学会这10种机器学习算法,你才算入门(附教程)
作为数据科学家的实践者,我们必须了解一些通用机器学习的基础知识算法,这将帮助我们解决所遇到的新领域问题。本文对通用机器学习算法进行了简要的阐述,并列举了它们的相关资源,从而帮助你能够快速掌握其中的奥妙。
▌1.主成分分析(PCA)/ SVD
PCA是一种无监督的方法,用于对由向量组成的数据集的全局属性进行理解。本文分析了数据点的协方差矩阵,以了解哪些维度(大部分情况)/数据点(少数情况)更为重要,即它们之间具有很多的变化,但与其他变量之间的协变性较低)。考虑一个矩阵顶级主成分(PC)的一种方式是考虑它的具有最高特征值的特征向量。奇异值分解(SVD)本质上也是计算有序组件的一种方法,但你在没有获得点的协方差矩阵的情况下也可以得到它。
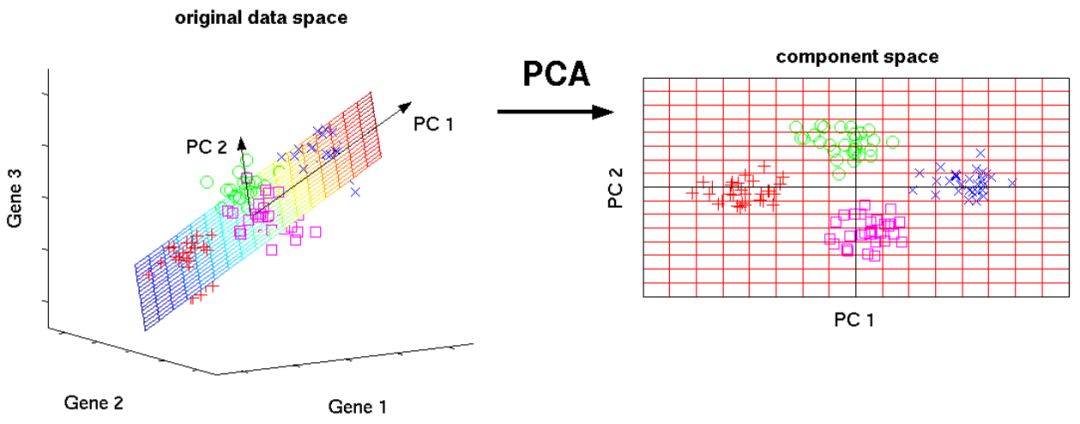
该算法通过获取维度缩小的数据点的方式来帮助人们克服维度难题。
库:https://docs.scipy.org/doc/scipy/reference/generated/scipy.linalg.svd.html
教程:https://arxiv.org/pdf/1404.1100.pdf
▌2a.最小二乘法和多项式拟合
还记得你在大学时所学的数值分析(Numerical Analysis)代码吗?其中,你使用直线和曲线连接点从而得到一个等式方程。在机器学习中,你可以将它们用于拟合具有低维度的小型数据集的曲线。(而对于具有多个维度的大型数据或数据集来说,实验的结果可能总是过度拟合,所以不必麻烦)。OLS有一个封闭形式的解决方案,所以你不需要使用复杂的优化技术。
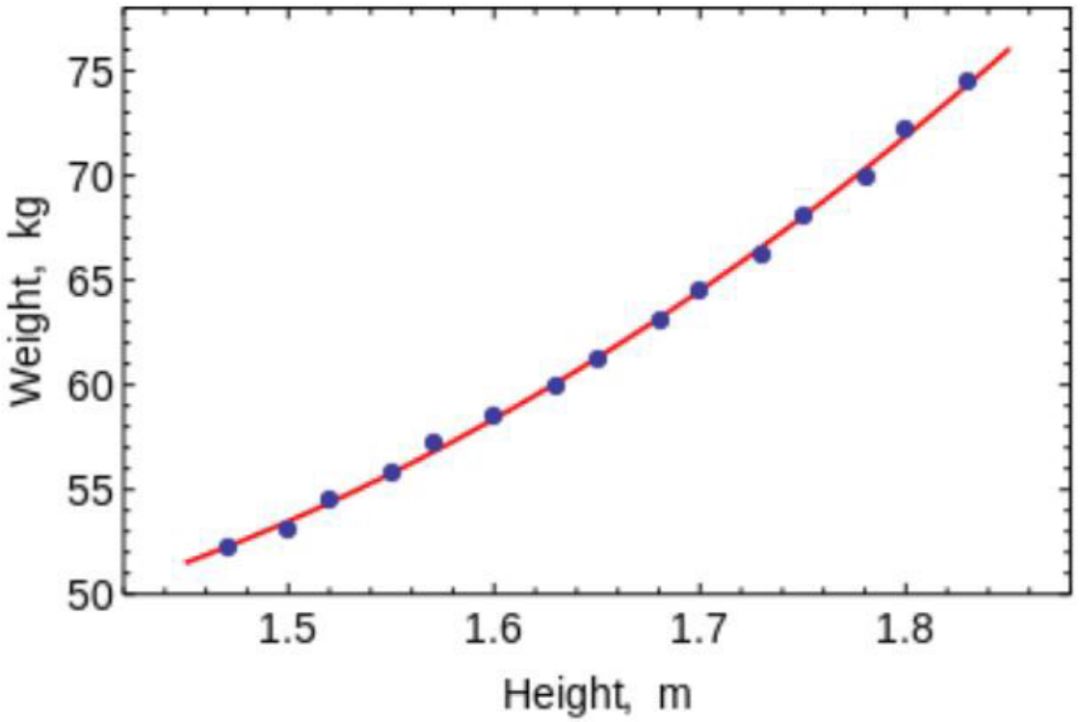
如上图所示,很明显,使用这种算法对简单的曲线/回归进行拟合是非常方便的。
库:https://docs.scipy.org/doc/numpy/reference/generated/numpy.linalg.lstsq.html
教程:
https://lagunita.stanford.edu/c4x/HumanitiesScience/StatLearning/asset/linear_regression.pdf
