深度学习 | Keras自动编码器实现信用卡欺诈侦测建模
今天本计划飞广州,结果到机场后航班全部取消,只好返回学校,吃午饭到实验室与同学们交流最近的情况,静下心来写写深度学习建模的心得。
看到一篇国外博客关于用Keras的autoencoder自编码器模型做银行信用卡欺诈的分类模型,比较有兴趣,因为过去采用数据挖掘建模做过类似模型,现在看看如何用Deep Autoencoder来玩模型。

建立银行客户信用卡欺诈模型传统上主要借助数据挖掘建模技术,一般采用统计建模或机器学习算法,比如罗辑斯特回归logistics,判别分析等多变量统计方法,或者决策树、支持向量机SVM、贝叶斯网络、最近邻居法KNN、神经网络Nearul Network等,这里的神经网络建模主要还是单隐含层的机器学习算法。
最近深度学习技术开始流行,特别是在图像识别、自动驾驶、机器翻译、游戏Player等领域有了飞速发展。特别是google开源了tensorflow库后,加上Keras的开源顶层框架,使得深度学习建模技术应用价值和潜在应用场景广泛而深远,特别是最近人工智能AI的火爆,更凸显了深度学习技术在大数据支撑下的技术迭代。
最近开始学习深度学习的基本算法和建模技巧,深感在大数据背景下,有了机器学习不爱用统计技术了,有了深度学习谁还用机器学习。当然这是调侃,只是强大深度学习有可能带来算法的革命!
