私人定制——使用深度学习Keras和TensorFlow打造一款音乐推荐系统
随着生活水平的极大提高,人们在很多情况下都会边听音乐边做一些事情,比如在健身房、出行路上等,越来越多的人也开始慢慢走在Hifi发烧友的这一条不归路上,频繁地换耳机、换功放等,小编在这里劝一下大家不要向某米公司的为发烧而生,要学习某米公司的高性价比,发烧永无止境,适可而止就好。
那大家有没有关注一些音乐APP呢,国内做的好的音乐APP有网易云、虾米音乐及QQ音乐等,我们会发现这些APP中都会有两个类似的功能——我喜欢的音乐及每日歌曲推荐,其中我喜欢的音乐这个功能会记录你喜欢的音乐,而每日歌曲推荐是根据你喜欢的音乐风格来推荐给你一些你未曾听过的音乐,看起来是不是很黑科技呢?其实这种技术早就存在,被称作推荐算法,在生活中随处可见。
根据百度百科的定义:推荐算法是计算机专业中的一种算法,通过一些数学算法,推测出用户可能喜欢的东西,目前应用推荐算法比较好的地方主要是网络中。所谓推荐算法就是利用用户的一些行为,通过一些数学算法,推测出用户可能喜欢的东西。比如淘宝购物、页面定位广告等。
随着大数据时代的到来,我们的个人数据会被巨头公司以各种方式获取,获取的数据越多,对我们的分析也就越清楚,推荐得也更加准确,有时候甚至算法做出的推荐选择比我们自己都更加清楚自己内心想法,这点在婚恋交友网站上可能会有大的突破,分析彼此的性格,比如说分析两个男人的条件,最后推荐最适合你的对象。未来的世界里,数据就是上帝,你我都避免不了自己的数据被人收集,只能说利用好巨头公司提供的各种服务吧。
言归正传,本文将利用深度学习向读者展示一个音乐推荐系统的搭建,感兴趣的读者可以动手尝试下。国外的音乐获取没有国内这么便利及免费,这也说明国外的月亮一定比国内圆,国内的有些服务确实比国外做的方便。本文作者(后续将以“我”代替)最近几年已经在junodownload网站花了很多钱,主要是购买购买mp3音乐,该网站是一个主要用于DJ数字下载网站,并且是一个巨大的销售与跟踪平台。

从图上看该网站是一个丰富的音乐资源分享网站,他们为每一首出售的歌曲提供慷慨的2分钟试听MP3文件(国内还是良心)。唯一遇到的问题是当在该网站上寻找一个不是最新的或目前不在销售排行榜的音乐真的很难。
该网站主要侧重于推广新的内容,并认为新的音乐会产生最多的收益,但对于网站上的99%其他销售能全部跟踪吗?
音乐推荐

该网站目前已经有了一些跟踪建议。在主页上还有销售列表、新发布的歌单和由人员及DJ策划的大量的推荐列表。
最重要的是,在每个单独的跟踪/单网页,窗口的右侧会“引荐买了这首歌曲的也会买那首歌(类似于亚马逊网站卖电子书籍)”、“艺术家的其他版本”和“其他版本的家唱片公司”,这些也是有用的。
但对于这样一个大型的音乐数据库,我觉得还是缺少根据用户目前正在听一的歌曲推荐一些可能也会喜欢歌曲的、建议一些类似的歌曲类型,这也会增加到购物车中的机会等。
如果你能发现音乐是几年前发布的,并且类似于你喜欢的一个新的歌曲,会不会很酷?当然,Juno网站错过了不提供这种类型的推荐带来的潜在销售的。
受到最近阅读的一篇博客的启发,对自己的音乐库中的歌曲进行音乐流派的分类,我决定尝试用类似的方法来建立一个音乐推荐系统。
实现过程
实现这一目标需要采集大量数据、处理和模型训练等步骤。下面是所有涉及的步骤:
下载MP3文件
首先要做的第一件事就是下载大量样本的MP3文件。
该网站上有超过400000的音乐文件可供销售,随意挑选了9种不同的音乐流派,然后从每种流派中都随机选择1000首。
9种流派:
碎拍
舞厅
慢摇
鼓与贝斯
经典电音
嘻哈/ RB
微声舞曲
摇滚/独立音乐
迷幻舞曲
在接下来的几天日子里,我下载了这些流派总共9000个MP3文件。
转换音频频谱图
一个音频文件包含的数据太多,所以在这部分的整个过程中的很大一部分本质上是试图将信息从音乐中浓缩、提取主要特征并消除所有的“噪音”。它本质上是一个降维的预处理,这第一阶段是将音频转换成图像格式。
利用离散傅里叶变换将音频信号转换到频域上,处理收集的9000个MP3音频文件,每首歌保存为光谱图像。光谱图是一种表示声音的频谱随时间变化的可视化,图片上颜色的强度代表该频率的声音振幅。
本文选择创建成单色光谱图,如下图所示:

上图是20秒左右的嘻哈音乐产生的声音。X轴表示时间,Y轴表示声音的频率。
分割图像为256×256
为了对这些数据训练一个模型,需要将所有的图像统一为相同的尺寸,所以将所有的光谱图分割为256×256大小。