https://www.julyedu.com/question/big/kp_id/23/ques_id/1012
▌2b.约束线性回归
最小二乘法可能会与异常值(outliers)、假字段(spurious fields)和数据中的噪声相混淆。因此,我们需要约束以减少数据集上所进行拟合的线的方差。正确的方法是使用一个线性回归模型,以确保权重不会出错。模型可以有L1范数(LASSO)或L2(岭回归,Ridge Regression)或兼具两者(弹性回归)。均方损失得到优化。

将这些算法用于拟合带有约束的回归线,避免过度拟合并对模型中噪声维度进行掩码。
库:http://scikit-learn.org/stable/modules/linear_model.html
▌3. K均值聚类
这是大家最喜欢的无监督聚类算法。给定一组向量形式的数据点,我们可以根据它们之间的距离制作点集群。这是一个期望最大化算法,它迭代地移动集群中心,然后架构每集群中心点聚焦在一起。该算法所采用的输入是将要生成的集群的数量,以及它将尝试聚集集群的迭代次数。
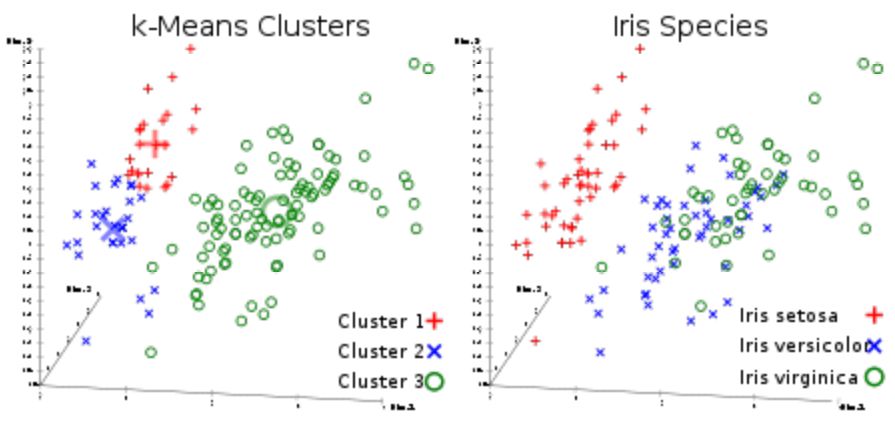
顾名思义,你可以使用此算法在数据集中创建K个集群。
库:http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
教程:http://www.julyedu.com/video/play/18/72
▌4.Logistic回归
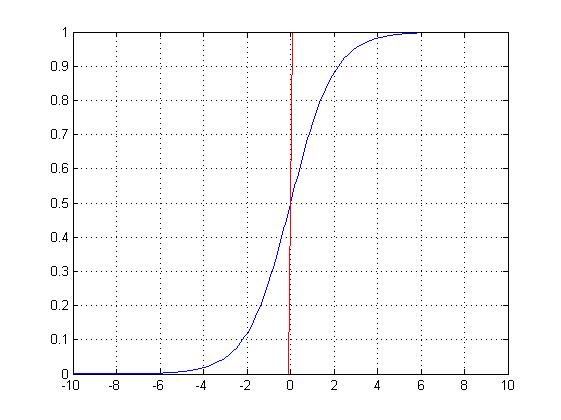
Logistic回归是有限线性回归,在应用权重后带有非线性(大多数使用sigmoid函数,或者你也可以使用tanh函数)应用,因此把输出限制到接近+/-类(在sigmoid的情况下是1和0)。利用梯度下降法对交叉熵损失函数(Cross-Entropy Loss functions)进行优化。
初学者需要注意的是:Logistic回归用于分类,而不是回归。你也可以把logistic回归看成是一层神经网络。Logistic回归使用诸如梯度下降或LBFGS等最优化方法进行训练。从事自然语言处理的的人员通常会称它为最大熵分类器(Maximum Entropy Classifier)。