下面我通过学习演示采用Keras的自动解码器模型(auotencoding)分析银行信用卡的欺诈侦测模型。
推荐你的系统预先要安装:
1-Python2.7,推荐Anaconda安装Python环境,会自动予安装很多依赖包。
2-Tensorflow包,google开源的,目前最流行的深度学习包。
3-Keras包,支持Tensorflow和Theano作为backend,俺一直选Tensorflow。
我比较喜欢用Jupyter Notebook进行交互编程。
首先我们加载需要的各种Python包:
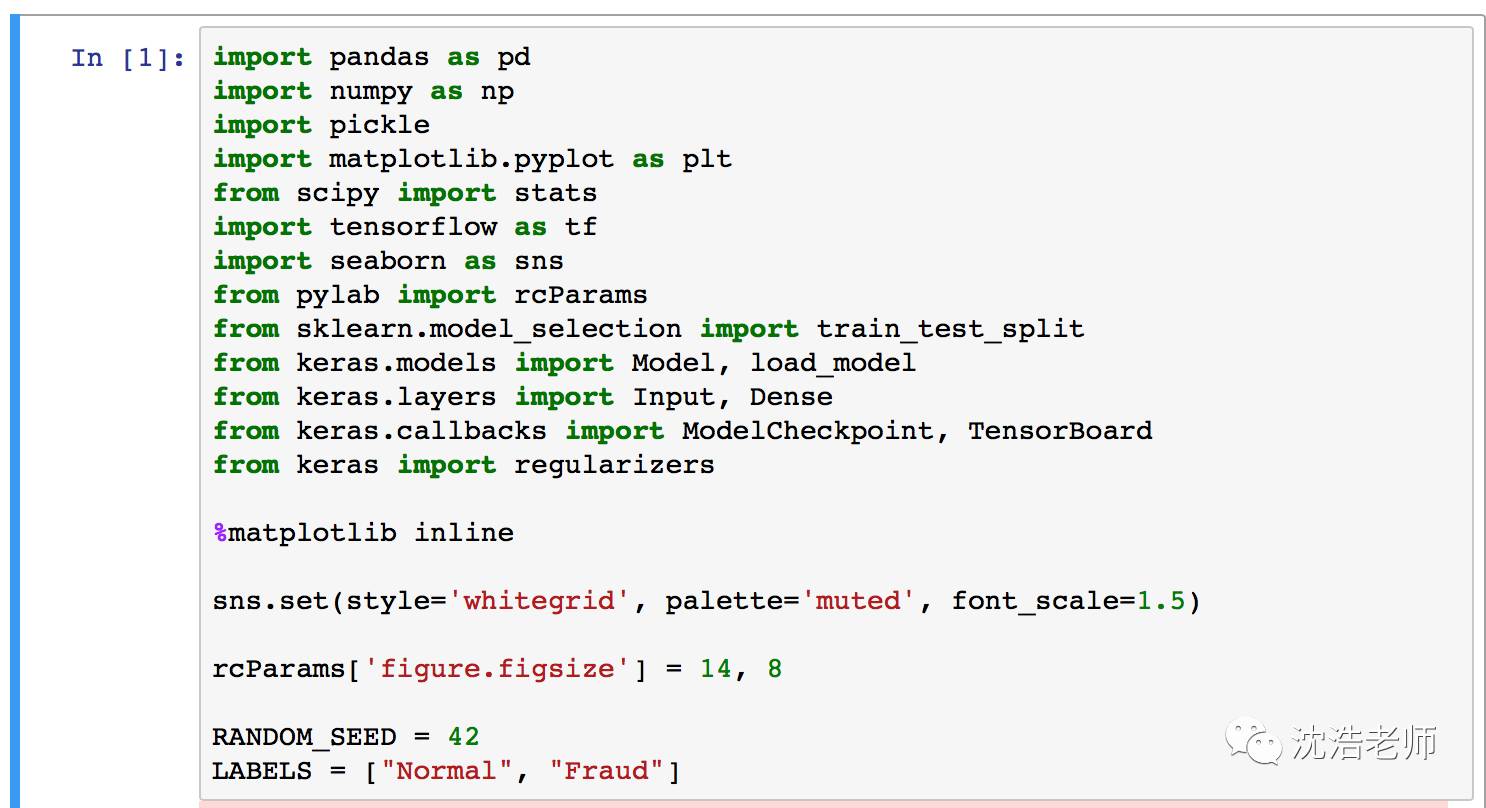
Using TensorFlow backend.
深度学习严重依赖numpy、sklearn、pandas、scipy等各种数组运算能力和数学矩阵算法。
加载银行信用卡数据,俺存储在启动目录的 'data/creditcard.csv'
数据加载为Pandas数据格式
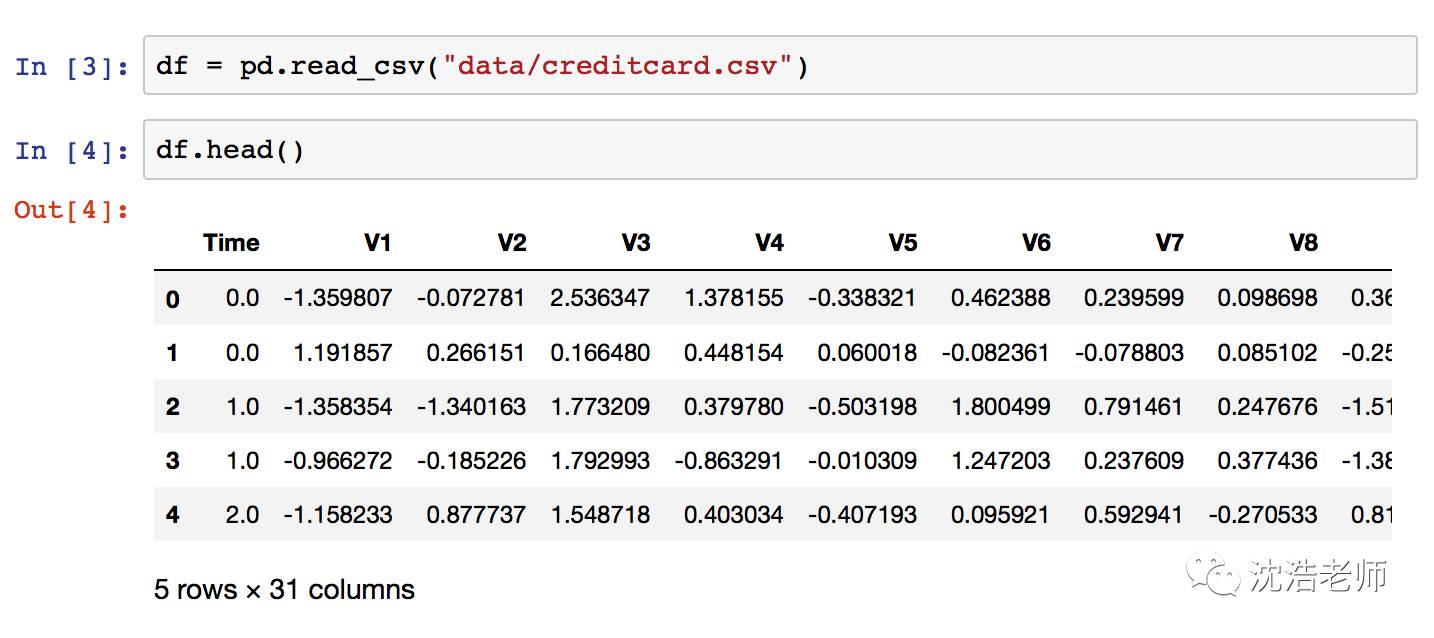
