如何使用Mask RCNN模型进行图像实体分割?

目标检测是计算机视觉和模式识别的重要研究方向,主要是确定图像中是否有感兴趣的目标存在,并对其进行探测和精确定位。传统的目标检测流程采用滑动窗口进行区域选择,然后采用 SIFT、HOG 等方法进行特征提取,最后采用 SVM、Adaboost 进行类别判断。但是传统的目标检测方法面临的主要问题有:特征提取鲁棒性差,不能反应光照变化、背景多样等情况;区域选择没有针对性,时间复杂度高,窗口冗余。基于深度学习的目标检测模型有 Faster RCNN,Yolo 和 Yolo2,SSD 等,对图片中的物体进行目标检测的应用示例如下所示:

从上图中可以看出,目标检测主要指检测一张图像中有什么目标,并使用方框表示出来;而实体分割要标出每个像素所属的类别。下图的实体分割,不仅把每个物体的方框标注出来,并且把每个方框中像素所属的类别也标记出来。下图中每个方框中包含的信息有目标所属类别,置信概率以及方框中每个像素的类别。
更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)

Kaiming He 等于 2017 年提出 Mask RCNN 网络结构,该网络结构主要用于目标检测和实体分割,并且赢得了 COCO 2016 挑战赛的冠军。该文章的主要思想是把 Faster RCNN 目标检测框架进行扩展,添加一个 Mask 分支用于检测目标框中每个像素的类别,网络架构如下所示:
本文章主要讲解,应用 MaskRCNN 模型实现 Color Splash(色彩大师)的效果以及 Mask RCNN 模型的技术要点包括训练数据,主干网络,Region Proposal 生成,ROIAlign,基于 FCN 网络的 mask 特征,以及 Mask 的 Loss 函数计算。
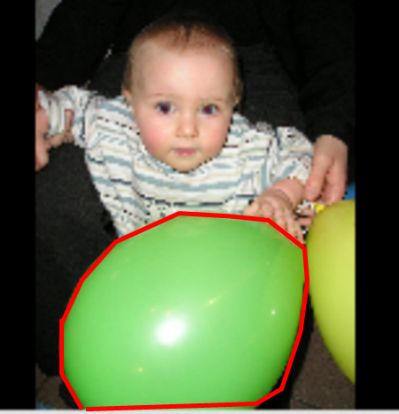
本节主要介绍应用 Mask RCNN 模型实现 Color Splash(色彩大师)的效果,识别彩色图片中的气球部分,保留该部分为彩色;但把图片中的其它部分转换为灰度色,原始图片如下所示:

转换后图片如下所示:
该应用的主要思想为:准备标注过气球的训练数据;执行 Mask RCNN 的训练;训练完毕后,对测试图片进行 Inference,找到气球部分的 mask 掩码;使用 open cv 的 API,把图片中非气球部分的图像转换为黑白色。
1.训练数据准备:首先从https://github.com/matterport/Mask_RCNN/releases/download/v2.1/balloon_dataset.zip下载标注过的训练数据。数据结构如下所示, 其中,***.jpg为原始图片,via_region_data.json为图片的标注文件。
train/
---image1.jpg
---image2.jpg
---***.jpg
---via_region_data.json
val/
---image1.jpg
---image2.jpg
---***.jpg
---via_region_data.json
标注文件的内容格式如下所示,图片中的标注区域为多边形 polygon,all_points_x 和 all_points_y 为分别表示多边形每个顶点的 x,y 坐标值。
# Loadannotations
# { 'filename':'28503151_5b5b7ec140_b.jpg',
# 'regions': {
# '0': {
# 'region_attributes': {},
# 'shape_attributes': {
# 'all_points_x': [...],
# 'all_points_y': [...],
# 'name': 'polygon'}},
# ... more regions ...
# },
# 'size': 100202
# }
2.模型训练:从 https://github.com/matterport/Mask_RCNN.git 下载 MaskRCNN 代码,该代码由 matterport 公司开源,模型主要由 keras 和 tensorflow API 实现。本应用的模型训练主函数代码为 Mask_RCNN/samples/balloon/balloon.py, 执行下述代码进行模型训练:python balloon.py train --dataset=/path/to/balloon/dataset本应用中,模型训练的主要配置参数为:
# 每次迭代GPU上训练的图片数量,如果gpu显存为12GB,一般可同时训练2个图片
IMAGES_PER_GPU = 2
# 目标检测的类别数量,包含背景色
NUM_CLASSES = 1 + 1 # 背景 + 气球
# 每个epoch的训练迭代次数
STEPS_PER_EPOCH = 100
# 目标检测出来的最小置信度
DETECTION_MIN_CONFIDENCE = 0.9
模型推理及效果展示:
#首先设定推理的图片数量,如下所示:
class InferenceConfig(config.__class__):
GPU_COUNT = 1
IMAGES_PER_GPU = 1
config = InferenceConfig()
#然后创建Inferencemodel:
model = modellib.MaskRCNN(mode="inference",model_dir=MODEL_DIR,config=config)
#加载模型权重
model.load_weights(weights_path, by_name=True)
#执行目标检测
results = model.detect([image], verbose=1)
#显示检测结果
visualize.display_instances(image, r['rois'], r['masks'],r['class_ids'],
dataset.class_names, r['scores'], ax=ax,
title="Predictions")