Sigmoid函数是这个样子的:
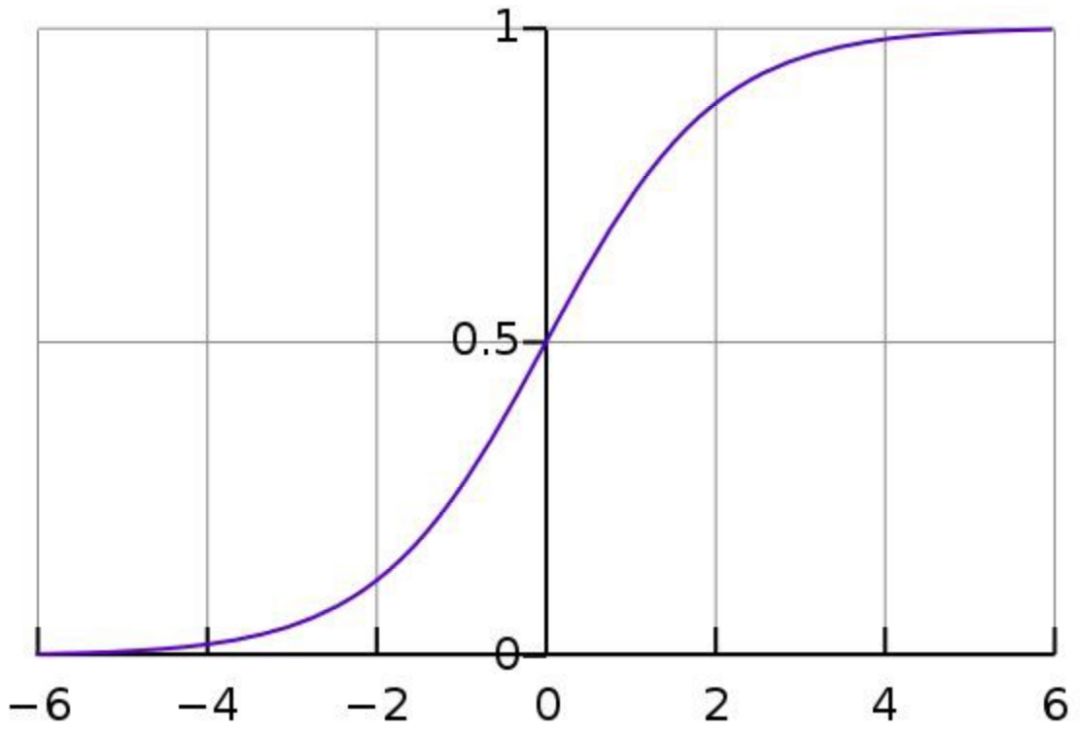
使用LR对简单但具有鲁棒性的分类器进行训练。
库:http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
教程:https://www.julyedu.com/question/big/kp_id/23/ques_id/1001
▌5.支持向量机 (Support Vector Machines,SVM )
支持向量机是线性模型,就像线性/ Logistic回归一样,不同之处在于它们有不同的基于边缘的损失函数(支持向量机的推导是我见过的最漂亮的数学结果和特征值计算之一)。你可以使用诸如L-BFGS甚至SGD这样的最优化方法来优化损失函数。

支持向量机中的另一个创新是将内核用于数据,以体现工程师的特色。如果你有很好的领域洞察力,你可以用更聪明的方法来替代优秀但是老旧的RBF内核并从中获利。
支持向量机能做一件独特的事情:学习一类分类器。
可以使用支持向量机来训练分类器(甚至是回归量)。
库:http://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html
教程:http://www.julyedu.com/video/play/18/429
https://www.julyedu.com/question/big/kp_id/23
▌6.前馈神经网络(Feedforward Neural Networks, FFNN)
这些基本上都是多层的logistic回归分类器。许多权重的层被非线性函数(sigmoid、tanh、relu+softmax和炫酷的selu)分隔了。它们另一个流行的名字是多层感知器(Multi-Layered Perceptron)。可以将FFNN作为自动编码器用于分类和非监督的特征学习。
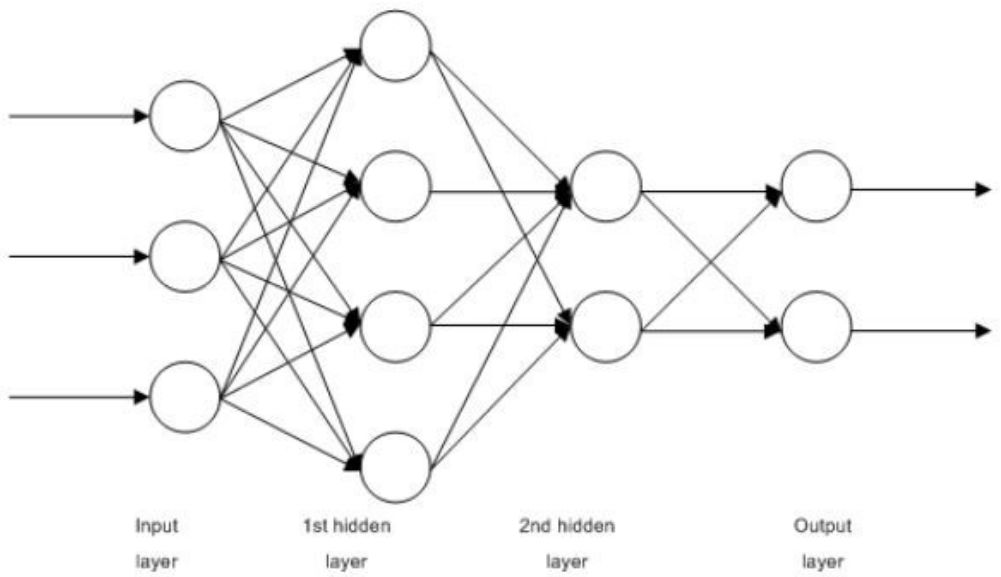
