学界 | 谷歌大脑提出自动数据增强方法AutoAugment:可迁移至不同数据集
选自arXiv
作者:Ekin D. Cubuk 等
机器之心编译
参与:Geek AI、路
近日,来自谷歌大脑的研究者在 arXiv 上发表论文,提出一种自动搜索合适数据增强策略的方法 AutoAugment,该方法创建一个数据增强策略的搜索空间,利用搜索算法选取适合特定数据集的数据增强策略。此外,从一个数据集中学到的策略能够很好地迁移到其它相似的数据集上。
引言
深度神经网络是强大的机器学习系统,当使用海量数据训练时,深度神经网络往往能很好地工作。数据增强是一种通过随机「增广」来提高数据量和数据多样性的策略 [1-3]。在图像领域,常见的数据增强技术包括将图像平移几个像素,或者水平翻转图像。直观来看,数据增强被用来为模型引入数据域中的不变性:目标分类通常对水平翻转或平移是不敏感的。网络架构也可以被用于对不变性进行硬编码:卷积神经网络适用于平移不变性 [3-6],而物理模型适用于平移、旋转和原子排列的不变性 [7-12]。然而,使用数据增强技术来表达潜在的不变性比直接将不变性硬编码到模型中更简单。
然而,机器学习和计算机视觉社区的一个大的关注点是设计出更好的网络架构(例如 [13-21])。人们较少将精力放在寻找引入更多不变性的更好的数据增强方法上。例如,在 ImageNet 上,Alex 等人 [3] 在 2012 年引入的数据增强方法仍然是现在的标准操作,仅有微小的改变。即使对特定数据集找到了数据增强的改进方法,这些方法通常也不能有效地迁移到其他的数据集上。例如,在训练期间对图像进行水平翻转在 CIFAR-10 数据集上是一个有效的数据增强方法,但是在 MNIST 上并不奏效,这是因为这些数据集中出现的对称性不同。最近,对自动学习到的数据增强技术的需求发展成为一个重要的待解决问题 [22]。
在本论文中,作者旨在实现为目标数据集寻找有效数据增强策略的自动化过程。在本文第三节的实现中,每个策略都表示一些可能的数据增强操作的选项和顺序,其中每一个操作是图像处理函数(例如,平移、旋转或色彩归一化),及应用该函数的概率和幅度(magnitude)。作者使用一种搜索算法寻找这些操作的最佳选项和顺序,以使这样训练出的神经网络能获得最佳的验证准确率。在本文的实验中,作者使用增强学习 [23] 作为搜索算法,但是作者认为如果使用更好的算法 [21,24],结果可以得到进一步改进。
作者提出的方法在 CIFAR-10、简化的 CIFAR-10、CIFAR-100、SVHN、简化的 SVHN,以及 ImageNet(不添加额外数据)等数据集上取得了目前最高的准确率。在 CIFAR-10 上的误差率为 1.48%,比之前最先进的模型 [21] 的误差率低 0.65%。在 SVHN 上,作者将目前最低的误差率从 1.30% [25] 降低到了 1.02%。在简化数据集上,本文提出的方法取得了和不使用任何非标注数据的半监督方法相当的性能。在 ImageNet 数据集上,作者提出的方法达到了 83.54% 的 Top-1 准确率。最后,作者展示了在一个任务中找到的策略可以很好地泛化到不同的模型和数据集上。例如,在 ImageNet 上发现的策略能在各种各样的 FGVC 数据集上带来显著的性能提升。即使在那些对在 ImageNet 上预训练好的权重进行调优也帮助不大的数据集上 [26],例如 Stanford Cars [27] 和 FGVC Aircraft [28],使用 ImageNet 上的策略训练可以分别减少 1.16% 和 1.76% 的误差率。这一结果表明迁移数据增强策略为迁移学习提供了一种新的可选方案。
AutoAugment
作者将寻找最佳数据增强策略的问题形式化为一个离散搜索问题。在搜索空间中,一个策略由 5 个子策略组成,每个子策略又包含依次被应用的两个图像处理操作,每个操作也都和两个超参数相关:1)应用操作的概率 2)操作的幅度。
图 1 展示了在搜索空间中的一个包含 5 个子策略的策略示例。第一个子策略指定了依次进行对 X 坐标的剪切(ShearX)和图像翻转操作(Invert)。应用 ShearX 操作的概率是 0.9,并且当应用这个操作时,其幅度为十分之七。接着,作者以 0.8 的概率应用 Invert 操作,该操作不使用幅度信息。作者强调这些操作需要按照指定顺序执行。

