如何应用MTCNN和FaceNet模型实现人脸检测及识别

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
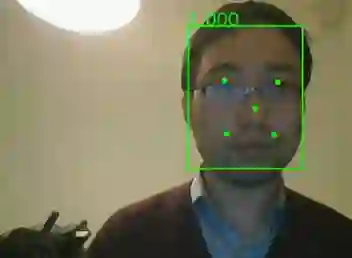
2016 年 Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, Yu Qiao 提出了人脸检测 MTCNN(Multi-task Cascaded Convolutional Networks)模型。该模式是一种 Multi-task 的人脸检测框架,使用 3 个 CNN 级联算法结构,将人脸检测和人脸特征点检测同时进行,检测效果如下图所示:
Google 工程师 Florian Schroff,Dmitry Kalenichenko,James Philbin 提出了人脸识别 FaceNet 模型,该模型没有用传统的 softmax 的方式去进行分类学习,而是抽取其中某一层作为特征,学习一个从图像到欧式空间的编码方法,然后基于这个编码再做人脸识别、人脸验证和人脸聚类等。人脸识别效果如下图所示,其中横线上表示的数字是人脸间的距离,当人脸距离小于 1.06 可看作是同一个人。

MTCNN 是多任务级联 CNN 的人脸检测深度学习模型,该模型中综合考虑了人脸边框回归和面部关键点检测。MTCNN 的网络整体架构如下图所示:
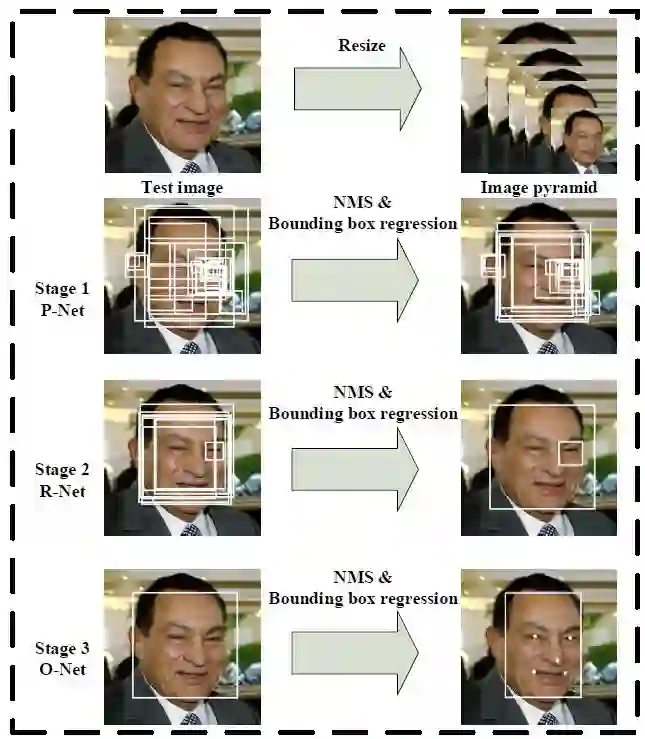
首先照片会按照不同的缩放比例,缩放成不同大小的图片,形成图片的特征金字塔。PNet 主要获得了人脸区域的候选窗口和边界框的回归向量。并用该边界框做回归,对候选窗口进行校准,然后通过非极大值抑制(NMS)来合并高度重叠的候选框。RNet 将经过 PNet 的候选框在 RNet 网络中训练,然后利用边界框的回归值微调候选窗体,再利用 NMS 去除重叠窗体。ONet 功能与 RNet 作用类似,只是在去除重叠候选窗口的同时,同时显示五个人脸关键点定位。
MTCNN 人脸检测的训练数据可以从 http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/ 地址下载。该数据集有 32,203 张图片,共有 93,703 张脸被标记,如下图所示:

标记文件的格式如下所示:
# 文件名
File name
# 标记框的数量
Number of bounding box
# 其中 x1,y1 为标记框左上角的坐标,w,h 为标记框的宽度,blur, expression, illumination, invalid, occlusion, pose 为标记框的属性,比如是否模糊,光照情况,是否遮挡,是否有效,姿势等。
x1, y1, w, h, blur, expression, illumination, invalid, occlusion, pose
人脸关键点检测的训练数据可从 http://mmlab.ie.cuhk.edu.hk/archive/CNN_FacePoint.htm 地址下载。该数据集包含 5,590 张 LFW 数据集的图片和 7,876 张从网站下载的图片。如下所示:

标记文件的格式为:
/# 第一个数据为文件名,第二和第三个数据为标记框左上角坐标,第四和第五个数据为标记框长宽,第六和第七个数据为左眼标记点,第八和第九个数据为右眼标记点,第十和第十一个数据为左嘴标记点,最后两个坐标为右嘴标记点。