切割完图片后,总共得到185000多张图片,每一张图像都标记与它所代表的音乐流派的标签。
下面将数据集分为训练集120000张、验证集45000张和测试集20000张。
训练一个卷积神经网络
利用上部分中的图像数据训练一个卷积神经网络,该网络要学习不同类型的音乐对应的频谱图像,所以使用类型标签并训练该网络能从图像中识别出音乐的类型。
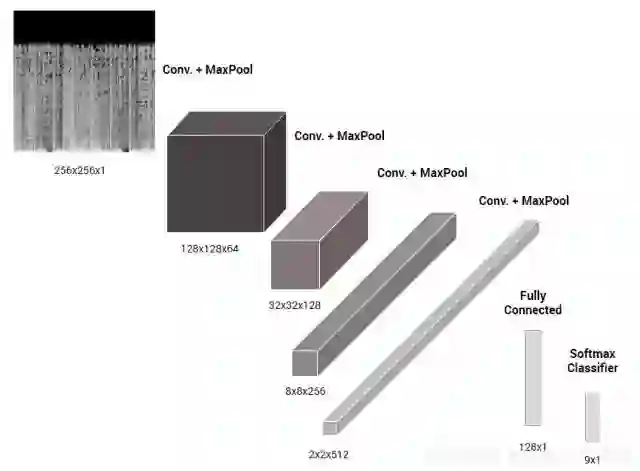
上图是本文搭建的卷积神经网络模型,可以看到,左上边的光谱图像将图像转换成一个表示每个像素的颜色的数字矩阵;之后数据经过卷积层、池化层以及全连接层等处理后送入到右下角的softmax分类器,分类器给出一个9位数的矢量,其中每位分别对应着9种音乐流派的概率,最后选择其中最大概率位置的流派为最终识别流派。
卷积神经网络的表现如何呢?
本文搭建的卷积神经网络模型能够以75%的精度分类出歌曲的音乐流派,我个人认为结果还是比较好(后续可以调参及调整网络模型提高识别精度),这是音乐是主观的,一首歌曲常常会有一个及以上的类型。
下面是每种类型歌曲的分类精度的详细情况:
迷幻舞曲:91%
鼓与贝斯:90%
舞厅:79%
碎拍:78%
经典电音:71 %
慢摇:71 %
摇滚/独立音乐:70%
微声舞曲:63%
嘻哈/ RB:61 %
从结果中可以看到在分类迷幻电音时候表现优异,而分类嘻哈/ RB音乐时效果不是很好,可能的原因是数据集之间有一些交叉可能导致分类精度较低,比如嘻哈、碎拍和舞厅比较类似。而迷幻电音完全不同于其他8个类型的音乐,这可能是其表现优异的原因吧。
关于音乐推荐系统
现在有了训练好的神经网络,该网络能够“看清”音乐的频谱图,因此我们不再需要softmax分类器,所以移除模型中的全连接层。
每个图像代表超过5秒的音频信息,而每个MP3文件大约有2分钟时长,因此每个音乐文件大约对应着23张图像,即获得23个特征向量;然后计算这23个特征向量的均值向量,总共得到9000的特征向量;每个特征向量对应着之前下载的9000首歌曲。
回顾整个过程–开始收集9000个音频文件,并将其转化为9000个频谱图,然后将频谱图分成185000个更小的频谱图,并利用这些图像训练搭建的卷积神经网络。最后从所有这些图像中提取185000个特征向量并计算其均值得到9000个对应原始音频文件的平均向量。
基于已经从音乐文件中提取的128个特征,这些特征能够确定音乐所属的类型。为了创建有着类似特征的推荐歌曲,所以需要找到最相似的向量。为此,计算出9000个向量之间的余弦相似性。
推荐例子
最后一步是随意选择一首歌,然后训练好的模型从9000首歌曲集中推荐一首与之最类似的音乐(最大的余弦相似性)。
下图是推荐的几个例子,播放的第一首歌是随机选择的,第3个例子获得了最类似的推荐。由于网络受限,播放需要通过外网,图片下面对应着播放链接。
(https://youtu.be/H1cN4uzxZZw)
(https://youtu.be/cPHpr_u62ZM)

(https://youtu.be/cizXW9vvoRA)
(https://youtu.be/VDuOu4BMDz8)
(https://youtu.be/7M5_TKOOGBg)
(https://youtu.be/PnK8pX8f9A4)
整个过程完全是无监督的,这点是很厉害的。想象一下,如果听完这9000首歌后并评估这些歌曲的不同的特征和类别需要花多少时间。类似的工作也在潘多拉进行,已经开始尝试这种“音乐基因工程”。根据这篇文章,25个音乐分析师听完并对10000首歌进行分类所花的时间是一个月,而本文的整个项目从开始到完成仅花费三个星期,并提取了多达450个不同的音乐特征。该模型的表现与人类的表现类似,并且在查找歌曲时不需要任何人预先听段音频,此外花费极少的时间。
总的来说,本系统上手不太复杂,收集音乐并对音乐文件进行预处理需要花费一些时间,感兴趣的读者可以按照这个思路动手实现一些其他类似的推荐系统,也可以制作成一款APP哦,相比国内的音乐APP而言,国外的是不是弱爆了?赶紧开发一款在海外市场发行吧。
相关代码
https://github.com/mattmurray/juno_crawler
https://github.com/mattmurray/music_recommender
作者信息
Matthew Murray:数据科学家和分析师
个人主页:http://mattmurray.net/
Linkedin:https://www.linkedin.com/in/mattsrm/
Github: https://github.com/mattmurray
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织翻译。
文章原标题《Building a Music Recommender with Deep Learning》,作者:Matthew Murray,译者:海棠,审阅:李烽
往期精彩文章
-END-

云栖社区
ID:yunqiinsight
云计算丨互联网架构丨大数据丨机器学习丨运维

点击“阅读原文”





