反欺诈中所用到的机器学习模型有哪些?

作者 | 微调(知乎ID微调,普华永道高级数据科学家)
反欺诈方向的实际应用很多,我有做过保险业反欺诈和零售快消业的欺诈检测,抛砖引玉的谈谈反欺诈项目的"道"和"术"。
具体的学习方法可以参考我最近的文章:
机器学习门下,有哪些在工业界应用较多,前景较好的小方向?(https://www.zhihu.com/question/57072166/answer/280824223)
该回答的第一部分(1)讨论了为什么欺诈检测难度很大;
第二部分(2-4)讨论了a. 数据可视化 b. 一些常用的算法及模型 c. 欺诈点验证;
第三部分(5)归纳并提出了一个反欺诈模型的通用框架供大家参考。
1. 背景 - 为什么反欺诈检测难度很高?
反欺诈项目很多情况下就是客户根本不知道什么是欺诈,什么不是。换句话说,对于什么是诈骗的定义很模糊。往小了说,反诈骗似乎是一个二分类问题(binary classification),但你仔细想想后会发现其实这是个多分类问题(multi-class classification),如果你把每种不同诈骗当做一种单独的类型。而单一类型的诈骗几乎是不存在的,且诈骗的手段日新月新总在变化。即使像银行还有保险公司这种常年和诈骗打交道的行业,也必须常常更新自己的检测手段,而不是把赌注压到同一个模型上。
除此之外,欺诈检测一般还面临以下问题:
九成九的情况数据是没有标签(label)的,各种成熟的监督学习(supervised learning)没有用武之地。
区分噪音(noise)和异常点(anomaly)时难度很大,甚至需要发挥一点点想象力和直觉。
紧接着上一点,当多种诈骗数据混合在一起,区分不同的诈骗类型更难。根本原因还是因为我们并不了解每一种诈骗定义。
...
退一步说,即使我们真的有诈骗的历史数据,即在有标签的情况下用监督学习,也存在很大的风险。用这样的历史数据学出的模型只能检测曾经出现过与历史诈骗相似的诈骗,而对于变种的诈骗和从未见过的诈骗,我们的模型将会无能为力。因此,在实际情况中,我不建议直接用任何监督学习,至少不能单纯依靠一个监督学习模型来奢求检测到所有的诈骗。
这就陷入了一个鸡生蛋蛋生鸡的死循环,因为没有历史标签和对诈骗的理解,我们无法做出能对诈骗细分的模型。因此我们一般使用无监督学习(unsupervised learning),且需要领域专家(domain experts)也就是对这个行业非常了解的人来验证我们的预测,提供反馈,以便于及时的调整模型。
2. 反欺诈项目的操作顺序(1) - 可视化
一般在拿到数据以后,我会推荐以下步骤进行分析。当然,一个答案很难包括所有常见的操作,仅仅是分享个人经验以供思考。
数据可视化 - 相关矩阵(Correlation Matrix) & 多维尺度变换(Multidimensional Scaling)
人是视觉动物,可以在第一时间“看到”数据中存在的问题。因此,对于大部分反欺诈问题,我建议至少要做以下两个可视化尝试:
2.1.首先对不同的特征(feature)做一个相关矩阵分析并可视化,分析相关矩阵的目的是告诉我们特征两两之间的关系,以便于我们快速发现一些数据里面可能存在的问题。最重要的是帮助我们检查数据是否存在问题,有没有什么违反常理的情况。
以我最近在写的文章为例(并不是反欺诈问题),对不同偶像团体是否能够继续走红进行预测。我们希望不同特征之间的两两关系符合尝试, 我在模型里面用了6个不同的特征并计算相关矩阵:

通过上表及下图,我们发现:
团员的平均的年龄和演唱会次数无关。
出道长度和和演唱会次数为负相关。
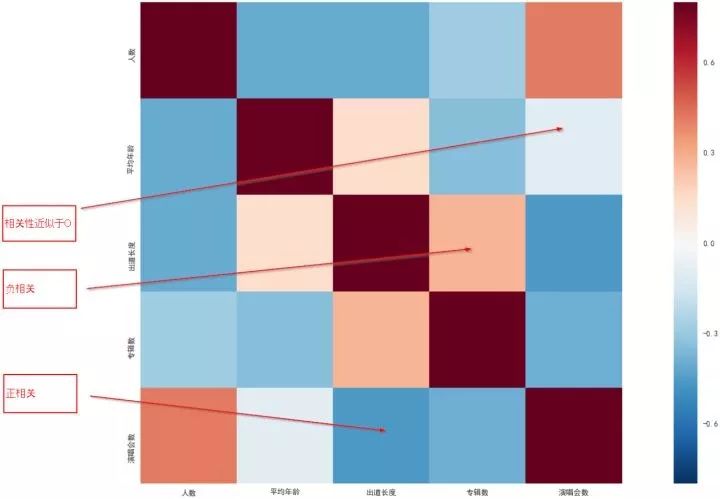
举例,如果我们发现出道年限和专辑数呈负相关,这就违反了常识。按照常识出道时间越长专辑数应该越多,因此需要认真检查为什么会有这样的情况发生,是否是潜在问题。
2.2. 多维尺度变换(MDS)来直接可视化数据分布
我们都知道一般来说欺诈和正常数据应该“长得不一样”,那是否可以直接把它们画出来来分析。
然而,数据可视化往往都是二维或者三维的,但现实往往是成百上千维。即使我们把一个特征作为一个维度,我们最多也只能可视化三个维度。而多维尺度变换(MDS)可以将高维的数据在二维或者三维的框架里面进行可视化,类似的数据点会更加接近。通过观察数据点的分布,我们可以直观的猜测数据是否有规律,是否存在潜在异常点。
以我最近做的一个项目为例,我们用MDS将一个8维的数据在2维上展示出来。我们似乎可以直观的看到一些近似线性的关系,以及一些看起来“很可疑”的点,我在图中标注了出来。
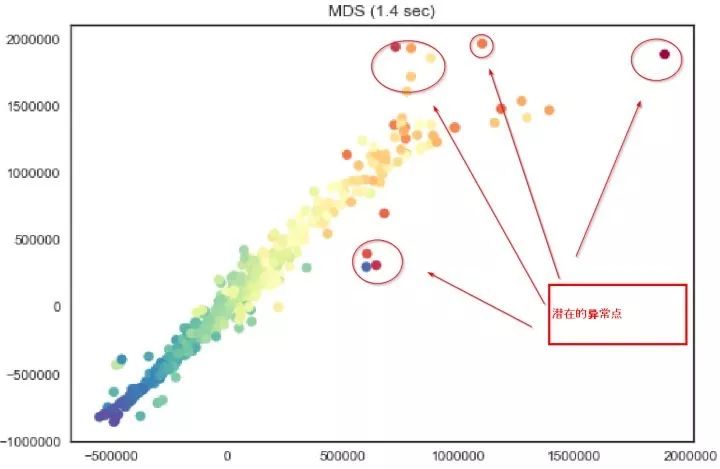
这样做的好处有两点:
首先我们可以看到数据是否存在特定的特征,如果所有的点都是随机散乱分布,那我们的麻烦就大了。
我们似乎可以看到有一些离群的数据点,这些点可能是潜在的“欺诈”,也有可能只是噪音而已。但我们可以向客户或者老板展示这个可视图,向他们证明项目有潜在的价值。
如果在可视化中我们看到了一些规律,这让有信心继续往下做,进入建模阶段。多加一句,此处和主成分分析(PCA)也有异曲同工之妙。
3. 反欺诈项目的操作顺序(2) - 算法
一般我们对欺诈检测做两种假设:
时序相关(time dependent)。对于时序相关的问题,我们假设欺诈的发生依赖于时间,通过时间序列分析,我们可以发现异常的地方。举例,假设一个人的信用卡平时1-11月每月消费2000美元,但12月突然消费了5000美元,此时时间就对我们的项目存在意义。
时序独立(time independent)。对于时序独立的问题,我们假设每一个欺诈都是独立,和时间无关。于是在分析中,我们移除了时间这个特征,我们不再把时间作为一个分析轴或者影响欺诈发生的特征。
3.1. 时间序列分析(time series analysis)
时间序列分析展开说是很大的话题,从简单的观察一个时间序列是否稳定(stability)到更复杂的看多个特征如何在时间上互相作用如 vector auto-regression(var)。