图 1:在 SVHN 上发现的一个策略,以及如何使用它在给定用于训练神经网络的原始图像的条件下来生成增强后的数据。这个策略包含 5 个子策略。对于小批量中的每一张图像,作者均匀地随机选取一个子策略去生成一张变换后的图像来训练神经网络。每个子策略由两个操作组成,每个操作都与两个数值相关联:调用操作的概率、操作的幅度。由于存在调用操作的概率,因此该操作在这个小批量中可能不被应用。然而,如果它被应用了,这个应用的幅度就是固定的。作者通过展示即使使用相同的子策略,一个示例图片能够在不同的小批量中被不同地变换,强调了应用子策略的随机性。正如文中所解释的,在 SVHN 上,AutoAugment 更常采取几何变换措施。我们可以从中看出为什么翻转(Invert)在 SVHN 上是一个被普遍选择的操作,因为图像中的数字在这种变换下具有不变性。
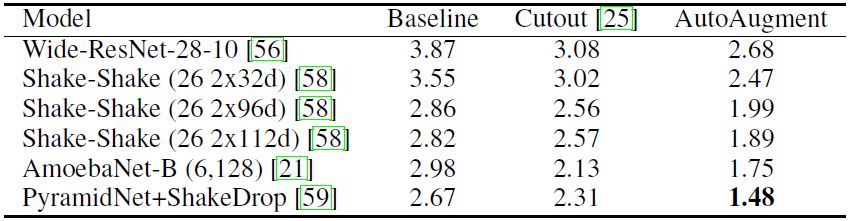
表 1:在 CIFAR-10 上的测试集误差率(%)。此误差率越低越好。本文的实验复现了所有基线模型和带 Cutout 的基线模型结果,并且与之前报告的结果 [25,56,58,59] 相匹配。只有 Shake-Shake(26 2x112d)网络例外,该网络比 [58] 中最大的模型拥有更多的滤波器——112 vs 96,而且结果也与之前论文中报告的不同。请注意,在简化的 CIFAR-10 上找到了最好的策略。

表 2:在 CIFAR-100 上的测试集误差率(%)。本文的实验复现了 Wide-ResNet 和 ShakeDrop 的基线模型和 Cutout 模型结果,并且与之前报告的结果 [25,59] 相匹配。请注意,在简化 CIFAR-10 上找到了最佳的策略。

图 2:在 ImageNet 上一个成功的数据增强策略。如文中所描述的,大多数在 ImageNet 上建立的策略使用了基于色彩的转换。
论文:AutoAugment: Learning Augmentation Policies from Data

论文链接:https://arxiv.org/abs/1805.09501
摘要:在本论文中,我们进一步研究了用于图像的数据增强技术,并提出了一个名为「AutoAugment」的简单过程,用来搜索改进的数据增强策略。本文主要的观点是创建一个数据增强策略的搜索空间,直接在感兴趣的数据集上评估特定策略的质量。在「AutoAugment」的实现过程中,我们设计了一个搜索空间,该搜索空间中的一个策略包含了许多子策略,我们为每个小批量(mini-batch)中的每张图像随机选择一个子策略。每个子策略由两个操作组成,每个操作都是类似于平移、旋转或剪切的图像处理函数,以及应用这些函数的概率和幅度(magnitude)。我们使用搜索算法来寻找最佳策略,这样神经网络就能在目标数据集上获得最高的验证准确率。我们的方法在 CIFAR-10、CIFAR-100、SVHN 和 ImageNet 上取得了目前最高的准确率(在不加入额外数据的情况下)。在 ImageNet 上,我们取得了 83.54% 的 Top-1 准确率。在 CIFAR-10 上,我们取得了 1.48% 的误差率,比之前最佳模型的误差率低 0.65%。在简化数据集上,AutoAugment 的性能与不使用任何非标注样本的半监督学习方法相当。最后,从一个数据集中学到的策略能够被很好地迁移到其它相似的数据集上。例如,在 ImageNet 上学到的策略能够让我们在细粒度视觉分类数据集 Stanford Cars 上取得目前最高的准确率,并且不用在额外的数据上对预训练的权重进行调优。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



