谷歌大脑AutoML最新进展:用进化算法发现神经网络架构

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
其中一种生成这些体系结构的方法,是通过进化算法(evolutionary algorithms)。关于拓扑结构神经进化的传统研究(例如 Stanley 和 Miikkulainen 2002 https://www.mitpressjournals.org/doi/abs/10.1162/106365602320169811 )为我们今天能够大规模应用这些算法奠定了基础,目前许多团队正在研究这一课题,包括 OpenAI、Uber Labs、Sentient Labs 和 DeepMind。当然,Google Brain 团队也一直在考虑使用 AutoML 来实现这个目的。除了基于学习的方法(例如强化学习)之外,我们想知道是否可以使用我们的计算资源以前所未有的规模进行图像分类器的编程进化。我们能否以最少的专家资源提出最好的解决方案?如今的人工进化神经网络究竟发展到了什么水平?我们通过两篇论文来解决这些问题。
在 ICML 2017 上发表的“图像分类器的大规模演化”(https://arxiv.org/abs/1703.01041 )中,我们用简单的构建模块和简单的初始条件创建了一个进化程序。这个想法是放任大规模演化来完成创建架构的工作。这个过程从非常简单的网络开始,结果显示,分类器与当时手动设计的模型效果相当。这是一个令人鼓舞的结论,因为许多应用程序可能需要较低的用户参与度,例如,一些用户可能需要更好的模型,用更少的时间就可以成为机器学习方面的专家。很自然地,接下来要考虑的一个问题是手动设计和进化方法结合起来的效果,是否比单独使用任意一种方法的效果更好。因此,在我们最近的论文《图像分类器体系结构搜索的正则化演化》(2018 年 https://arxiv.org/abs/1802.01548 )中,我们用复杂的构建模块和良好的初始条件(下面讨论)演示了该过程。而且,我们使用 Google 的新 TPUv2 芯片(https://ai.google/tools/cloud-tpus/ )扩大了计算范围。现代硬件、专家知识和演化方法相结合,在 CIFAR-10 和 ImageNet 这两种流行的图像分类基准测试过程中生成了最新的模型。
以下是我们第一篇论文中的其中一个实验案例。在下图中,每个点都是在 CIFAR-10 数据集上训练的神经网络,通常用于训练图像分类器。最初,所有的点由 1000 个相同的简单种子模型(seed models)组成(没有隐藏层)。从简单的种子模型启动此程序非常重要,而如果我们从初始条件包含专家知识的高质量模型开始,最终获得高质量模型会相对容易。简单的种子模型开始工作后,该过程就会逐步推进。在每一步中,系统会随机选择一对神经网络。具有更高准确度的网络作为 parent,并经过复制变异生成一个 child,然后将其添加到 population 中,而另一个神经网络将消失。所有其他网络在此步骤中保持不变。这样,随着这个步骤的重复进行,population 得到了进化。
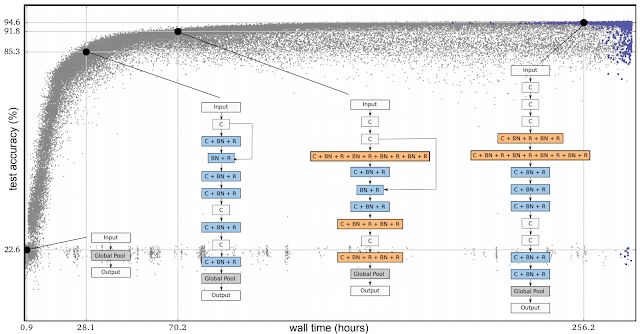
进化实验进程。每个点代表 population 中的一个元素。这四个列表是发现架构的示例,这些结构对应最好的个体(最右边,根据验证准确性筛选)和其三个 ancestor。
我们第一篇论文中所示的突变(mutations)过程非常简单:随机删除卷积,在任意层之间添加跳转连接,或者改变学习速率等。结果凸显初进化算法的潜力,而不是搜索空间的质量。例如,如果我们在某一步中使用单一突变将一个种子网络转换为 Inception-ResNet 分类器,我们可能错误地推断出该算法找到了一个好的答案。然而,在那种情况下,我们所做的一切都是将最终答案硬编码到一个复杂的变异中,以此来操纵结果。相反,如果我们坚持进行简单的突变,这种情况就不会发生,演化也能正常进行。在图中所示实验中,简单的突变和选择过程使得网络随着时间的推移而改进,即使从未使用过测试集也能达到较高的测试精度。在本文中,网络也可以继承 parents 的权重。因此,除了进化架构外,population 在探索初始条件和学习率计划搜索空间的同时,还在训练网络。结果,该过程生成了超参数经过优化的完整训练模型。而且,实验开始后并不需要输入专家知识。
综上所述,尽管我们通过简单的初始架构和直观的突变来最大程度减少研究人员的参与,但构建这些架构的构建块还是包含大量的专家知识,包括卷积、ReLUs 和批量标准化层等。我们正在对一个由这些成分构成的架构进行进化。“架构”一词并不是胡乱取的:这与建造高质量砖房的过程相似。