一般我们对时间序列重整使其稳定后,会进行一系列分析,最简单的就是观察什么时候出现反常的spike(即突然上升)。
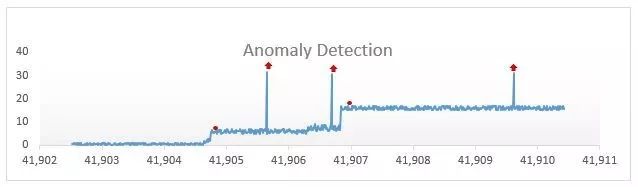
图片来源(Anomaly Detection – Using Machine Learning to Detect Abnormalities in Time Series Data-https://blogs.technet.microsoft.com/machinelearning/2014/11/05/anomaly-detection-using-machine-learning-to-detect-abnormalities-in-time-series-data/)
就像上图所标注出来着一系列点都是潜在的异常点。严格意义上说,时间序列分析在金融经济领域使用的更多,任何交易模型都需要时序分析。
另一种简单的时序分析就是持续追踪某个值的变化情况,并在多个数据中进行对比:
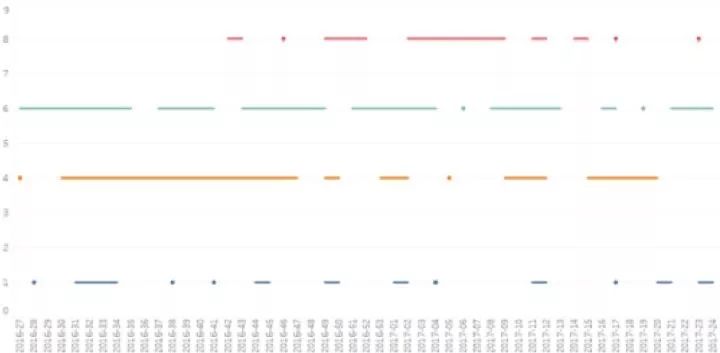
上图是某种产品在不同零售商(不同颜色)的退货情况,x轴是时间。我们会发现“橙色”的零售商的退货模式更不稳定(前期有大量持续退货),而“青色”的零售商退货非常稳定。因此,"橙色"零售商似乎有些可疑。当然,这只是一种解读方法,不代表一定有问题。
3.2. 时间独立下的建模
3.2.1. 无监督学习
如果我们假设时间对于欺诈并没有影响,那么我们有很多无监督学习可以用来检测异常值。
像某位答主提到的Isolation Forest就是一种非常稳定的算法,是周志华老师提出的。而且在Sklearn里面已经得到了实现。基本的原理就是一种集成学习,通过计算每个数据点需要多少次节点拆分(splitting)才能被划分到独立的空间。异常点因为和其他正常点离得较远不大相似,因此更容易用很少的拆分就可以被划到独立的空间里面去。
各种Density Based的聚类方法(CBLOF)。此处需要注意,大家熟知的K-Means为原型的聚类,如K-Modes都不大适合用于异常值检测,因为其本身很容易受到异常值和噪音的扰动。
各种以K近邻(KNN)为原型的检测方法。从本质上说,和聚类方法是比较类似的。
3.2.2. 统计学密度估计及分布测试
比较简单的做法可以尝试将数据拟合到假设的混合模型上(finite mixture models),再通过统计学测试检查异常点、 一般不大推荐直接这么做,因为需要对于正常数据分布的深刻了解,才能做出对于数据分布的正确推断。
3.2.3. 监督学习
就像上文提到的,我不太建议直接用监督学习。当然,在特定场合下如果需要使用的话,比较出名的就是MetaCost框架,可以结合各种基础学习器使用。
3.3. 时间相关及独立的交叉验证
其实很多问题不是非此即彼,换句话说,时间独立和时间独立可能找到相似的异常点。在项目允许的情况下,我们大可以将两种时间假设都做一遍,之后求交集。若出现在交集中,我们对于该点是诈骗的信心会进一步上升。
4. 反欺诈项目的操作顺序(3) - 如何验证欺诈点?