#显示colorsplash效果
splash =balloon.color_splash(image, r['masks'])
display_images([splash], cols=1)

Mask RCNN 是基于 Faster RCNN 的网络框架,在基础特征网络之后又加入了全卷积的 Mask 分割子网,由原来的分类、回归检测任务,变成了分类、回归、分割检测任务。本节主要介绍 Mask RCNN 中的关键技术,包括训练数据,Faster RCNN 网络结构,主干网络,Region Proposal,ROIAlign,基于 FCN 网络的 mask 特征,以及 Mask 损失函数。
训练数据:
Faster RCNN 网络主要用于 bounding box 的位置和类别的预测,所以训练数据主要包含 bounding box 的类别信息和位置信息。如下所示:
(x1,y1,x2,y2)----balloon

而 Mask RCNN 还需要预测 bounding box 中每个像素所属的类别,所以还需要相应的 mask 信息,需要用多边形标注出来,如下所示:
(x1,x2,x3,……)(y1,y2,y3,……) ----balloon
图像中每个像素的 mask 信息一般用 0,1 表示,其中 0 表示背景色,1 表示对应像素的 mask 值。通常用 binary 的二维矩阵表示 [height, width], 该 mask 矩阵可通过 open cv 的 API 生成。下图为对应 mask 的示例效果图:

Faster RCNN 网络结构
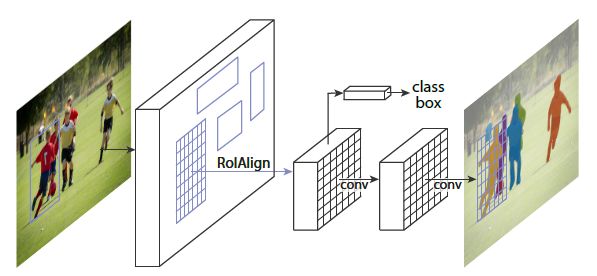
2016 年,基于 SPP 和 Fast RCNN 的思想,Shaoqing Ren, Kaiming He, Ross Girshick 提出了新的 Faster RCNN 的网络结构。该网络结构将区域生成网络(Region Proposal Networks, RPN)和 Fast RCNN 整合到一个端到端的网络中,提高了目标检测的速度及精确度。Faster RCNN 属于基于候选区域生成的目标检测网络,网络的宏观架构如下图所示:
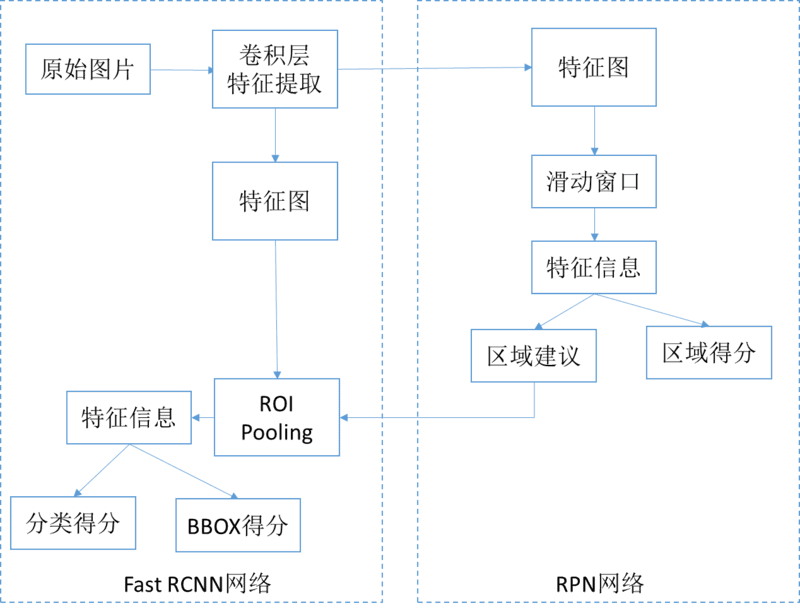
首先向共享的卷积特征模块提供输入图片。一方面提供 RPN 网络的特征提取信息,另一方面继续向前传播,生成特征图供 ROI Pooling 模型使用。
针对 RPN 网络的的输入特征图,通过滑动窗口方法生成 Anchors 和相应的特性信息,然后生成区域建议和区域得分,并对区域得分采用非极大值抑制方法得到建议区域,给 ROI 池化层用。对上述两部得到的特征图和区域建议同时输入 ROI 池化层,提取对应区域的特征。对建议区域的特征信息,输出分类得分以及回归后的 bounding-box。
主干网络
Mask RCNN 的主干网络采用了 Resnet50/101+FPN 的网络结构。原始图片在进入主干网络网络前,需要先 resize 成固定大小的图片,比如 1024*1024。如下所示,小于 1024 的高度或宽度用 0 填存。这样主干网络的图片输入大小为 [1024,1024]。
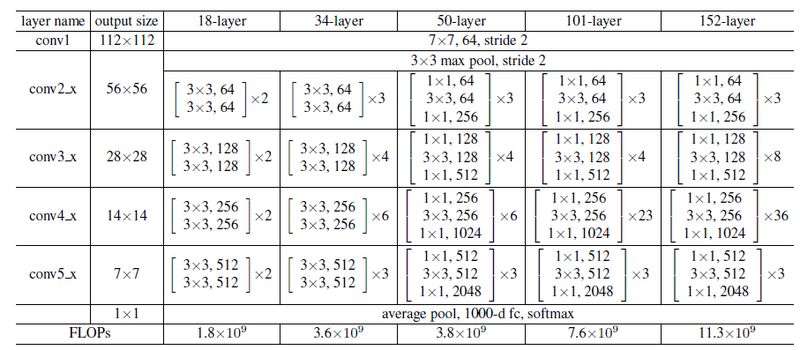
在 ResNet50/101 的主干网络中,使用了 ResNet 中 Stage2,Stage3,Stage4,Stage5 的特征图,每个特征图对应的图片 Stride 为 [4, 8, 16, 32],其中 stride 会影响图片大小的缩放比例,计算公式为 feature_size=imageSize/strideSize。这样 [Stage2,Stage3,Stage4,Stage5] 对应的特征图大小为 [256*256,128*128,64*64,32*32]。ResNet 网络结构如下图所示,其中 conv2_x,conv3_x,conv4_x,conv5_x 分别对应 Stage2,Stage3,Stage4,Stage5。
基于 [Stage2,Stage3,Stage4,Stage5] 的特征图,构建 FPN(feature pyramid networks,特征金字塔网络)结构。在目标检测里面,低层的特征图信息量比较少,但是特征图比较大,所以目标位置准确,所以容易识别一些小物体;高层特征图信息量比较丰富,但是目标位置比较粗略,特别是 stride 比较大(比如 32),图像中的小物体甚至会小于 stride 的大小,造成小物体的检测性能急剧下降。为了提高检测精度,Mask RCNN 中采用了如下的 FPN 的网络结构,一个自底向上的线路,一个自顶向下的线路以及对应层的链接。其中 1*1 的卷积核用于减少了 feature map 的个数;2up 为图片上采样,生成和上层 stage 相同大小的 feature map;最后相加对应元素,生成新的特征图。