lfw_5590\Abbas_Kiarostami_0001.jpg 75 165 87 177 106.750000 108.250000 143.750000 108.750000 131.250000 127.250000 106.250000 155.250000 142.750000 155.250000
PNet 的网络结构是一个全卷积的神经网络结构,如下图所:
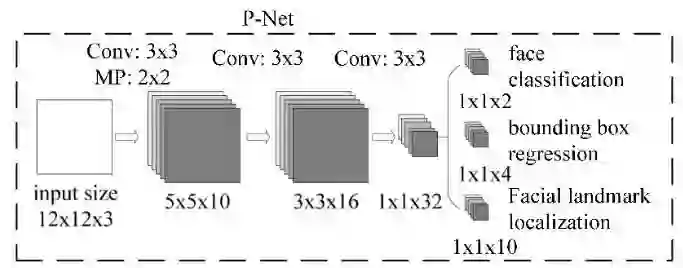
该训练网络的输入是一个 12×12 大小的图片,所以训练前需要生成 PNet 网络的训练数据。训练数据可以通过和 Guarantee True Box 的 IOU 的计算生成一系列的 bounding box。可以通过滑动窗口或者随机采样的方法获取训练数据,训练数据分为三种正样本,负样本,中间样本。其中正阳本是生成的滑动窗口和 Guarantee True Box 的 IOU 大于 0.65,负样本是 IOU 小于 0.3,中间样本是 IOU 大于 0.4 小于 0.65。
然后把 bounding box resize 成 12×12 大小的图片,转换成 12×12×3 的结构,生成 PNet 网络的训练数据。训练数据通过 10 个 3×3×3 的卷积核,2×2 的 Max Pooling(stride=2)操作,生成 10 个 5×5 的特征图。接着通过 16 个 3×3×10 的卷积核,生成 16 个 3×3 的特征图。接着通过 32 个 3×3×16 的卷积核,生成 32 个 1×1 的特征图。最后针对 32 个 1×1 的特征图,可以通过 2 个 1×1×32 的卷积核,生成 2 个 1×1 的特征图用于分类;4 个 1×1×32 的卷积核,生成 4 个 1×1 的特征图用于回归框判断;10 个 1×1×32 的卷积核,生成 10 个 1×1 的特征图用于人脸轮廓点的判断。
RNet 的模型结构如下所示:
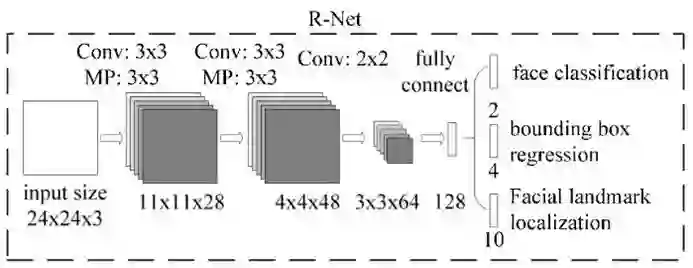
模型输入为 24×24 大小的图片,通过 28 个 3×3×3 的卷积核和 3×3(stride=2)的 max pooling 后生成 28 个 11×11 的特征图;通过 48 个 3×3×28 的卷积核和 3×3(stride=2)的 max pooling 后生成 48 个 4×4 的特征图;通过 64 个 2×2×48 的卷积核后,生成 64 个 3×3 的特征图;把 3×3×64 的特征图转换为 128 大小的全连接层;对回归框分类问题转换为大小为 2 的全连接层;对 bounding box 的位置回归问题,转换为大小为 4 的全连接层;对人脸轮廓关键点转换为大小为 10 的全连接层。
ONet 是 MTCNN 中的最后一个网络,用于做网络的最后输出。ONet 的训练数据生成类似于 RNet,检测数据为图片经过 PNet 和 RNet 网络后,检测出来的 bounding boxes,包括正样本,负样本和中间样本。ONet 的模型结构如下所示:
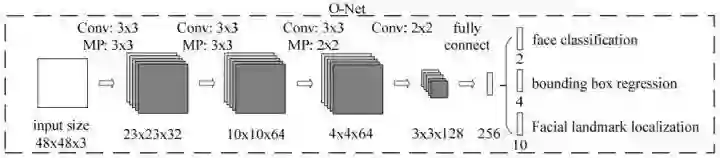
模型输入是一个 48×48×3 大小的图片,通过 32 个 3×3×3 的卷积核和 3×3(stride=2)的 max pooling 后转换为 32 个 23×23 的特征图;通过 64 个 3×3×32 的卷积核和 3×3(stride=2)的 max pooling 后转换为 64 个 10×10 的特征图;通过 64 个 3×3×64 的卷积核和 3×3(stride=2)的 max pooling 后转换为 64 个 4×4 的特征图;通过 128 个 2×2×64 的卷积核转换为 128 个 3×3 的特征图;通过全链接操作转换为 256 大小的全链接层;最好生成大小为 2 的回归框分类特征;大小为 4 的回归框位置的回归特征;大小为 10 的人脸轮廓位置回归特征。