在发表第一篇论文之后,我们希望通过减少算法的选择来缩小搜索空间,使其更易于管理。和建造房屋一样,我们删除了所有可能造成大规模错误的方法,例如将墙放在屋顶之上。与神经网络结构搜索类似,通过修复网络的大规模结构,我们解决了一些算法问题。那么我们是如何做到这一点的呢?Zoph et al.(2017 https://arxiv.org/abs/1707.07012 )为架构搜索引入了类似模块的初始模块,后来被证明效果非常强大。他们的想法是引入一堆称之为单元(cells)的重复模块,堆栈是固定的,但各个模块的架构可以改变。
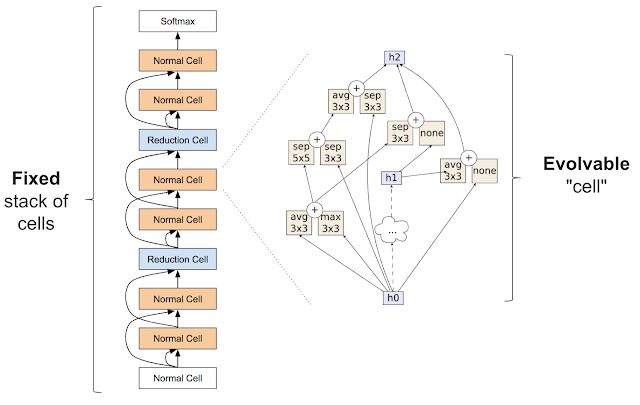
Zophet al. 中引入的构建模块。图左表示整个神经网络对外部结构,其通过重复的 cell 把地步的数据映射到顶部。右图比啊是 cell 的内部结构。该实验的目的是发现能批生成高精度网络的 cells
在我们的第二篇论文《图像分类器架构搜索的正则化进化》(2018)中,我们介绍了将进化算法应用于上述搜索空间的结果。突变通过随机重新连接输入(图中右侧箭头)或随机替换操作来修改 cells(例如,它们可以用任意选择替换图中的“max 3x3”最大池操作)。这些突变仍然相对简单,但初始条件并不简单:population 现在使用专家设计的符合外部 cells 堆叠的模型进行初始化。尽管这些种子模型中的 cells 是随机的,但我们不再从简单的模型开始,这使得最终获得高质量模型变得更容易。如果进化算法进行顺利,最终得出的网络应该比我们已知的在搜索空间内构建的所有网络都好得多。我们的论文表明,进化算法确实能得到可以与手动设计相媲美,甚至超越手动设计效果的最先进的模型。
即使突变 / 选择进化的过程并不复杂,但也许还有更直接的方法(如随机搜索)可以做到这一点。在文献中,我们也可以找到复杂度稍高但可以解决这一问题的替代方法,如强化学习。正因为如此,我们第二篇论文的主要目的是用控制比较的方法,对这些技术进行对比。
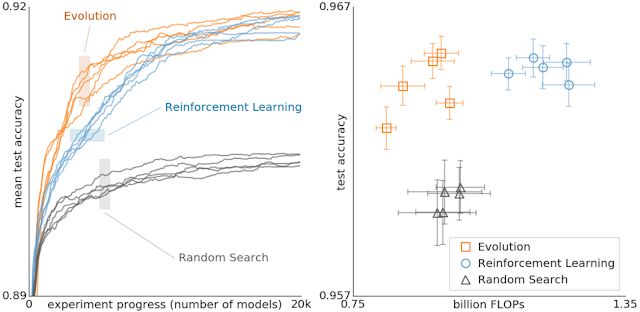
使用演化法、强化学习和随机搜索法进行架构搜索结果对比。这些实验在 CIFAR-10 数据集上完成,条件与 Zophet al. 相同,他们使用强化学习进行空间搜索。
上图比较了演化法、强化学习和随机搜索法。在左侧,每条曲线代表实验的进展,说明在搜索的早期阶段演化法比强化学习更快。这一点很重要,因为如果计算能力较低,实验可能不得不提前停止。此外,演变在数据集或搜索空间的变化非常稳定。总的来说,这种控制比较实验的目标是帮助研究界提供一个不同搜索算法之间对比关系的案例,来促进架构搜索的研究工作,而这样的实验计算成本非常高昂。请注意,如上图显示,通过演化法获得的模型具有相当高的精度,同时浮点运算量减少。
我们在第二篇论文中使用的进化算法的一个重要特征是正则化:我们不是让表现最差的神经网络消失,而是删除最初的网络,无论它们的表现有多好。这改善了正在优化的任务中变化的健壮性,并最终生成精准度更高的网络。其中一个原因可能是我们不允许权重继承,所有的网络都必须从头开始训练。因此,重新训练中会保持正则化选择,好的网络得以保留。换句话说,因为一个模型变得更加精确是出于偶然,即使是训练过程中的噪声也可能导致相同的结构会得到不同的准确度值,而只有在迭代中保持准确度的架构才能长期存活,从而选择重新训练良好的网络。更多细节可以在此论文中找到(https://arxiv.org/abs/1802.01548)。
我们生成的最先进的模型被命名为 AmoebaNets,是我们在 AutoML 方面的最新成果之一。所有这些实验消耗了巨大的计算量,在数百个 GPU / TPU 上跑了数天时间。就像一台现代式计算机胜过数千年前的机器一样,我们希望将来这些实验可以走入千家万户,有一个美好的未来。
感谢 Alok Aggarwal、Yanping Huang、Andrew Selle、Sherry Moore、Saurabh Saxena、Yutaka Leon Suematsu、Jie Tan、Alex Kurakin、Quoc Le、Barret Zoph、Jon Shlens、Vijay Vasudevan、Vincent Vanhoucke、Megan Kacholia、Jeff Dean,以及谷歌大脑团队的其他成员,没有他们就没有这项成果的面世。
原文链接:
https://research.googleblog.com/


想看更多这类文章, 请给我们点个赞吧!