多层感知器(Multi-Layered perceptron)
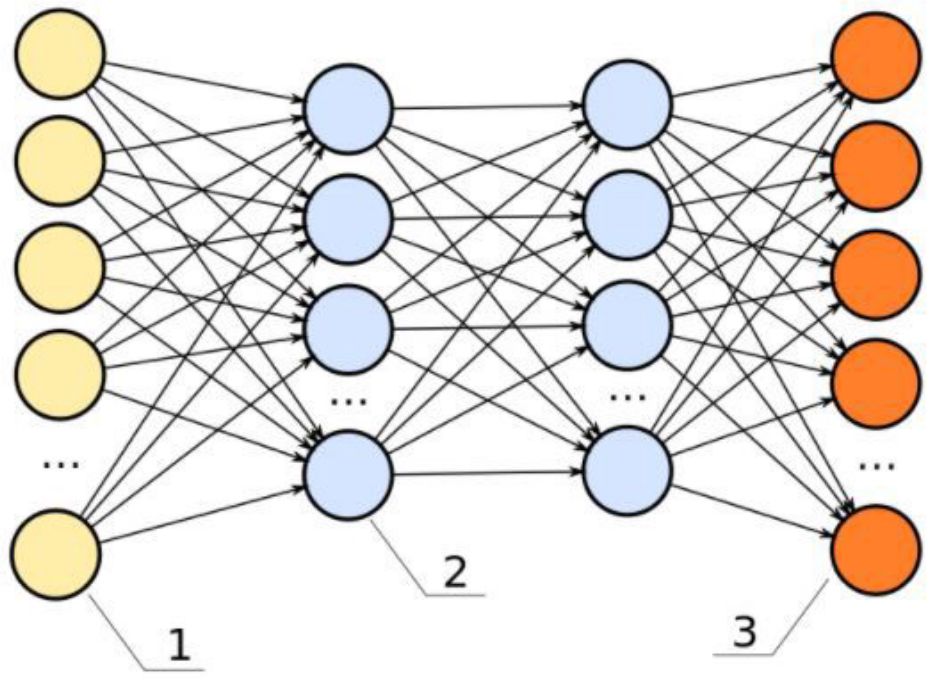
FFNN作为自动编码器
可以使用FFNN作为自动编码器来训练分类器或提取特征。
库:http://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html#sklearn.neural_network.MLPClassifier
教程:http://www.deeplearningbook.org/contents/mlp.html
http://www.deeplearningbook.org/contents/autoencoders.html
http://www.deeplearningbook.org/contents/representation.html
▌7.卷积神经网络(Convents)
目前,世界上近乎所有基于视觉的机器学习结果都是使用卷积神经网络实现的。它们可用于图像分类、目标检测及图像分割。Yann Lecun于80年代末90年代初提出卷积神经网络,其特征是卷积层,它起着提取分层特征的作用。你可以在文本(甚至图形)中使用它们。
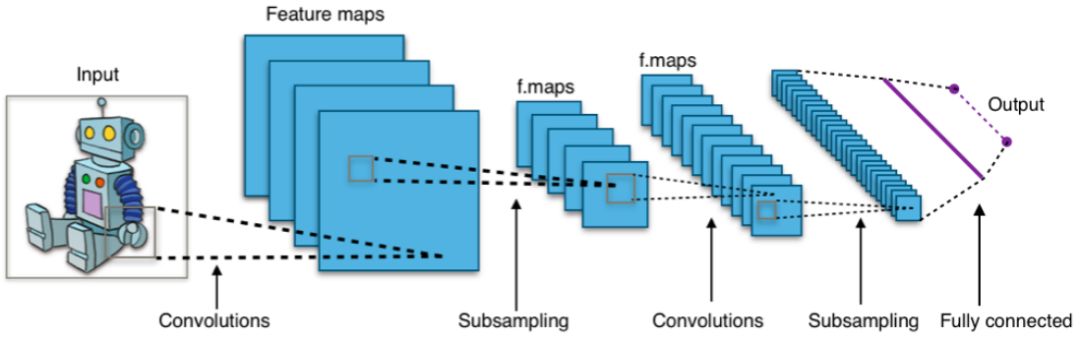
利用卷积神经网络对图像和文本进行分类,并进行目标检测和图像分割。
库:https://developer.nvidia.com/digits
https://keras.io/applications/
教程:http://www.julyedu.com/video/play/18/134
▌8.循环神经网络(RNNs)
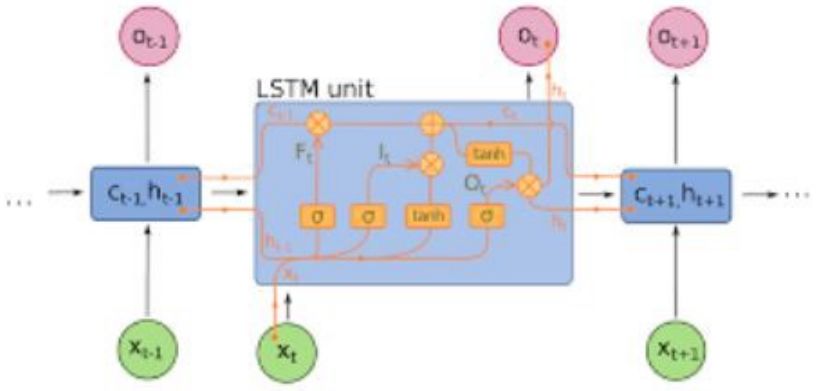
RNNs模型序列通过在时间t递归地对聚集器状态施加相同的权重集,并且在时间t输入(给定一个序列,在时间0..t..T处有输入,并且在每个时间t具有隐藏状态,来自RNN的t-1步骤的输出)。现在很少使用纯RNN(pure RNN),但是像LSTM和GRU这类旗鼓相当的算法在大多数序列建模任务中仍是最先进的。
