教程 | 初学者如何学习机器学习中的L1和L2正则化
选自Medium
作者:Prashant Gupta
机器之心编译
参与:陈韵竹、刘晓坤
训练机器学习模型的要点之一是避免过拟合。如果发生过拟合,模型的精确度会下降。这是由于模型过度尝试捕获训练数据集的噪声。本文介绍了两种常用的正则化方法,通过可视化解释帮助你理解正则化的作用和两种方法的区别。
噪声,是指那些不能代表数据真实特性的数据点,它们的生成是随机的。学习和捕捉这些数据点让你的模型复杂度增大,有过拟合的风险。
避免过拟合的方式之一是使用交叉验证(cross validation),这有利于估计测试集中的错误,同时有利于确定对模型最有效的参数。本文将重点介绍一种方法,它有助于避免过拟合并提高模型的可解释性。
正则化
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束、调整或缩小。也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险。
一个简单的线性回归关系如下式。其中 Y 代表学习关系,β 代表对不同变量或预测因子 X 的系数估计。
Y ≈ β0 + β1X1 + β2X2 + …+ βpXp
拟合过程涉及损失函数,称为残差平方和(RSS)。系数选择要使得它们能最小化损失函数。
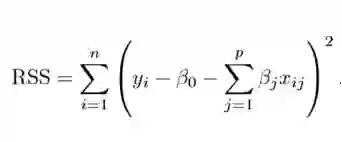
这个式子可以根据你的训练数据调整系数。但如果训练数据中存在噪声,则估计的系数就不能很好地泛化到未来数据中。这正是正则化要解决的问题,它能将学习后的参数估计朝零缩小调整。
岭回归
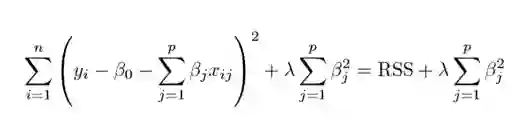
上图展示了岭回归(Ridge Regression)。这一方法通过添加收缩量调整残差平方和。现在,系数要朝最小化上述函数的方向进行调整和估计。其中,λ 是调整因子,它决定了我们要如何对模型的复杂度进行「惩罚」。模型复杂度是由系数的增大来表现的。我们如果想最小化上述函数,这些系数就应该变小。这也就是岭回归避免系数过大的方法。同时,注意我们缩小了每个变量和响应之间的估计关联,除了截距 β0 之外——这是因为,截距是当 xi1 = xi2 = …= xip = 0 时对平均值的度量。
当 λ=0 时,惩罚项没有作用,岭回归所产生的参数估计将与最小二乘法相同。但是当 λ→∞ 时,惩罚项的收缩作用就增大了,导致岭回归下的系数估计会接近于零。可以看出,选择一个恰当的 λ 值至关重要。为此,交叉验证派上用场了。由这种方法产生的系数估计也被称为 L2 范数(L2 norm)。
标准的最小二乘法产生的系数是随尺度等变的(scale equivariant)。即,如果我们将每个输入乘以 c,那么相应的系数需要乘以因子 1/c。因此,无论预测因子如何缩放,预测因子和系数的乘积(X{β})保持不变。但是,岭回归当中却不是如此。因此,我们需要在使用岭回归之前,对预测因子进行标准化,即将预测因子转换到相同的尺度。用到的公式如下:
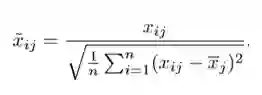
Lasso 回归
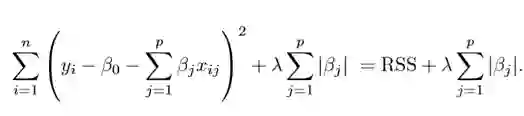