数据源来自 Kaggle,看狗kaggle是数据科学之家,大量悬赏性建模项目都在上面,喜欢数据科学的都应该尽快建立一个账号,有大量的数据开源,同时能看到世界建模高手的源代码,甚至可以直接在上面运行代码,主要都是Python和R语言。
数据源包含两天的284807笔交易记录,其中有492笔交易是标注为欺诈。
特别说明:影响欺诈因素包含有25个数值型自变量v1 to v28,我们看不到原始数据,而是经过PCA主成分分析后产生的25个主成分变量,这给了我一个启发:这也是数据脱敏技术的重要手段,今后如果涉及数据隐私可以进行PCA变换后提交给第三方。
另外有两个变量没有改变,交易Time和交易金额Amount;
其中Time是表示该笔交易与前一笔交易的间隔时间(秒);
我们简单看看数据结构:31列变量
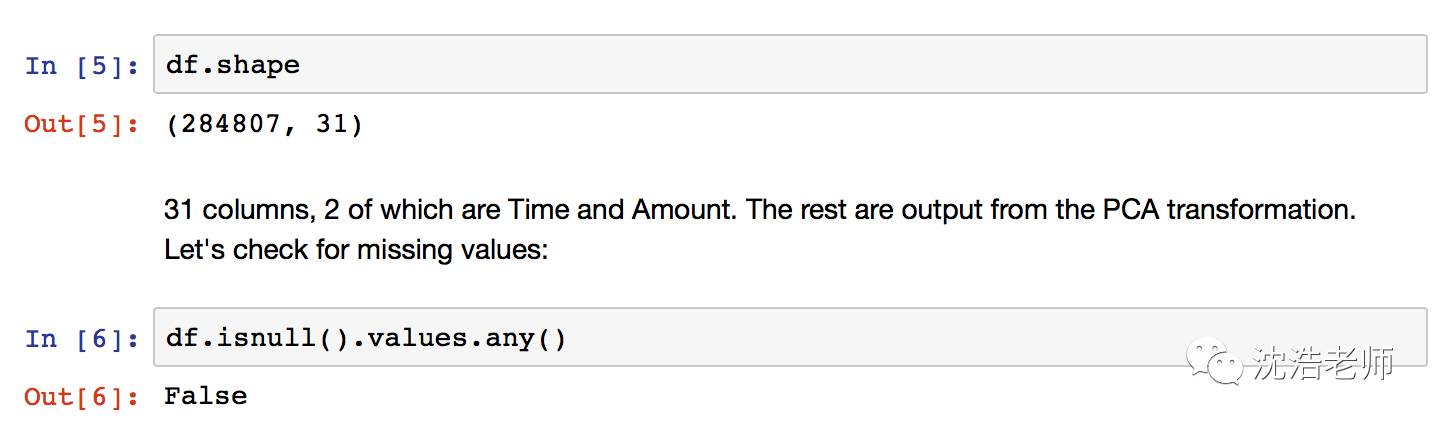
也没有缺失值missing value。
最后一列是Class:1-Fraud,0-Normal
我们看看目标变量class的分布情况:
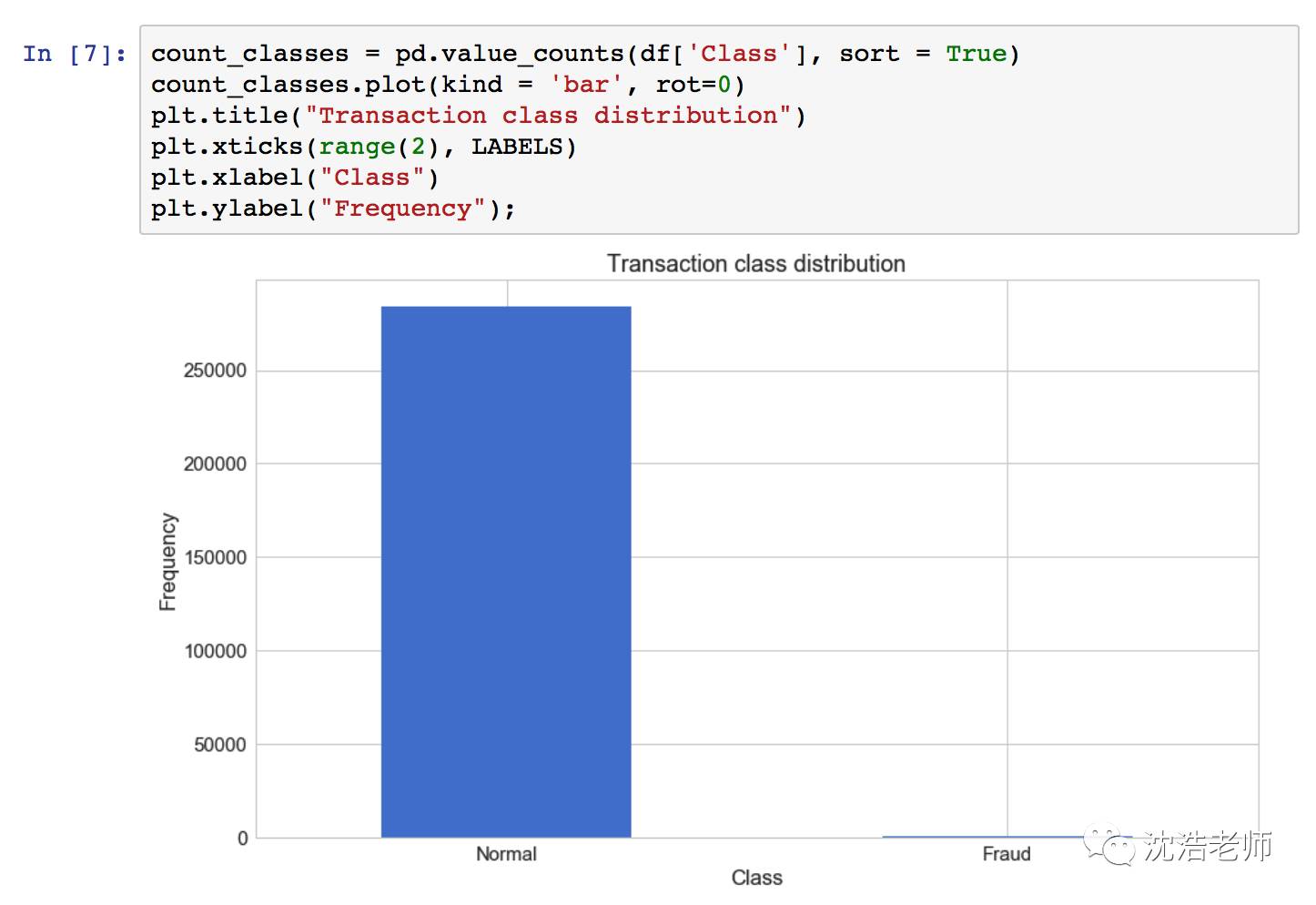
从图中看出,欺诈类别是粒度非常不平衡的,28多万笔交易中欺诈比例非常小,当然这是再正常不过了,如果有10%的欺诈银行估计该倒闭了,呵呵。
在传统的数据挖掘建模中,往往针对这种情况需要进行过度抽样或进行交叉验证技术验证模型。