Mask RCNN 中自底向上的网络结构,为上述介绍的 ResNet50/101,对应的特征图为 [Stage2,Stage3,Stage4,Stage5],自顶向下的网络结构,把上采样的结果和上层 Stage 的特征图进行元素相加操作,生成新的特征图 [P2, P3, P4, P5, P6], 如下所示:
P5 对应 C5
P4 对应 C4+ UpSampling2D(P5)
P3 对应 C4+ UpSampling2D(P4)
P2 对应 C4+ UpSampling2D(P3)
P6 对应 MaxPooling2D(strides=2) (P5)
这样最后生成的 FPN 特征图集合为 [P2,P3,P4,P5,P6],每个特征图对应的 Stride 为 [4, 8, 16, 32,64],对应的特征图大小为 [256*256,128*128,64*64,32*32,16*16],对应的 anchor 大小为 [32, 64, 128, 256, 512],这样底层的特征图用于去检测较小的目标,高层的特征图用于去检测较大的目标。
Region Proposal
在卷积特征图上,用 3*3 的窗口执行卷积操作。对特征图中的每个中心点,选取 k 个不同 scale、aspect ratio 的 anchor。按照 scale 和 aspect ratio 映射回原图,生成候选的 region proposals。特征图中的每个点会生成对应窗口区域的特征编码(源论文中是对应 256 维的低维特征编码)。接着对该低维的特征编码做卷积操作,输出 2*k 分类特征和 4*k 回归特征,分别对应每个点每个 anchor 属于目标的概率以及它所对应的物体的坐标信息。如下图所示:
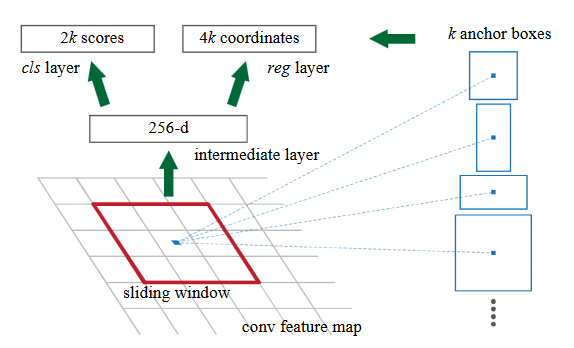
例如特征图中每个点对应的 anchor 大小为 128*128像素,256*256像素,512*512 像素,每个 anchor 的长宽比为1:1,1:2,2:1,这样特征图中的每个点会对应 9 个 anchor,假设特征图大小为60*40,这样特征图大概会生成60*40*9个 anchor,大约 2 万个。同时特征图上的每个点会对应 60*40*9 region proposal box 的回归特征和分类特征。对 60*40*9 个分类特征,按照分数排序,然后选取前 N 个回归框特征,比如前 5000 个。然后把回归框的值 (dy, dx, log(dh), log(dw)) 解码为 bounding box 的真实坐标 (y1, x1, y2, x2) 值。两类坐标的对应方式如论文中公式所示:
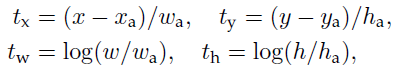
其中:(x_a,y_a)为对应 anchor 的中心点坐标,(w_a,h_a)为 anchor 的高度和宽宽。(x,y)为对应原图中预测出来的 ROI 的中心点坐标,(w,h)为对应原图中预测出来的 ROI 的高度和宽宽。(t_x,t_y)为对应特征图中心点坐标的回归值,(t_w,t_h)为对应特征图中的高度和宽度的回归值。接着通过非极大值一致算法 NMS 选择一定数量的 ROI region,比如说 2000 个。然后计算 ROI region 和 gt_boxes 的重叠覆盖情况,选择一个数量的 TRAIN_ROIS_PER_IMAGE,比如说 200 个进行训练。可以采用如下规则:
假如某 ROI 与任一目标区域的 IoU 最大,则该 anchor 判定为有目标。
假如某 ROI 与任一目标区域的 IoU>0.5,则判定为有目标;
假如某 ROI 与任一目标区域的 IoU<0.5,则判定为背景。
其中 IoU,就是预测 box 和真实 box 的覆盖率,其值等于两个 box 的交集除以两个 box 的并集。其它的 ROI 不参与训练。还可设定 ROI_POSITIVE_RATIO=0.33,比如说 33% 的 ROI 为正样本,其它为负样本。
ROI Pooling/Align
是把原图的左上角和右下角的候选区域映射到特征图上的两个对应点,这个可基于图像的缩放比例进行映射。首先把原图中 ROI 中的 bounding boxing 坐标 (y1, x1, y2, x2) 进行归一化处理,然后在特征图中把归一化的坐标映射为特征图中的坐标,这样就生成了特征图中对应的 ROI 区域坐标,如下图所示:
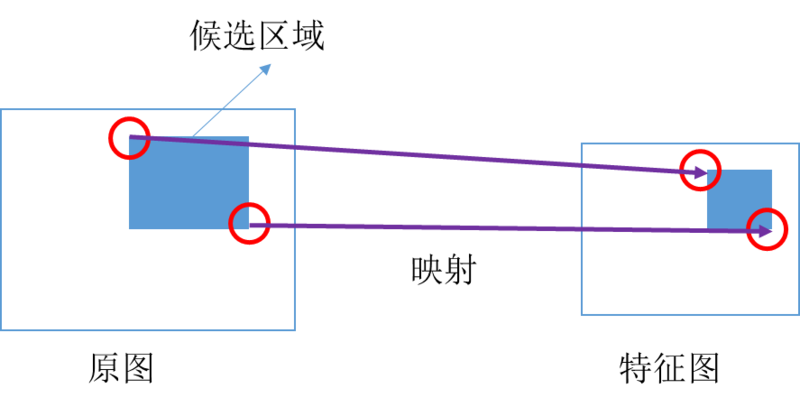
由于 ROI 映射出来的特征区域大小是不同的,而神经网络要求对类别预测特征和 box 位置回归特征的大小是固定的。这时候需要用 ROI Pooling 把大小不同的候选区域特征映射到固定大小的特征区域。ROI Pooling 的具体实现可以看做是针对 ROI 区域特征图的 Pooling,只不过因为不是固定尺寸的输入,因此每次的 pooling 网格大小需要计算,如下图所示:
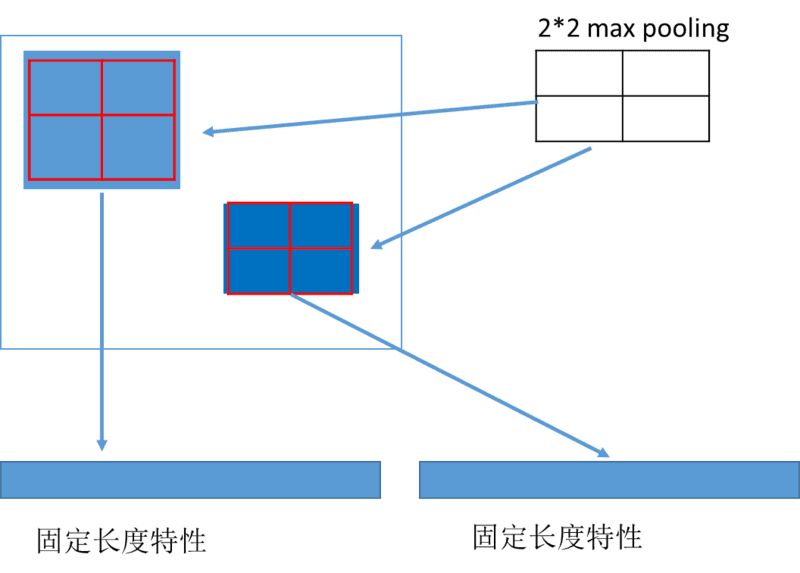
RoI Pooling 为从原图 ROI 区域映射到特征图 ROI 区域, 会对 ROISize / stride 的映射值进行取整操作,再经过最大值池化后的特征与原 ROI 之间的空间不对齐就更加明显了。ROI Align 从原图到特征图直接的 ROI 映射直接使用双线性插值,不取整,这样误差会小很多,经过池化后再对应回原图的准确性也更高些。论文中的 ROI Align 基本思想,如下图所示:
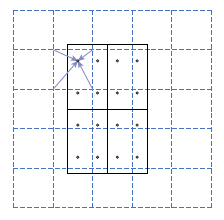
上图中虚线框为 5*5 的特征图,实线框框为的映射到特征图上的 ROI 区域,要对该 ROI 区域做 2*2 的 Pooling 操作。首先把该 ROI 区域划分为 2*2 的区域,共 4 个;然后在每个小区域中选择 4 个采样点和距离该采样点最近的 4 个特征点的像素值,使用插值的方法得到每个采样点的像素值;最后计算每个小区的 MaxPooling,生成 ROI 区域的 2*2 大小的特征图。
基于 FCN 网络的 mask 特征
基于 FCN(Fully Convolutional Networks,全卷积网络),把 ROI 区域映射为一个 m*m *numclass 的特征层,例如 28*28*80,论文中结构如下:
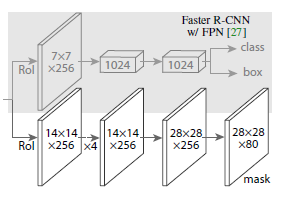
对 ROIAlign 操作生成的 ROI 区域固定大小的特征图,经过 4 个卷积操作后,生成14*14大小的特征图;然后经过上采样生成 28*28 大小的特征图;最后通过卷积操作生成大小为 28*28,深度为 80 的特征图。上述过程为全卷积网络,这样可以保证 mask 分支的每一层都有 m*m 大小的空间布局,不会缺少空间维度的向量。并且与全连接层预测 mask 相比,FCN 需要更少的参数,可以得到更好的效果。
Mask 损失函数
Mask RCNN 采用了多任务的损失函数,每个 ROI 区域的损失函数包含三部分:bounding box 的分类损失值,bounding box 位置回归损失值,mask 部分的损失值,其中 bounding box 的分类损失值和位置回归损失值同 Faster RCNN 类似。每个 ROI 区域会生成一个 m*m*numclass 的特征层,特征层中的每个值为二进制掩码,为 0 或者为 1。根据当前 ROI 区域预测的分类,假设为 k,选择对应的第 k 个 m*m 的特征层,对每个像素点应用 sigmoid 函数,然后计算平均二值交叉损失熵,如下图所示:
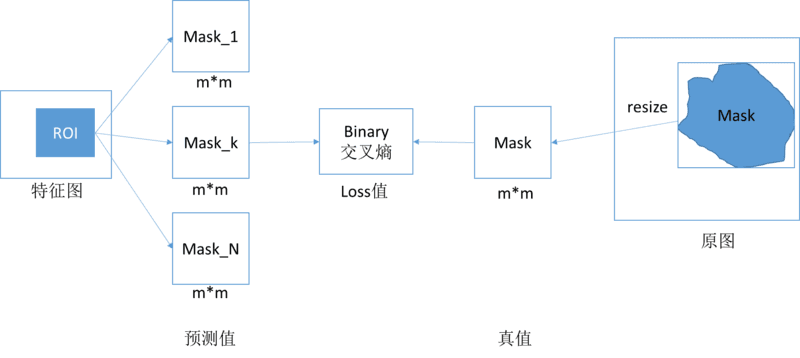
上图中首先得到预测分类为 k 的 mask 特征,然后把原图中 bounding box 包围的 mask 区域映射成 m*m 大小的 mask 区域特征,最后计算该 m*m 区域的平均二值交叉损失熵。
本文首先介绍了目标检测和实体分割的背景及差异,实体分割要在每一个像素上都检测出所属的类别。然后讲解了如何应用 Mask RCNN 模型实现 Color Splash(色彩大师)的效果;并对 Mask RCNN 的关键技术进行分析,主要包括训练数据,Faster RCNN 网络结构,主干网络(ResNet50/101+FPN),Region Proposal,ROI Align,基于 FCN 网络的 Mask 特征,以及 Mask 损失函数。用户可应用 Mask RCNN 模型架构到工业领域中相关目标检测和实体分割场景,如下所示:

参考文献
[1] https://github.com/matterport/Mask_RCNN
[2] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
[3] Mask R-CNN
[4] ResNet:Deep Residual Learning for Image Recognition
[5] FPN: Feature Pyramid Networks for Object Detection
武维(微信:allawnweiwu):博士,现为 IBM 架构师。主要从事深度学习平台及应用研究,大数据领域的研发工作。


如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!