MTCNN 的 Inference 流程如下图所示:
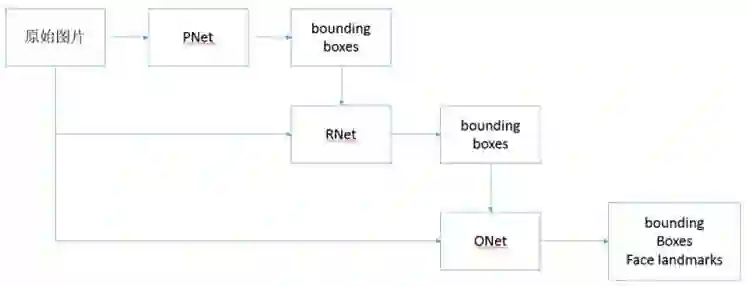
由原始图片和 PNet 生成预测的 bounding boxes。输入原始图片和 PNet 生成的 bounding box,通过 RNet,生成校正后的 bounding box。输入元素图片和 RNet 生成的 bounding box,通过 ONet,生成校正后的 bounding box 和人脸面部轮廓关键点。执行过程如下所示:
首先读入要检测的图片:image = cv2.imread(imagepath)
加载训练好的模型参数,构建检测对象:detector = MtcnnDetector
执行推理操作:all_boxes,landmarks = detector.detect_face(image)
绘制目标框:cv2.rectangle(image, box,(0,0,255))
FaceNet 主要用于验证人脸是否为同一个人,通过人脸识别这个人是谁。FaceNet 的主要思想是把人脸图像映射到一个多维空间,通过空间距离表示人脸的相似度。同个人脸图像的空间距离比较小,不同人脸图像的空间距离比较大。这样通过人脸图像的空间映射就可以实现人脸识别,FaceNet 中采用基于深度神经网络的图像映射方法和基于 triplets(三联子)的 loss 函数训练神经网络,网络直接输出为 128 维度的向量空间。
FaceNet 的训练数据可以从 http://www.cbsr.ia.ac.cn/english/CASIA-WebFace-Database.html 下载,该训练数据包括 10575 个人,共 453453 张图片。验证数据集可以从 http://vis-www.cs.umass.edu/lfw/ 地方下载,该数据集包含 13,000 张图片。训练数据的组织结构如下所示,其中目录名是人名,目录下的文件是对应人的照片。
Aaron_Eckhart
Aaron_Eckhart_0001.jpg
Aaron_Guiel
Aaron_Guiel_0001.jpg
Aaron_Patterson
Aaron_Patterson_0001.jpg
Aaron_Peirsol
Aaron_Peirsol_0001.jpg
Aaron_Peirsol_0002.jpg
Aaron_Peirsol_0003.jpg
Aaron_Peirsol_0004.jpg
······
接着对该训练数据中每个图片进行预处理,通过 MTCNN 模型把人脸检测出来,生成 FaceNet 的训练数据,如下图所示:
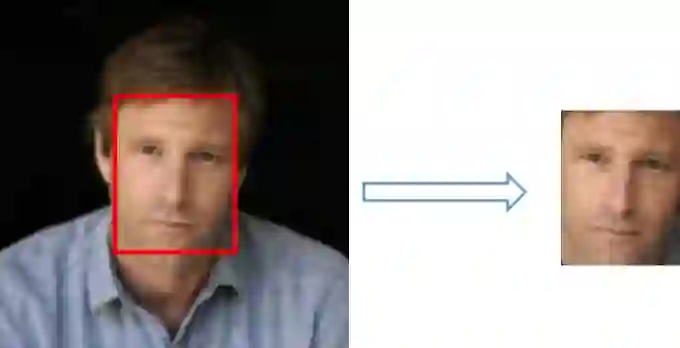
形成相应的数据结构如下所示:
Aaron_Eckhart
Aaron_Eckhart_0001_face.jpg
Aaron_Guiel
Aaron_Guiel_0001_face.jpg
······
FaceNet 的网络结构如下图所示:

其中 Batch 表示人脸的训练数据,接下来是深度卷积神经网络,然后采用 L2 归一化操作,得到人脸图像的特征表示,最后为三元组(Triplet Loss)的损失函数。
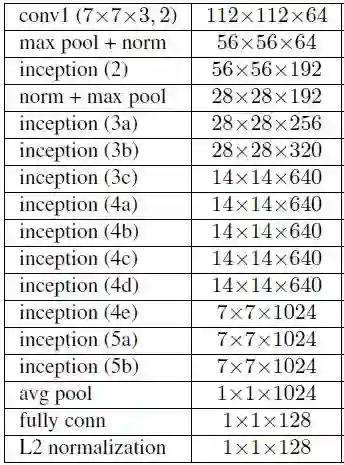