我先进行描述性统计分析,看看数据结构和统计量
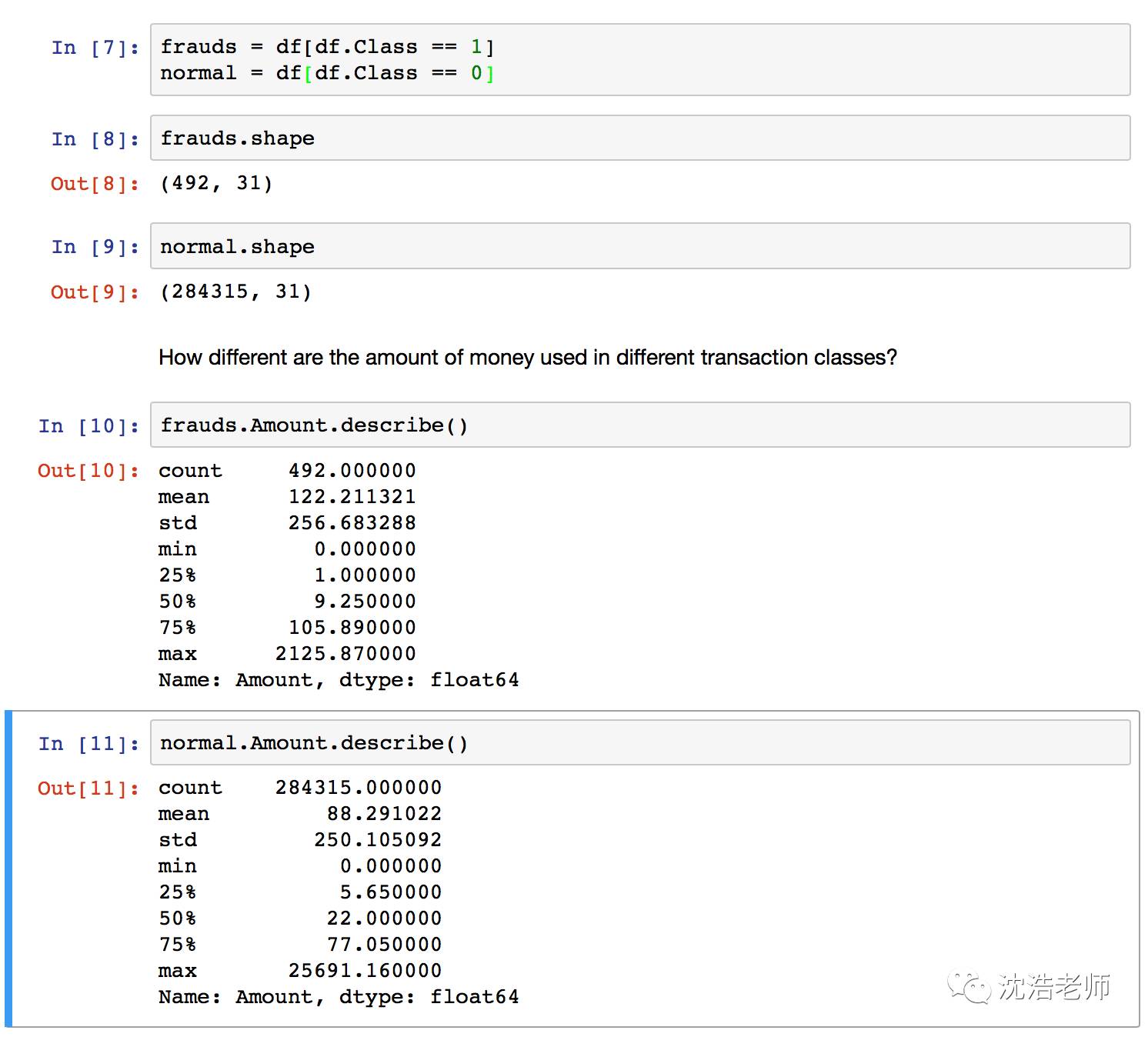
采用交易金额数量进行class分类图表分析:
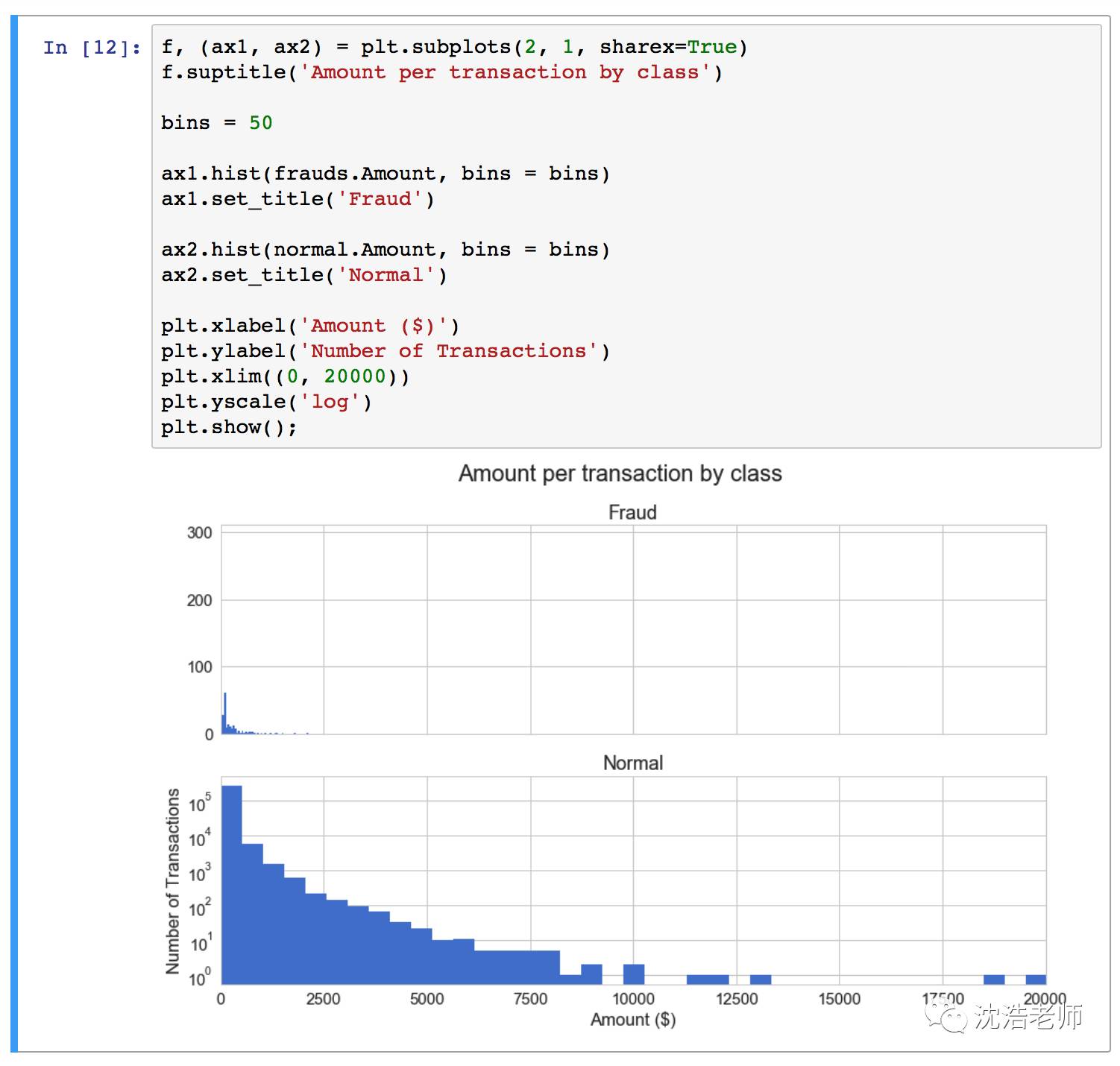
采用交易时间线进行class分类图表分析:
自动编码器的深度学习建模:Autoencoder
自动编码器建模是一张特殊的深度学习算法,主要使用如下函数:
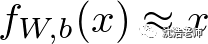
通过输入数据,抽象数据结构,将多维或高维数据压缩成为低维数据表现,进行编码器encode,然后将压缩降维后数据输入作为解码器进行表现,使之更准确代表原始输出结果,这里是解释能够更好代表Class类别分类正确性。
深度学习算法主要是数学知识,有必要重新复习一些线性代数、高等数据的基础知识了,比如;微分、求导、矩阵变换、映射、函数变换等。
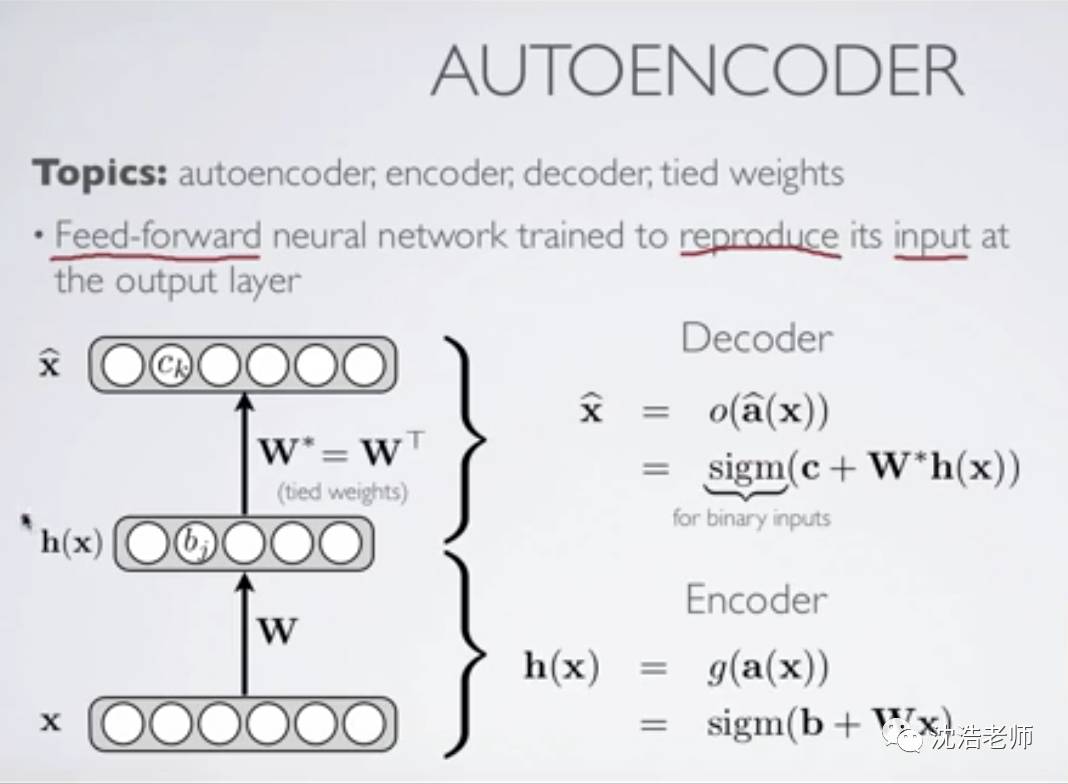
图示可视化自动编码器模型如下:
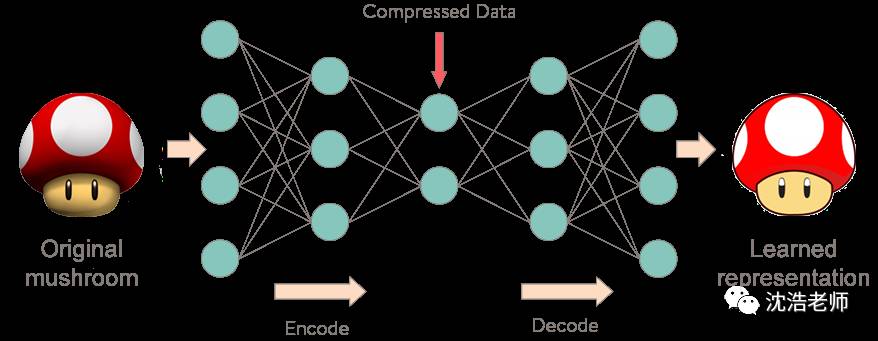
包括输入层,编码器网络,解码器网络,输出层。