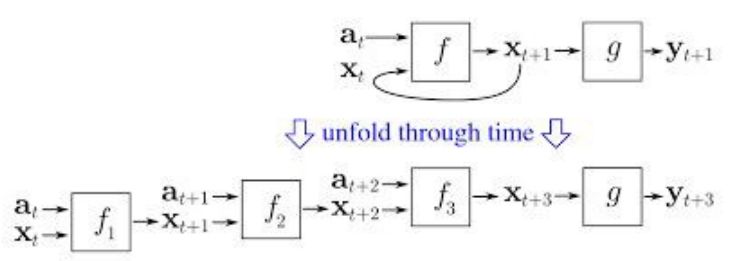
RNN(如果这里是密集连接的单元与非线性,那么现在f一般是LSTM或GRU)。LSTM单元用于替代纯RNN中的简单致密层。
使用RNN进行人物序列建模任务,特别是文本分类、机器翻译及语言建模。
库:http://opennmt.net/
教程:http://cs224d.stanford.edu/
http://www.wildml.com/category/neural-networks/recurrent-neural-networks/
https://www.julyedu.com/question/big/kp_id/26/ques_id/1716
▌9.条件随机场(CRFs)
CRFs或许是概率图形模型(PGMs)中使用频率最高的模型。它们可用于类似于RNN的序列建模,也可与RNN结合使用。在神经机器翻译系统出现之前,CRF是最先进的技术,在许多具有小数据集的序列标注任务中,它们仍然会比那些需要大量数据才能推广的RNN表现得更好。它们也可被用于其他结构化的预测任务,如图像分割等。CRF对序列中的每个元素(例如句子)进行建模,这样近邻会影响序列中某个组件的标签,而不是所有的标签相互独立。
使用CRFs标记序列(如文本、图像、时间序列及DNA等)。
库:https://sklearn-crfsuite.readthedocs.io/en/latest/
▌10.决策树
例如我有一张有关各种水果数据的Excel工作表,我必须标明哪些是苹果。我们需要做的是提出一个问题“哪些水果是红的,哪些水果是圆的?”然后根据答案,将“是”与“否”的水果区分开。然后,我们得到的红色和圆形的水果并不一定都是苹果,所有苹果也不一定都是红色和圆形的。因此,我会面向红色和圆形的水果提出一个问题,“哪些水果上有红色或黄色的标记” ?向不是红色和圆形的水果提出一个问题,“哪些水果是绿色和圆形的”。基于这些问题,我可以非常准确的分辨出哪些是苹果。这一系列的问题展示了什么是决策树。然而,这是基于我个人直觉的决策树。直觉并不能处理高维度和复杂的问题。我们必须通过查看标记的数据来自动得出问题的级联,这就是基于机器学习的决策树所做的工作。