效训练很难实现,因为你往往要输入数百万条数据。因此,开发新的技术来提高 DNN 的训练效率一直是该领域比较活跃的研究主题。
近期,来自腾讯、港中文和南开大学的研究者提出了一种新的训练技术,将两种常用的技术——批归一化(BatchNorm)和 Dropout 结合在一起。新技术可以使神经网络的输入相互独立,而这两种技术单独都无法实现这一点。
这两种技术的结合给我们提供了一个新视角,即如何利用 Dropout 来训练 DNN,并实现白化每一层输入的原始目标 (Le Cun et al., 1991; Ioffe & Szegedy, 2015)。
该研究的主要贡献如下:
在其新提出的独立组件(Independent Component,IC)层中结合了两种流行的技术:批归一化和 Dropout。该 IC 层可以降低任意一对神经元之间的交互信息和相关系数,这能加快网络的收敛速度。
为了证实该理论分析,研究者在 CIFAR10/100 和 ILSVRC2012 数据集上进行了广泛的实验。实验结果证明,本文的实现在三个方面提升了当下网络的分类性能:i) 更稳定的训练过程,ii) 更快的收敛速度,iii) 更好的收敛极限。
为什么要将 Dropout 和批归一化结合?
该研究的动机是重新寻找一种白化每一个输入层的高效计算方法。
白化(whitening)神经网络的输入能够实现较快的收敛速度,但众所周知,独立的激活函数必须白化。
研究者试图使每一个权重层的网络激活函数更加独立。最近的神经科学发现表明:神经系统的表征能力随群体中独立神经元数量的增加而线性增加(Moreno-Bote et al., 2014; Beaulieu-Laroche et al., 2018),这一发现可以支持以上做法。因此,研究者使得权重层的输入更加独立。独立的激活函数的确使得训练过程更加稳定。
生成独立组件的直观解决方案是引入一个附加层,该层在激活函数上执行独立组件分析(ICA)。Huang 等研究者(2018)也曾探索过类似的想法,他们采用零相位组件分析(ZCA)来白化网络激活函数,而不是使其独立。ZCA 总是作为 ICA 方法的第一步,但 ZCA 本身需要大量计算,对于宽神经网络来说尤其如此。
为了解决这一棘手的问题,研究者发现批归一化和 Dropout 可以结合在一起,为每个中间权重层中的神经元构建独立的激活函数。
Dropout 和批归一化怎么结合?
为表述方便,本文将 {-BatchNorm-Dropout-} 表示为独立组件(IC)层。IC 层以一种连续的方式将每对神经元分开,应用 IC 层可以使得神经元更加独立。本文所用的方法可以直观地解释为:
BatchNorm 归一化网络激活函数,使它们的均值和单位方差为零,就像 ZCA 方法一样。Dropout 通过在一个层中为神经元引入独立的随机门来构造独立的激活函数,允许神经元以概率 p 输出其值,否则输出 0 来停用它们。直观上来说,一个神经元的输出传递的信息很少一部分来自其他神经元。因此,我们可以假设这些神经元在统计上是彼此独立的。3.1 节在理论上证明,本文中提到的 IC 层可以将任意两个神经元输出之间的相互信息减少 p^2 倍,相关系数减少 p,其中 p 为 Dropout 概率。作者表示,据他们所知,以前从未有研究者提出 Dropout 的这种用法。
与 ICA 和 ZCA 等传统的无监督学习方法不同,研究者不需要从独立特征中恢复原始信号或保证这些特征的独特性,只需要提取一些有用特征即可,这样有助于实现监督学习任务。他们的分析表明,提出的 IC 层应置于权重层而非激活层之前。
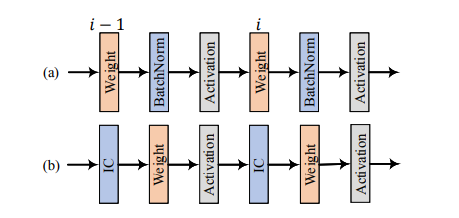
图 1:(a)在权重层和激活层之间执行白化运算(或称为 BatchNorm)的常见做法。(b)研究者提出将 IC 层置于权重层之前。
为评估 IC 层的实际使用情况,研究者利用 IC 层改进 ResNet 架构,发现这些架构的性能可以得到进一步提升。
CIFAR10/100 和 ILSVRC2012 数据集上的实证表明,提出的 IC 层能够提升当前网络的泛化性能。
IC 层的实现使得研究者重新思考 DNN 设计中将 BatchNorm 置于激活函数之前的常见做法。一些研究者已经论证了这样处理 BatchNorm 的有效性,但还没有分析来解释如何处理 BatchNorm 层。BatchNorm 的传统用法已被证明能够使得优化过程更加平滑,并使梯度行为的预测性更强且更稳定。
但是,BatchNorm 的此类用法依然阻止网络参数在梯度方向上进行更新,而这是实现最小损失的最快方法,并且呈现出一种曲折的优化行为。与之前批归一化和 Dropout 在激活层之前同时被使用不同,本文研究者提出,批归一化和 Dropout 的作用类似于 ICA 方法,所以应置于权重层之前。如此一来,训练深度神经网络时会实现更快的收敛速度。理论分析和实验结果表明,批归一化和 Dropout 应结合作为 IC 层,这样将来能够广泛应用于训练深度网络。
IC 层可以用几行 Python 代码轻松实现,如下图所示:

图 2:基于 Keras 用几行 Python 代码实现 IC 层。
实验
在本文中,研究者尝试用一堆 -IC-Weight-ReLU- 层来实现 ResNet。遵循 (He et al., 2016b),研究者研究了三种不同类型的残差单元,每种都有其独特的短路径,如图 3(b)所示,且旨在找到最好的残差单元。
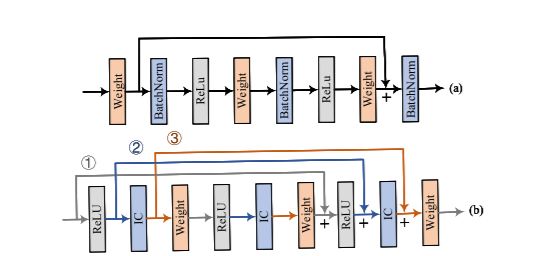
图 3:(a) 经典的 ResNet 架构,其中 + 表示求和。(b) 用 IC 层重构的 ResNet 架构。
研究者在基准数据集上实现了重构的 ResNet 架构,以评估 IC 层的实际效用。这些测试集包括 CIFAR10/100 和 ILSVRC2012 数据集。为了公平比较,研究者还为 IC 层引入了一对可训练的参数,该参数缩放和变换由 BatchNorm 归一化的值,这样重构的 ResNet 将具有与相应的基线架构相同数量的可训练参数。
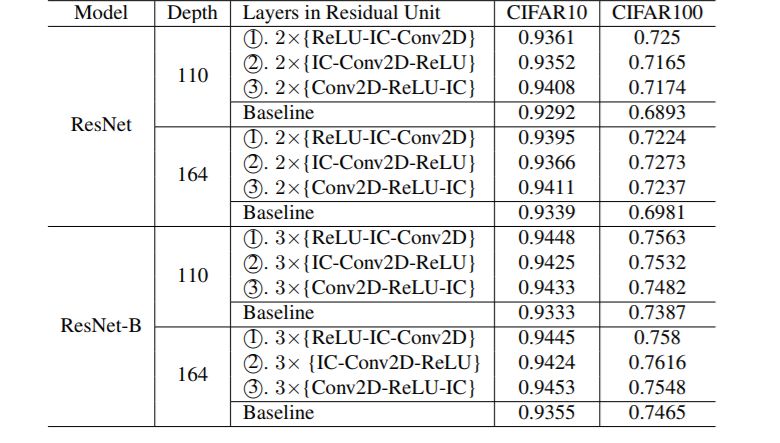
表 1:训练结束时,在 CIFAR10/100 数据集上 ResNet 和用 IC 层实现的 ResNet-B 的测试结果对比。
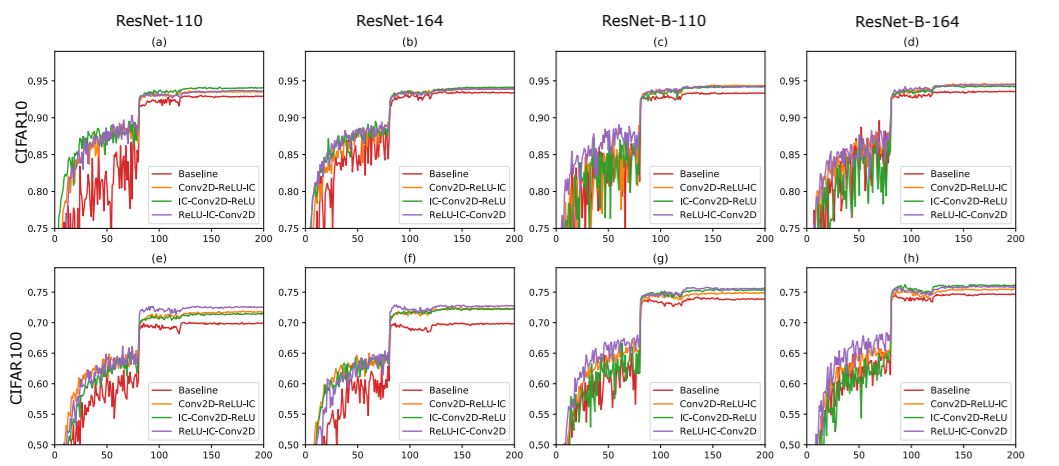
图 4:训练不同的 epoch 时,在 CIFAR10/100 数据集上 ResNet 和用 IC 层实现的 ResNet-B 的测试准确率。(a) 在 CIFAR 10 上实现的 ResNet110;(b) 在 CIFAR 10 上实现的 ResNet164;(c) 在 CIFAR 10 上实现的 ResNet-B 110;(d) 在 CIFAR 10 上实现的 ResNet-B 164;(e) 在 CIFAR 100 上实现的 ResNet110;(f) 在 CIFAR 100 上实现的 ResNet164;(g) 在 CIFAR 100 上实现的 ResNet-B 110;(h) 在 CIFAR 100 上实现的 ResNet-B 164。
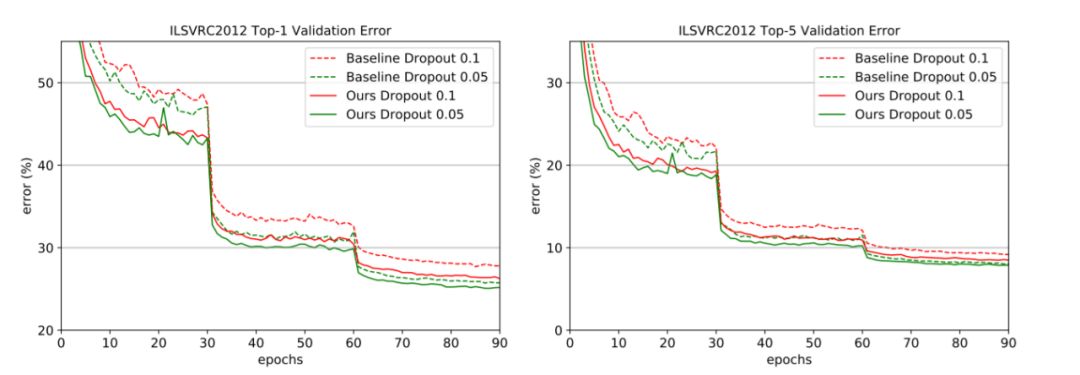
图 5:在 ImageNet 验证集上的 Top-1 和 Top-5(1-crop testing)误差率。
论文链接:https://arxiv.org/pdf/1905.05928.pdf
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~