模型优化和参数调整:
深度学习的重要特征就是输入层经过隐含层与输出层不断传递过程叫向前传播,为了得多最优化解或权重,需要不断向后传播调整权重,修正参数期望得到最优解。也就是为了使得输入的误差与输出后重构的误差最小化。
这里采用了传统的绝对误差平方:
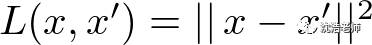
准备深度学习Autoencoder自动编码器数据:

我们采用深度学习算法的时候,我们已经不需要时间Time变量了,同时我们引入sklearn的StandardScaler函数将交易额Amount数据标准化为(-1,1)之间。
这里强调,深度学习一般都需要将数据标准化,(0,1)或(-1,1)之间。
将数据拆分为train和test数据集:train=0.80,test=0.20
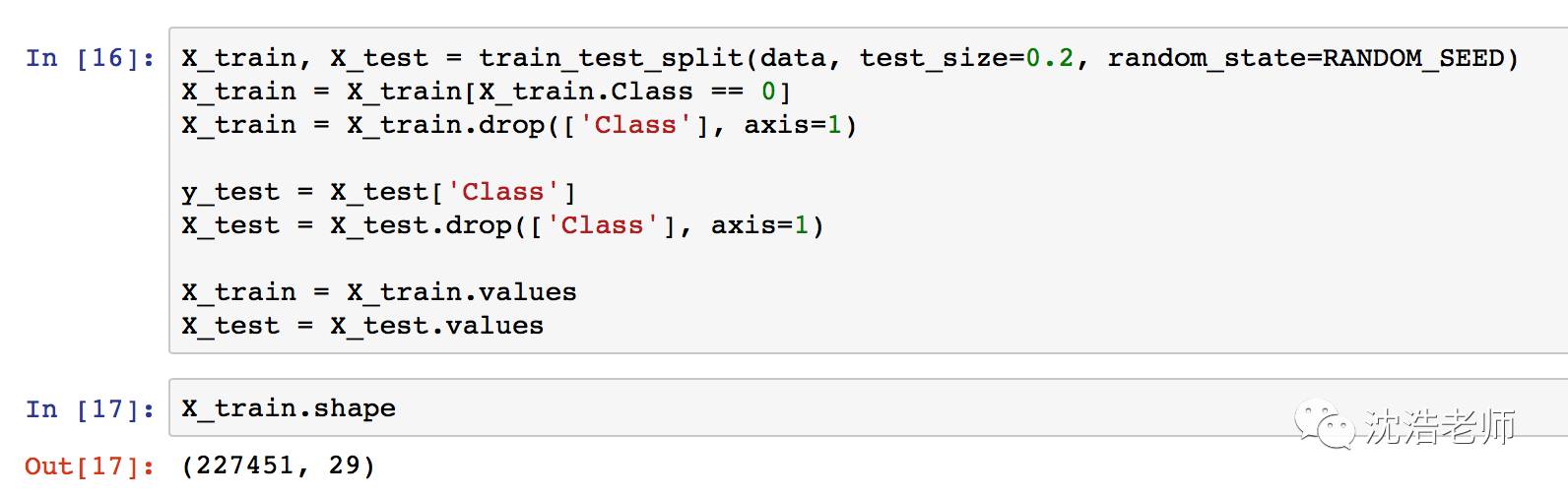
随机种子设定一开始就设好了,以便可以重复建模。
在拆分数据集中我们也drop掉了class变量,一方面可以看出自动编码器算法Autoencoder实际上是一种特殊的非监督类算法,或者是半监督类算法。
搭建Autoencoder模型:
自动编码器分别建立4个完全连接Dense层,分别为14,7,7,29个神经元。前两层用于编码器encode,最后两层用于解码器decode。训练期间将使用L1正规化

深度学习建模一般是先搭建好神经网络的模型框架,后面进行编译和拟合时加载数据集。
编码器和解码器层分别采用了“tanh”和“relu”激活函数。
训练模型设定为100个epochs,批量bitch大小为32个样本,并将最佳性能模型check-point点保存到一个文件。由Keras提供的ModelCheckpoint对于这些任务来说非常方便。此外,训练进度将以TensorBoard了解的格式导出。
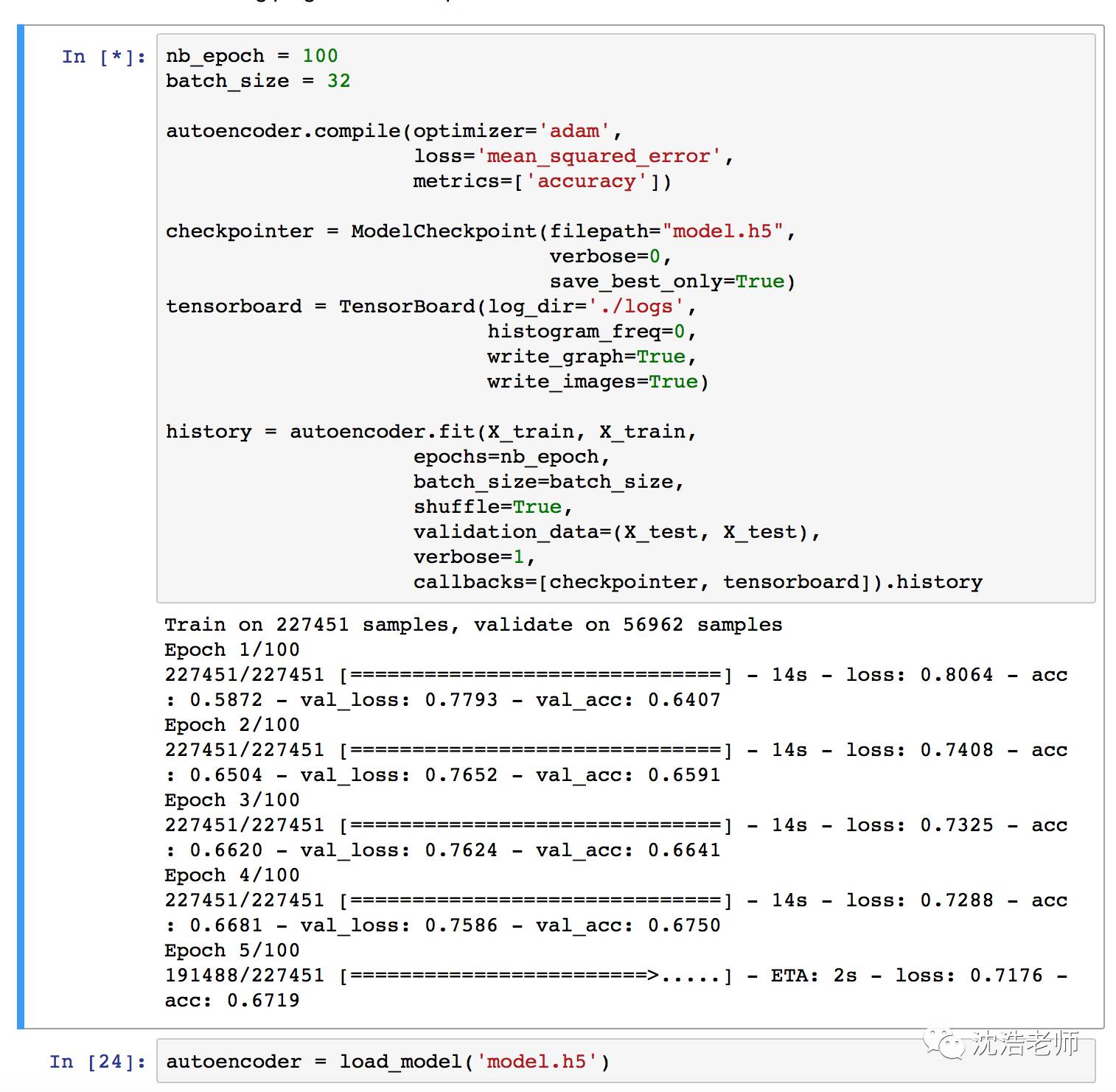
最终模型经过大概50分钟的训练,完成!重新加载存储的model.h5数据集。
俺一直在考虑是否购买带GPU的电脑,很多大的数据训练CPU够呛,不过还是先在AWS上注册采用GPU的云计算模式试试。
评估一些模型效果:
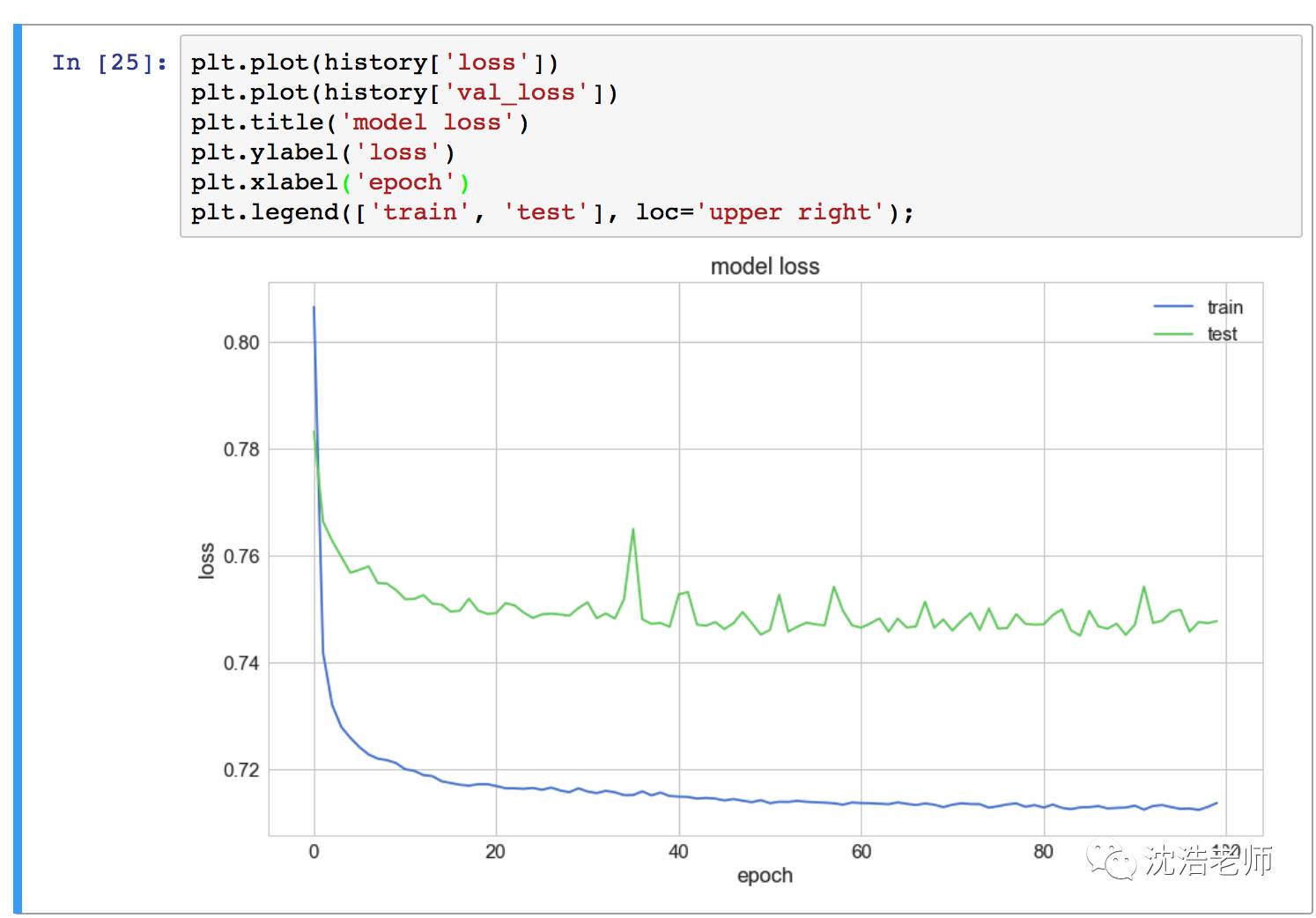
模型的损失基本上维持在0.76以下,可以看出经过100个epochs迭代较好收敛。
预测一下测试数据集的情况:
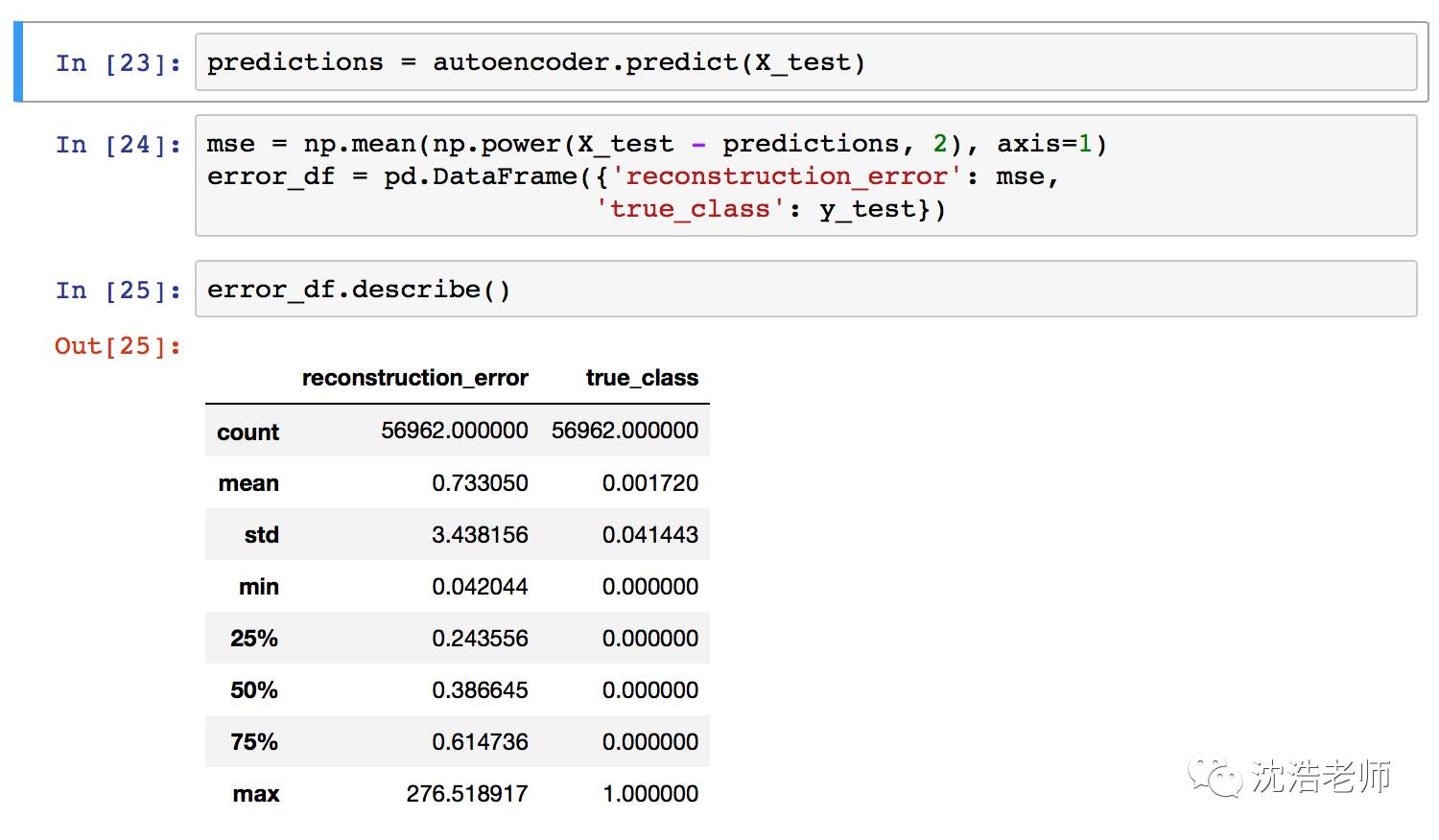
重构后的解码器预测测试集平均误差在0.73左右。