下图为 FaceNet 中采用的 Inception 架构的深度卷积神经网络:
模型结构的末端使用 triplet loss 来直接分类。triplet loss 的启发是传统 loss 函数趋向于将有一类特征的人脸图像映射到同一个空间。而 triplet loss 尝试将一个个体的人脸图像和其它人脸图像分开。三元组其实就是三个样例,如 (anchor, pos, neg),利用距离关系来判断。即在尽可能多的三元组中,使得 anchor 和 pos 正例的距离,小于 anchor 和 neg 负例的距离,如下图所示:
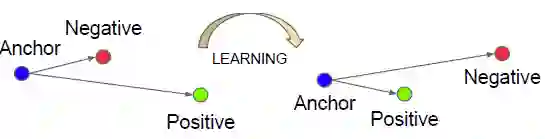
用数学公式可以表示为:
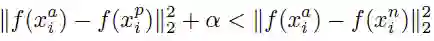
模型在每个 Mini Batch 的训练时,为了计算 triplet Loss 值,需要选定合理的 triplet 三元组。如果采用暴力的方法从所有样本中找出离他最近的反例和离它最远的正例,然后进行优化,查找时间太长,并且还会由于错误标签图像导致训练收敛困难。可采用在线生成 triplet 的方式,在每个 mini-batch 中,生成 triplet 的时候,找出所有的 anchor-pos 对,然后对每个 anchor-pos 对找出其 hard neg 样本。
主要流程如下所示:
在 mini-batch 开始的时候,从训练数据集中抽样人脸照片。比如每一个 batch 抽样多少人,每个人抽样多少张图片,这样会得到要抽样的人脸照片。
计算这些抽样图片在网络模型中得到的 embedding,这样通过计算图片的 embedding 之间的欧式距离得到三元组了。
根据得到的三元组,计算 triplet-loss,进行模型优化,更新 embedding。
FaceNet 模型推理流程如下所示:
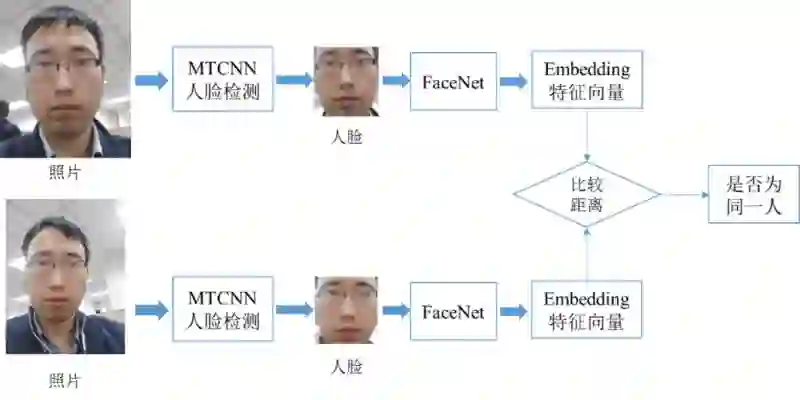
通过 MTCNN 人脸检测模型,从照片中提取人脸图像。
把人脸图像输入到 FaceNet,计算 Embedding 的特征向量。
比较特征向量间的欧式距离,判断是否为同一人,例如当特征距离小于 1 的时候认为是同一个人,特征距离大于 1 的时候认为是不同人。
本文首先介绍了人脸检测和人脸识别,人脸检测用于定位图片中的人脸,人脸识别用于识别人脸的身份。然后讲解了 MTCNN 模型的主要思想,并对 MTCNN 的关键技术进行分析,主要包括训练数据,网络架构,PNet,RNet,ONet 及模型推理。接着讲解了 FaceNet 模型的主要思想及关键技术包括训练数据,网络结构,损失方程及 Triplet 的选择。用户可应用 MTCNN 及 FaceNet 模型架构到工业领域中相关人脸检测及识别场景。
[1] MTCNN: a Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks.
[2] https://github.com/AITTSMD/MTCNN-Tensorflow
[3] FaceNet: A Unified Embedding for Face Recognition and Clustering
[4] https://github.com/davidsandberg/facenet
武维(微信:allawnweiwu):博士,现为 IBM 架构师。主要从事深度学习平台及应用研究,大数据领域的研发工作。


如果你喜欢这篇文章,或希望看到更多类似优质报道,记得点赞分享哦!
┏(^0^)┛明天见!