早期的CART树曾被用于简单的数据,但随着数据集的不断扩大,偏差-方差的权衡需要用更好地算法来解决。目前常用的两种决策树算法是随机森林(Random Forests)(在属性的随机子集上建立不同的分类器,并将它们结合起来输出)和提升树(Boosting trees)(在其他树的基础上对树的级联进行训练,纠正它们下面的错误)
决策树可以用于分类数据点(甚至回归)。
教程:https://arxiv.org/abs/1511.05741
▌TD算法
你不必思考上述哪种算法能够像DeepMind那样击败围棋世界冠军,因为它们都不能做到这一点。我们之前谈及的10种算法都是模式识别,而非策略学习者。为了学习能够解决多步骤问题的策略,比如赢得一盘棋或玩Atari游戏机,我们需要让一个空白的智能体在这世界上根据其自身面临的奖惩进行学习。这种类型的机器学习被称为强化学习。近期,在这个领域内所取得的很多(并非全部)成果都是通过将convnet或LSTM的感知能力与一组名为时间差分学习算法(Temporal Difference Learning)的算法组合而得来的。这其中包括Q-Learning、SARSA及其他算法。这些算法是对贝尔曼方程的巧妙应用,从而得到一个可以利用智能体从环境中得到的奖励来训练的损失函数。
这些算法主要用于自动运行游戏中,并在其他语言生成和目标检测项目中予以应用。
库:https://github.com/keras-rl/keras-rl
教程:https://web2.qatar.cmu.edu/~gdicaro/15381/additional/SuttonBarto-RL-5Nov17.pdf
在本公众号「七月在线实验室」回复“机器学习算法”一键获取以上资料
七月在线为你准备了一门系统的机器学习课程。课程采用线上+线下授课模式,BAT专家面对面、手把手教学;除直播答疑、作业批改、在线考试之外,特地增加开课前的入学测评,基于每一个人的测评数据量身定制个性化的不同学习路线。北京、上海、深圳、广州、杭州、沈阳、济南、郑州、成都九城同步开营。
除了为你提供一条清晰的学习路径,更有10个工业项目实战辅导 + 一对一面试求职辅导,真正帮你从零转型机器学习工程师!