重构不含欺诈记录的错误分布:
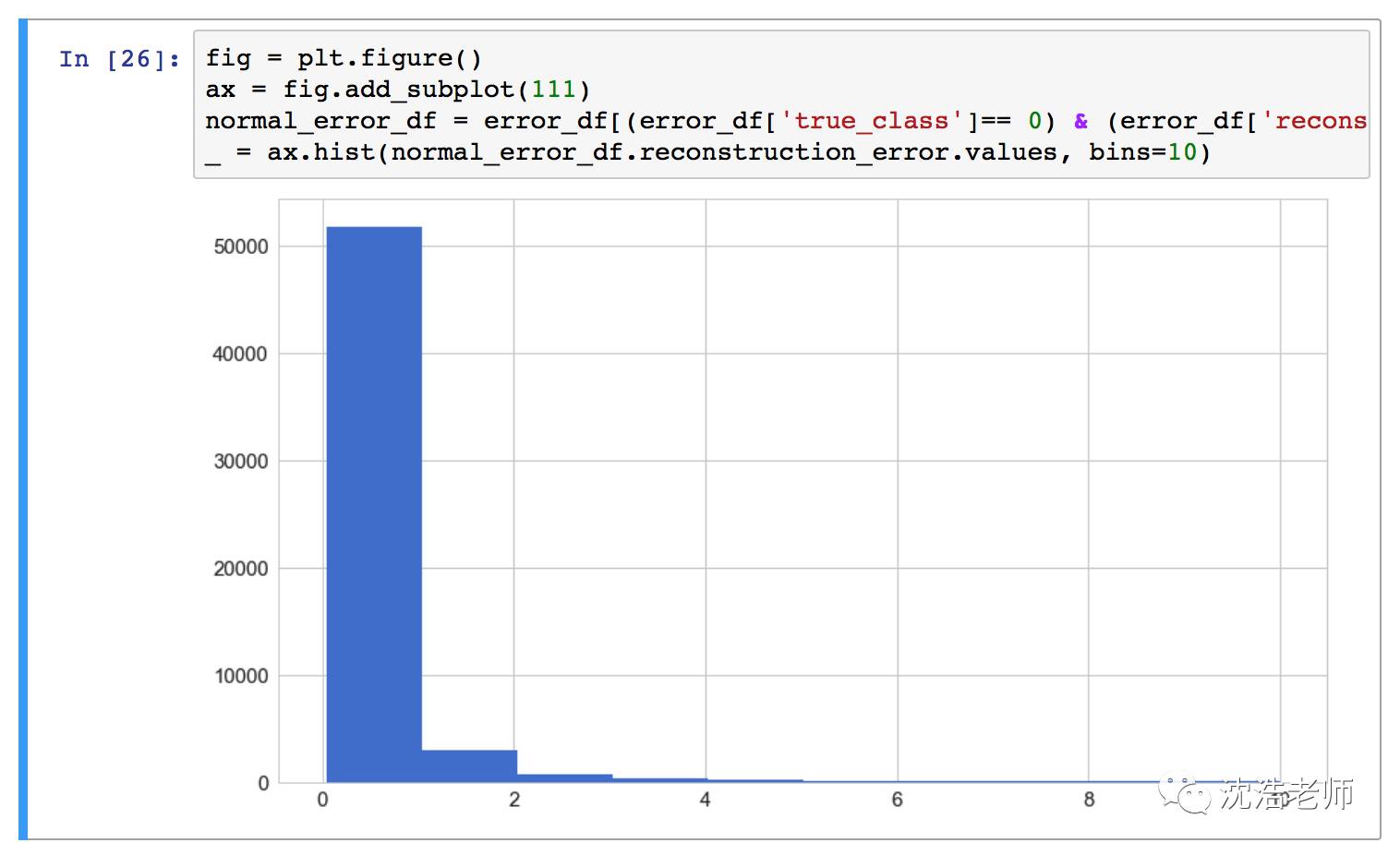
重构含有欺诈记录的错误分布:
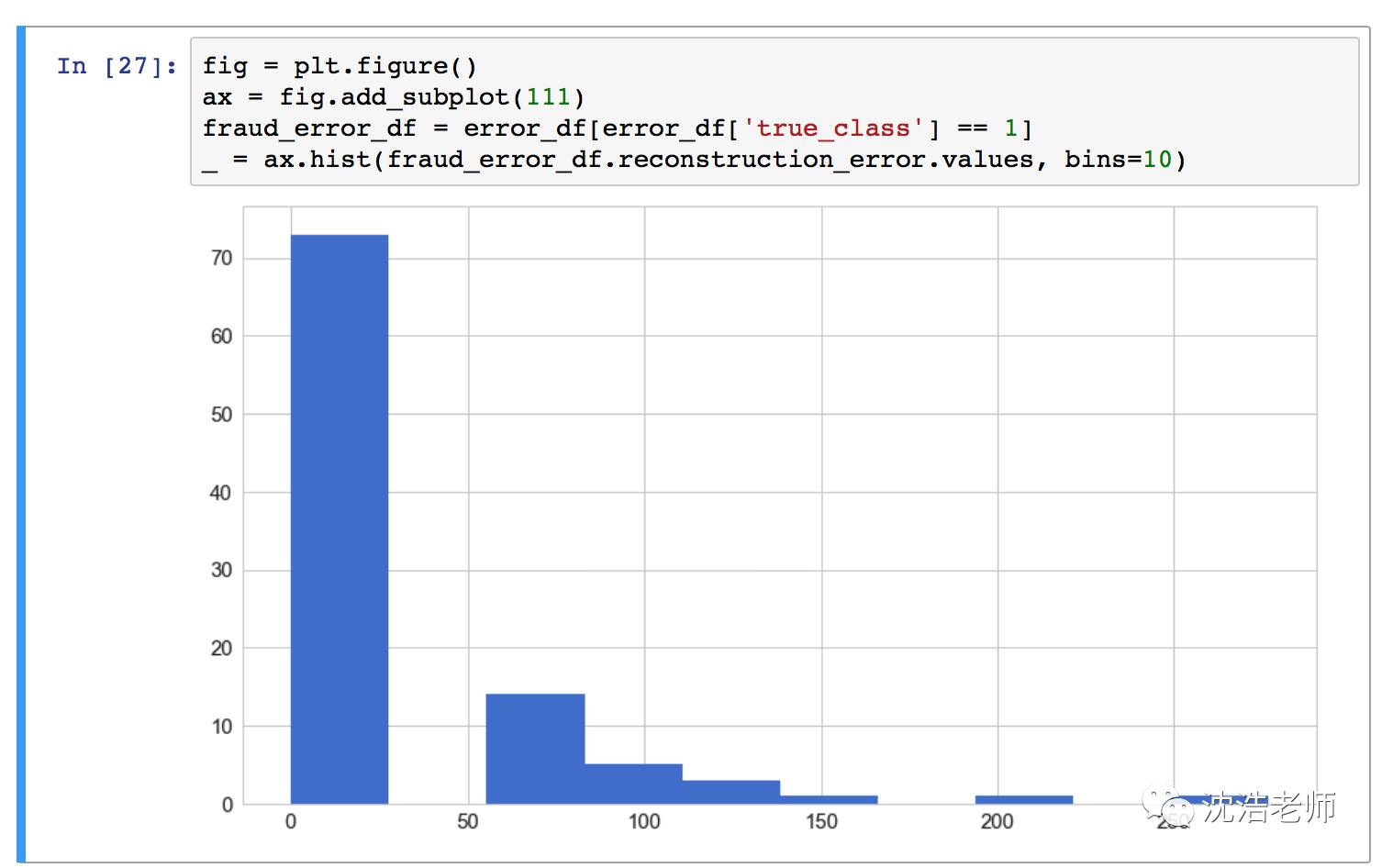
ROC模型评估图:
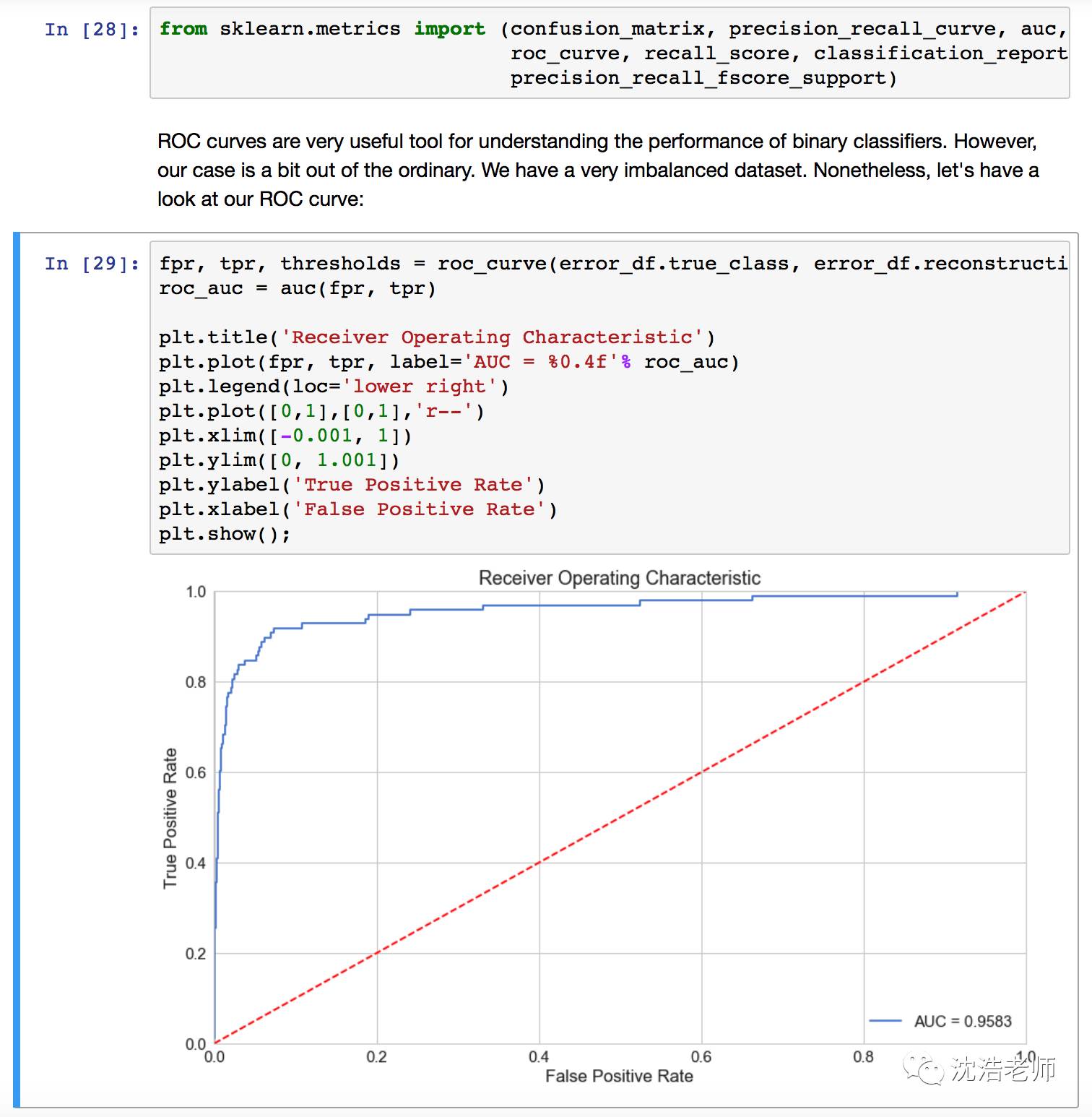
ROC模型评估曲线非常不错,说明模型有效,可以较好的侦测到欺诈者,准确度95.83%; ROC是累计风险评估曲线。
精确度和召回率:
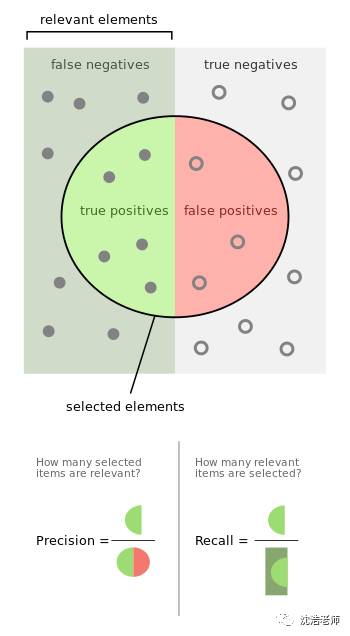
为了更好地了解什么是精确度和召回率,其中精度测量结果的相关性,衡量有多少相关结果被召回。这两个值都可以取0到1之间的值。当然值=1最好。
一般高召回但低精度意味着许多结果,其中大部分具有低或无相关性。精度很高但是回忆很低时,有相反的回报结果与相关性很高。理想情况下,需要高精度和高回想率。(类似一种错误的分类矩阵)

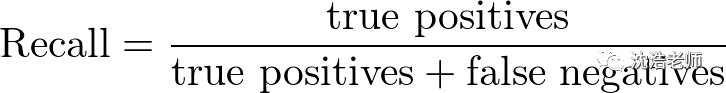
我们先计算召回率与精确度:
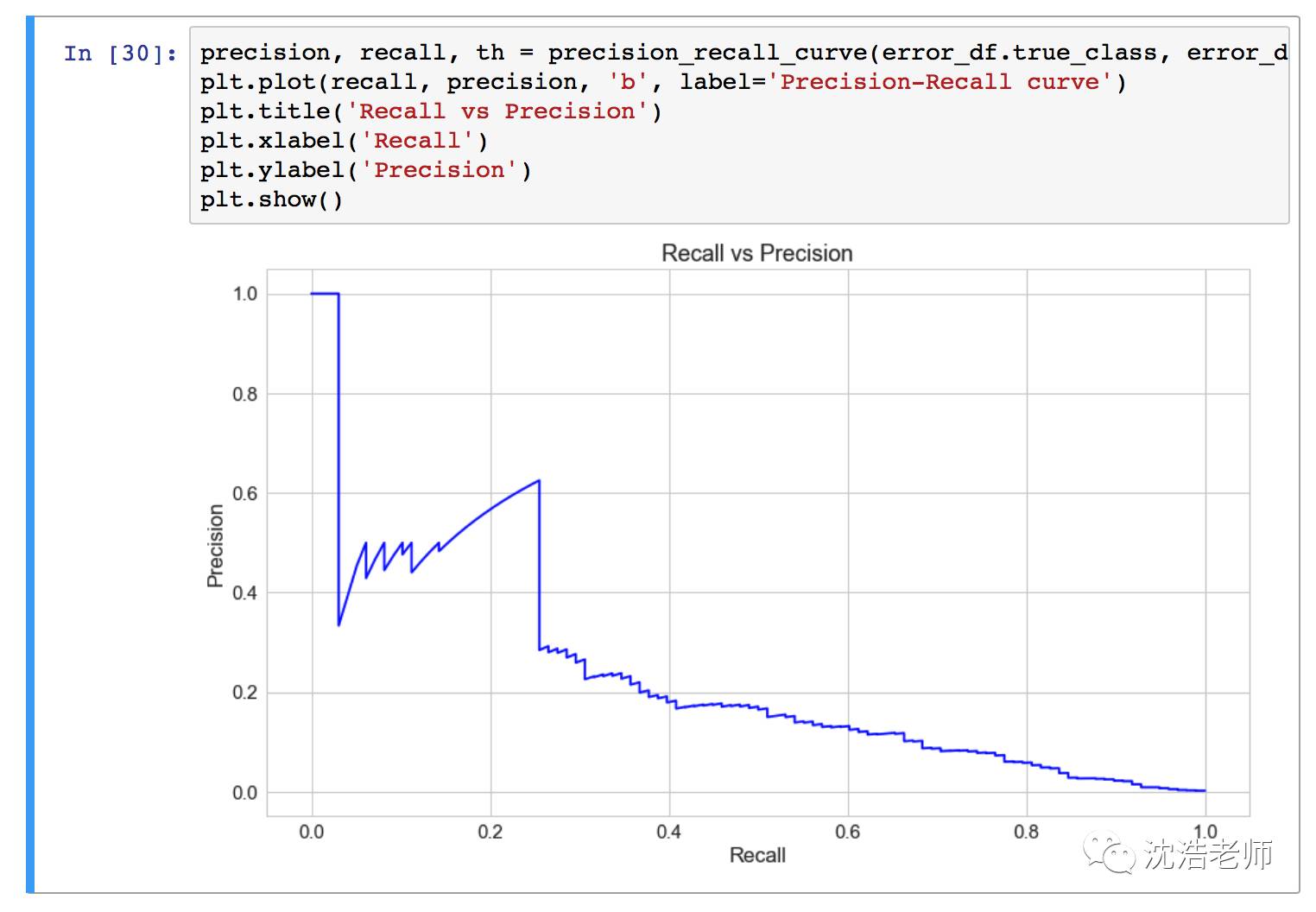
不同阀值Threshold的精确度:
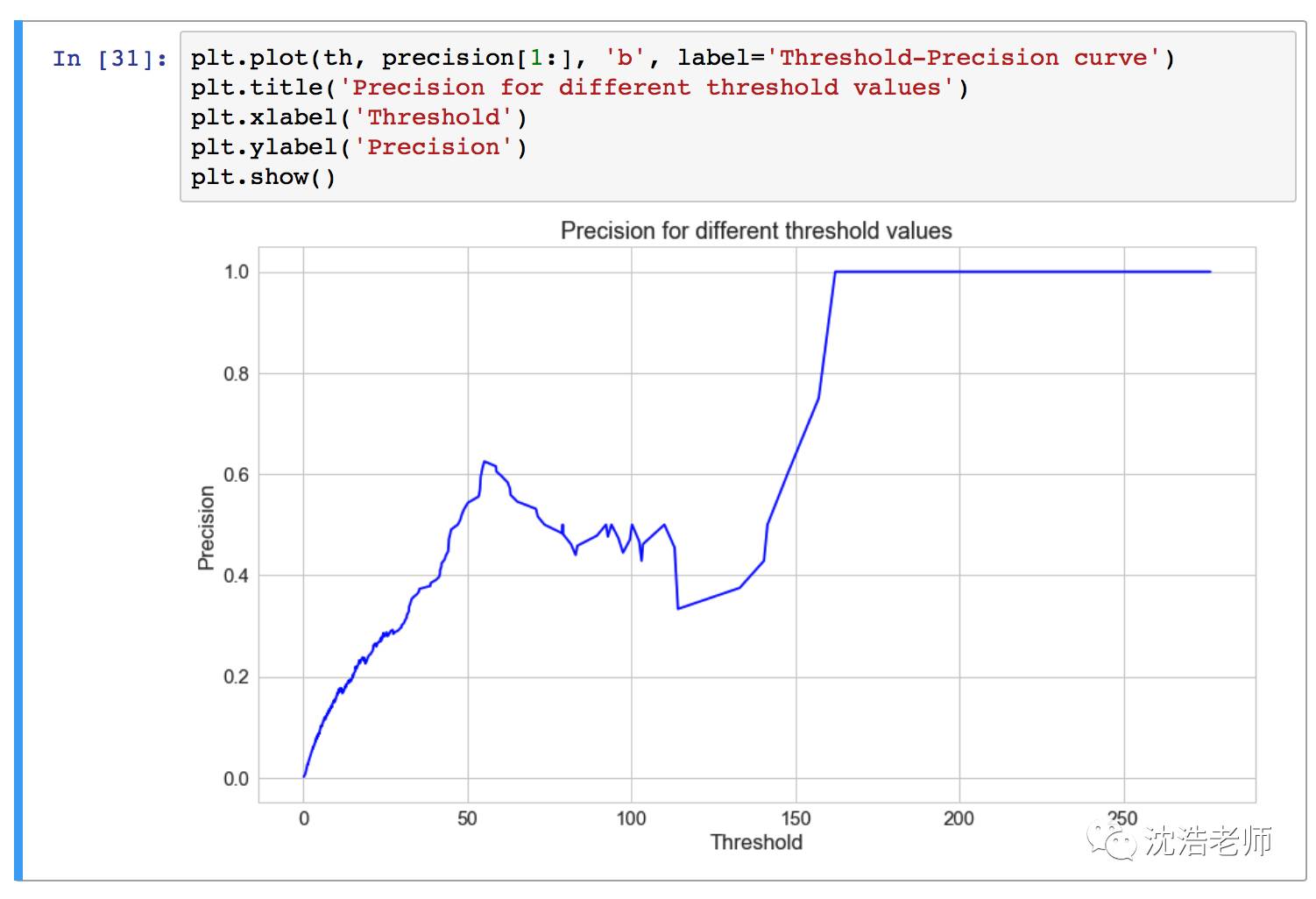
不同阀值的召回率:
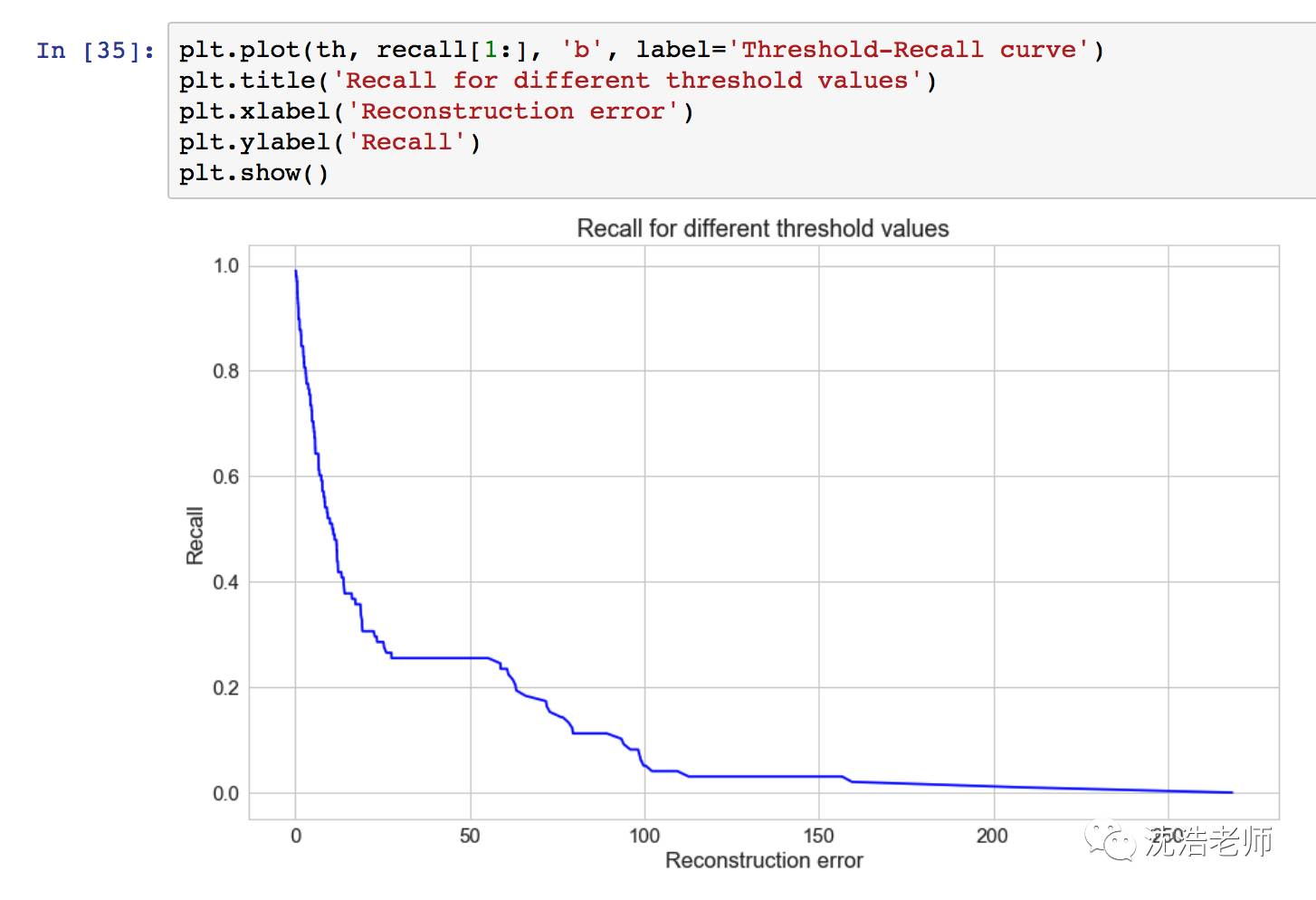
为了预测新/不可见的信用卡交易是否正常或欺诈,我们可以从交易数据本身计算重建错误。如果错误大于预定阈值,我们将其标记为欺诈
(我们期望的模型在正常交易中应该有一个低错误),设定阀值:threshold=2.9,看看预测情况:
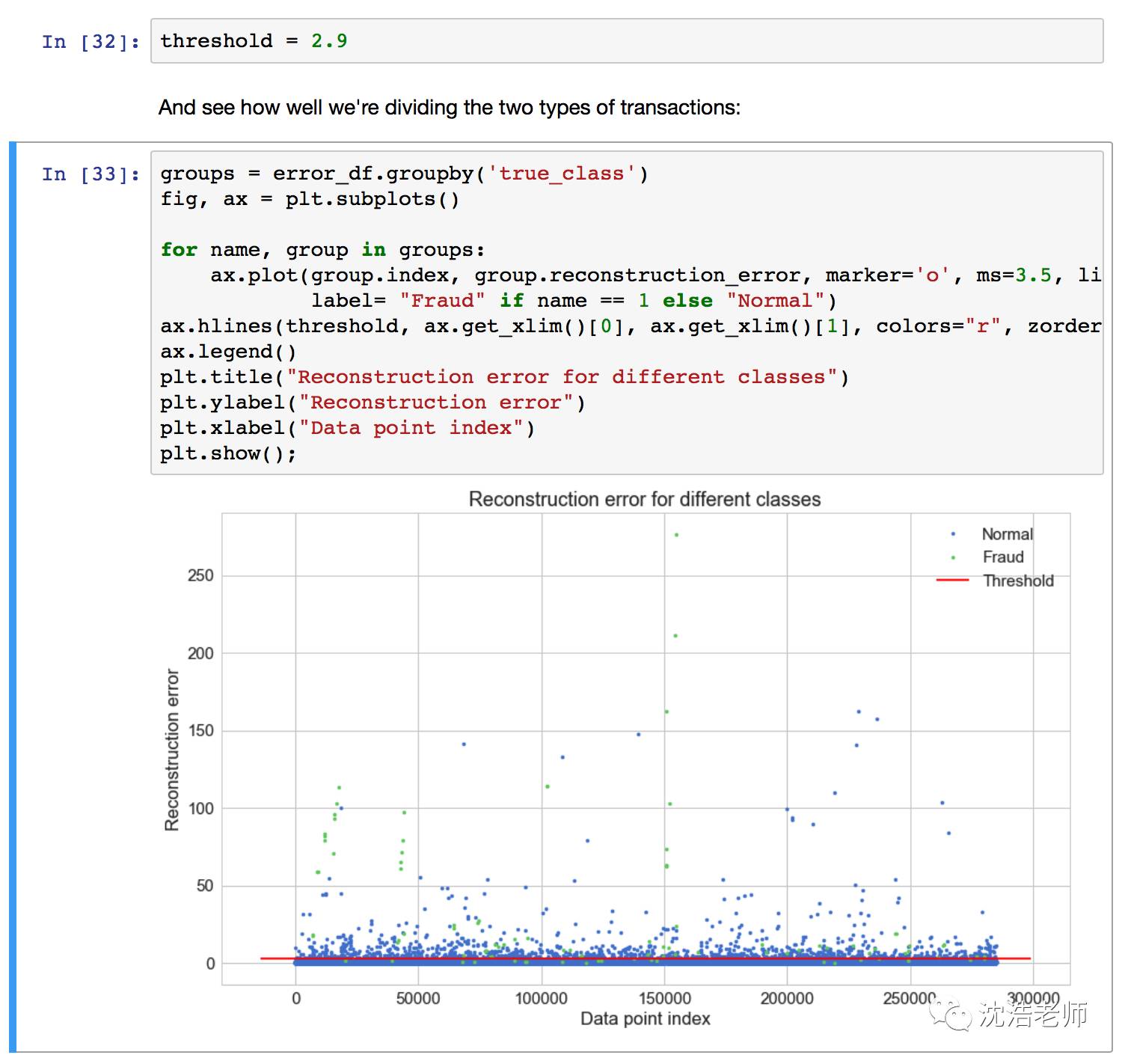
更直观的错误分类矩阵:
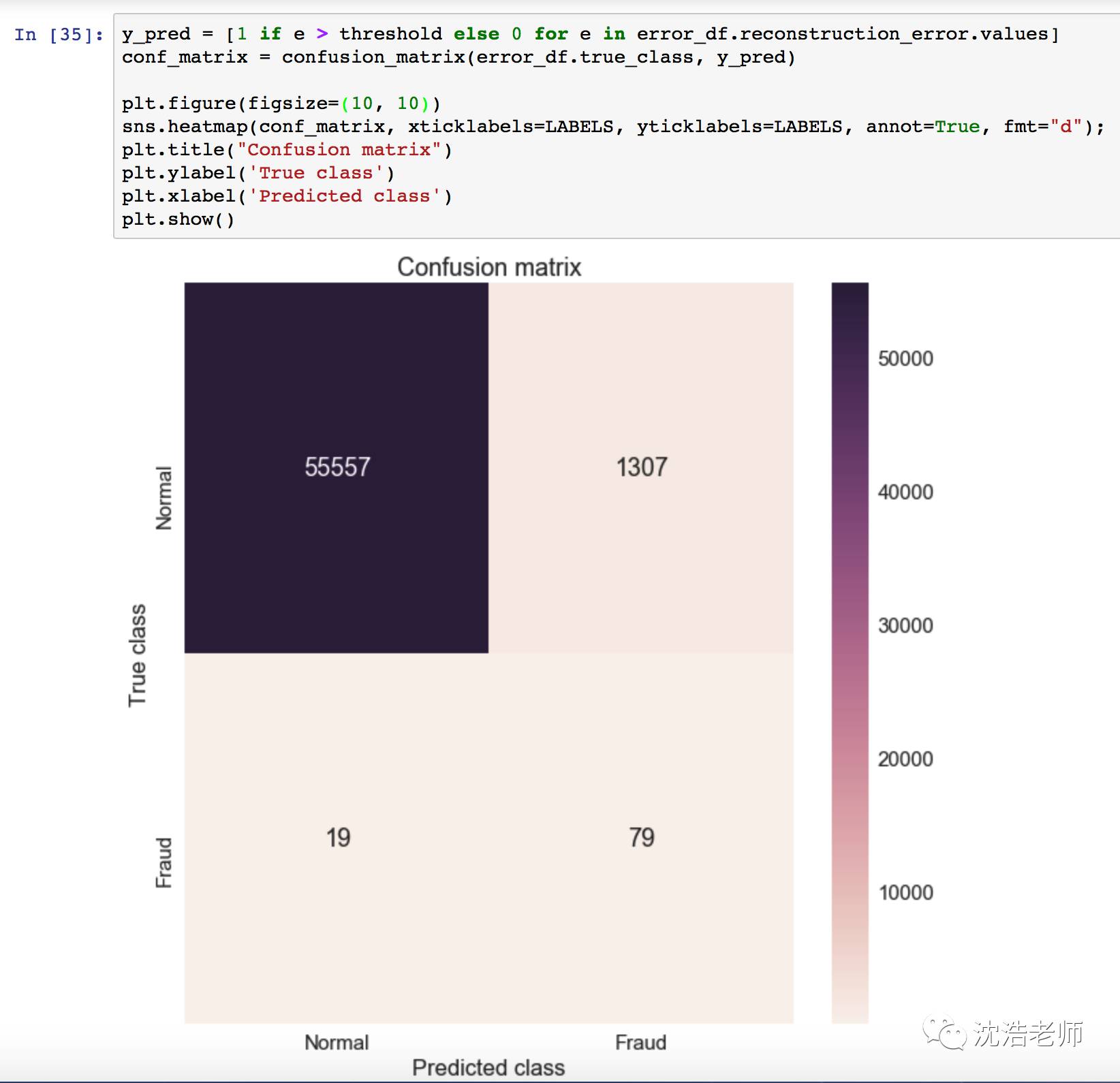
从错误分类矩阵可以看出,(55557+79)/ all = 97.67%。 这是一个非常不错的分类鉴别器。
参考文章来源:https://medium.com/@curiousily/credit-card-fraud-detection-using-autoencoders-in-keras-tensorflow-for-hackers-part-vii-20e0c85301bd
沈浩老师
大数据挖掘与社会计算实验室主任
中国市场研究行业协会会长




欢迎关注:灵动数艺
——数艺智训