Lasso 是另一个变体,其中需要最小化上述函数。很明显,这种变体只有在惩罚高系数时才有别于岭回归。它使用 |β_j|(模数)代替 β 的平方作为惩罚项。在统计学中,这被称为 L1 范数。
让我们换个角度看看上述方法。岭回归可以被认为是求解一个方程,其中系数的平方和小于等于 s。而 Lasso 可以看作系数的模数之和小于等于 s 的方程。其中,s 是一个随收缩因子 λ 变化的常数。这些方程也被称为约束函数。
假定在给定的问题中有 2 个参数。那么根据上述公式,岭回归的表达式为 β1² + β2² ≤ s。这意味着,在由 β1² + β2² ≤ s 给出的圆的所有点当中,岭回归系数有着最小的 RSS(损失函数)。
同样地,对 Lasso 而言,方程变为 |β1|+|β2|≤ s。这意味着在由 |β1|+|β2|≤ s 给出的菱形当中,Lasso 系数有着最小的 RSS(损失函数)。
下图描述了这些方程。
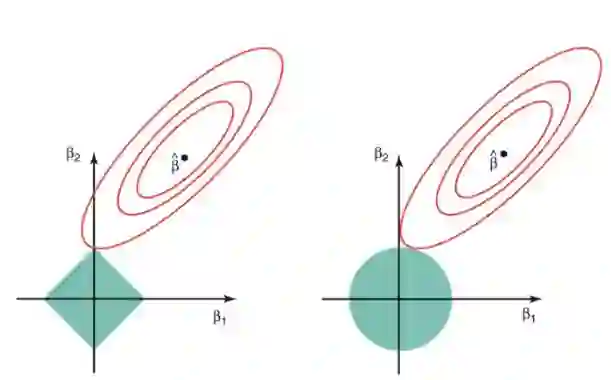
上图的绿色区域代表约束函数域:左侧代表 Lasso,右侧代表岭回归。其中红色椭圆是 RSS 的等值线,即椭圆上的点有着相同的 RSS 值。对于一个非常大的 s 值,绿色区域将会包含椭圆的中心,使得两种回归方法的系数估计等于最小二乘估计。但是,上图的结果并不是这样。在上图中,Lasso 和岭回归系数估计是由椭圆和约束函数域的第一个交点给出的。因为岭回归的约束函数域没有尖角,所以这个交点一般不会产生在一个坐标轴上,也就是说岭回归的系数估计全都是非零的。然而,Lasso 约束函数域在每个轴上都有尖角,因此椭圆经常和约束函数域相交。发生这种情况时,其中一个系数就会等于 0。在高维度时(参数远大于 2),许多系数估计值可能同时为 0。
这说明了岭回归的一个明显缺点:模型的可解释性。它将把不重要的预测因子的系数缩小到趋近于 0,但永不达到 0。也就是说,最终的模型会包含所有的预测因子。但是,在 Lasso 中,如果将调整因子 λ 调整得足够大,L1 范数惩罚可以迫使一些系数估计值完全等于 0。因此,Lasso 可以进行变量选择,产生稀疏模型。
正则化有何效果?
标准的最小二乘模型常常产生方差。即对于与训练集不同的数据集,模型可能不能很好地泛化。正则化能在不显著增大偏差的的同时,显著减小模型的方差。因此,正则化技术中使用的调整因子 λ,能控制对方差和偏差的影响。当 λ 的值开始上升时,它减小了系数的值,从而降低了方差。直到上升到某个值之前,λ 的增大很有利,因为它只是减少方差(避免过拟合),而不会丢失数据的任何重要特性。但是在某个特定值之后,模型就会失去重要的性质,导致偏差上升产生欠拟合。因此,要仔细选择 λ 的值。
这就是你开始使用正则化之前所要掌握的全部基础,正则化技术能够帮助你提高回归模型的准确性。实现这些算法的一个很流行的库是 Scikit-Learn,它可以仅仅用 Python 中的几行代码运行你的模型。

原文地址:https://towardsdatascience.com/regularization-in-machine-learning-76441ddcf99a
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