假设我们通过上面的无监督学习得到了一些“潜在的欺诈点”,我们可以做一些分析来验证它们是否真的是欺诈。首先我必须声明,这种归纳是存在很大偏见的,但很难避免。
举例,我们可以对比异常值数据作为样本(sample)与总体(population)的各项数据的统计值(如均值方差等),从统计学上证明它们是有显著差异的。但有显著差异并不代表他们一定是欺诈,只能说明它们不同。
当我们从统计学上证明其存在显著差异后,我们就开始想要归纳潜在的欺诈原因。以某供货商的数据为例,我们发现一个产品的进货变多、退货变少,但单位收益却上升,这是有问题的。
于是我们就可以大胆的推测他的进货和退货不是同一种产品,即在退货时用了比较便宜商品但拿到了更多的退货钱。
把这个故事讲给领域专家以后,他们会支持、质疑、甚至反对这个看法。根据领域专家的反馈,我们可以不断的调整优化模型,期待发现更多的问题。有的时候,也可以直接叫领域专家来帮忙分析为什么一些数据可能是欺诈。
5. 总结 - 如何构建可行的欺诈检测方案?
首先,我们必须先要认清一个残酷的现实:单纯依靠机器学习模型来检测欺诈是愚蠢的。至少在现阶段我们不能单纯依靠纯粹的数据模型来做这一点。比较折中且可行的方法是做 混合模型(hybrid model),也就是把人为规则和机器学习模型合二为一,一起来使用。
首先我们通过对领域专家的访谈和对历史数据的分析,可以得到一些非常可靠的评判标准。以保险行业为例,如果一个人刚买短期保险没两天就意外身亡,这存在欺诈的风险就很高。这样的标准或许从机器学习中可以学到,或许学不到。如果有成本更低方法做到更好的效果,不要迷信全自动模型。
总结来说,反欺诈模型难度很高,而且需要和领域专家一起协作才能有最好的结果。机器学习从业者千万不要闭门造车,试图自己靠调参就搞个大新闻。
我个人推荐的步骤是:
对数据进行必要的可视化,如MDS
同时考虑时间是否是重要因素,如果是那么进行时序分析
用无监督学习得到一些可能的异常点,如Isolation Forests
通过统计学方法分析得到的异常点是否有显著的不同,有特征可供我们研究
归纳特征并构造一个故事,与领域专家共同验证故事的可靠性
重复1-5直到被派到下一个项目上搬砖,争取找到尽量多有效的欺诈
构造[规则+机器学习]的混合模型,进一步调参优化模型
鉴于篇幅,很多有趣的做法都没法详谈,比如时间序列上的聚类和半监督异常检测,有兴趣的朋友可以继续深入挖掘。
作者简介:微调(现知乎ID「微调」, 曾用ID「阿萨姆」,微博@阿萨姆谈AI ),普华永道高级数据科学家。
知乎主页:https://www.zhihu.com/people/breaknever/posts
2018年3月30-31日,第二届中国区块链技术暨应用大会将于北京喜来登长城饭店盛大开场,50+区块链技术领导人物,100+区块链投资商业大咖,100+技术&财经媒体,1000+区块链技术爱好者,强强联合,共同探讨最in区块链技术,豪华干货礼包享不停。八折门票火热抢购中!2018,未来已来,带你玩转区块链。

AI科技大本营用户群(计算机视觉、机器学习、深度学习、NLP、Python、AI硬件、AI+金融方向)正在招募中,后台回复:读者群,联系营长,添加营长请备注姓名,研究方向。



