TensorFlow深度学习目标检测模型及源码架构解析

AI 前线导语:目标检测是计算机视觉和模式识别的重要研究方向,主要是确定图像中是否有感兴趣的目标存在,并对其进行探测和精确定位。本文主要讲解基于深度学习的目标检测模型(Faster RCNN,Yolo 和 Yolo2,SSD)及 TensorFlow 目标检测源码架构。
目标检测是计算机视觉和模式识别的重要研究方向,主要是确定图像中是否有感兴趣的目标存在,并对其进行探测和精确定位。最早的目标检测系统主要应用于雷达信号研究,从随机、充满干扰和噪音的信号中,提取有用的特征信息。例如,对一段随机的雷达回波设置一个阈值,当提取的特征信息高于这个阈值,就认为是检测到了飞行器之类的目标。传统的目标检测流程采用滑动窗口进行区域选择,然后采用 SIFT、HOG 等方法进行特征提取,最后采用 SVM、Adaboost 进行类别判断。但是传统的目标检测方法面临的主要问题有:特征提取鲁棒性差,不能反应光照变化、背景多样等情况;区域选择没有针对性,时间复杂度高,窗口冗余。本文主要讲解基于深度学习的目标检测模型(Faster RCNN,Yolo 和 Yolo2,SSD)及 TensorFlow 目标检测源码架构。使用 TensorFlow 目标检测框架,对图片中的物体进行目标检测,示例如下图所示:

目前,在工业界已经有很多使用目标检测技术的实际应用,如面部检测;数目识别,如统计人、车、花、微生物的数量;医疗领域中癌细胞识别;图像搜索中检索图像中不同位置的物体;卫星图像分析中统计卫星图中的车,树和轮船等物体。相关用例场景如下图所示:

Faster RCNN 为由区域生成网络(Region Proposal Networks, RPN)加 Fast RCNN 组成的系统,属于基于候选区域生成的目标检测网络,网络的宏观架构如下图所示:
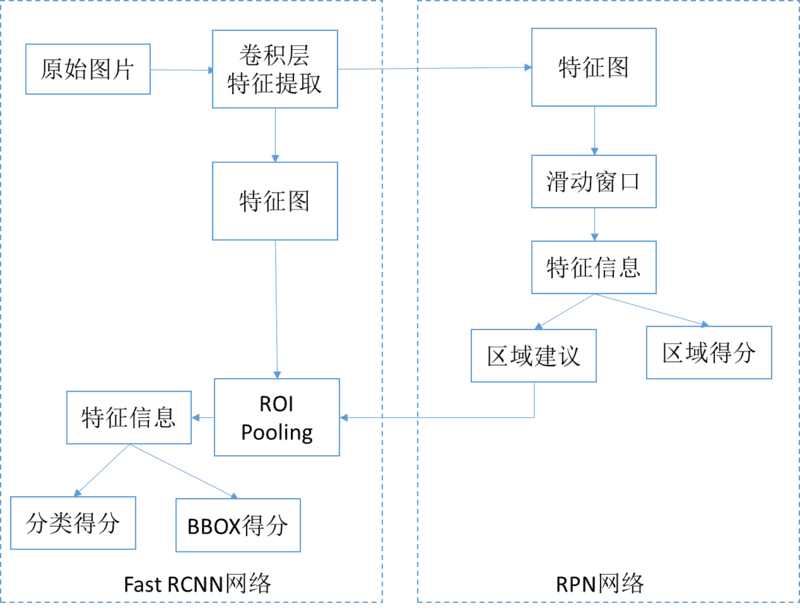
首先向共享的卷积特征模块提供输入图片。一方面提供 RPN 网络的特征提取信息,另一方面继续向前传播,生成特征图供 ROI Pooling 模型使用。
针对 RPN 网络的的输入特征图,通过滑动窗口方法生成 Anchors 和相应的特性信息,然后生成区域建议和区域得分,并对区域得分采用非极大值抑制方法得到建议区域,给 ROI 池化层用。
对上述两部得到的特征图和区域建议同时输入 ROI 池化层,提取对应区域的特征。
对建议区域的特征信息,输出分类得分以及回归后的 bounding-box。下面主要讲解 Faster RCNN 中的两个关键步骤:RPN 网络和 ROI pooling 操作。RPN 网络结构如下图所示:
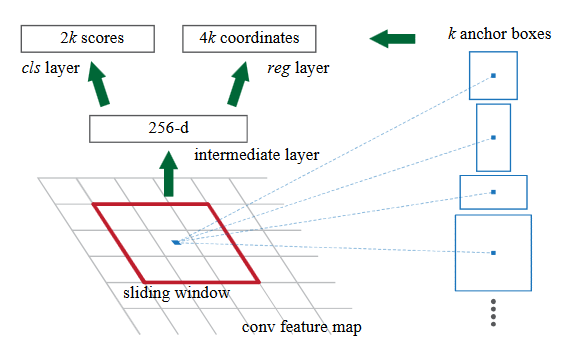
主要思想为:在卷积特征图上,用 3×3 的窗口执行滑动操作。对每个滑动窗口的中心点,选取 k 个不同 scale、aspect ratio 的 anchor。基于 3×3 的滑动窗口大小,scale 和 aspect ratio 映射回原图,生成候选的 region proposals。每个滑动窗口操作同时会生成对应窗口区域的特征编码(源论文中是对应 256 维的低维特征编码)。对该低维的特征编码做两次卷积操作,输出 2×k 分类特征和 4×k 回归特征,分别对应每个点每个 anchor 属于目标的概率以及它所对应的物体的坐标信息。
ROI 映射是把原图的左上角和右下角的候选区域映射到特征图上的两个对应点,这个可基于图像的缩放比例(视野范围变化)进行映射,如下图所示:
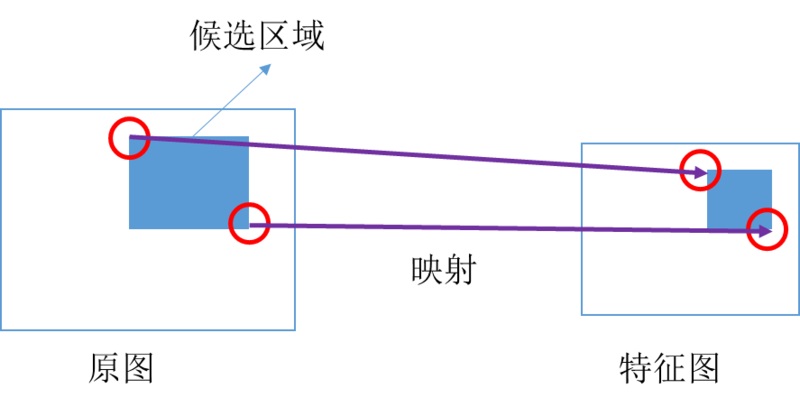
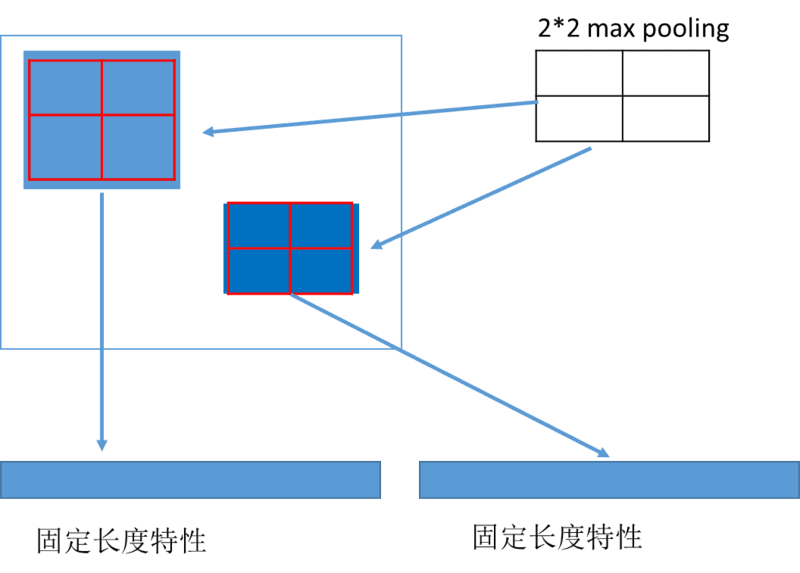
由于 ROI 映射出来的特征区域大小是不同的,而神经网络要求对类别预测特征和 box 位置回归特征的大小是固定的。这时候需要用 ROI Pooling 把大小不同的候选区域特征映射到固定大小的特征区域。ROI Pooling 的具体实现可以看做是针对 ROI 区域特征图的 Pooling,只不过因为不是固定尺寸的输入,因此每次的 pooling 网格大小需要计算,如下图所示:
Yolo 是基于回归方法的深度学习目标检测算法,YOLO 将图像分成 SxS 个格子,每个格子负责检测落入该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。如下图所示:
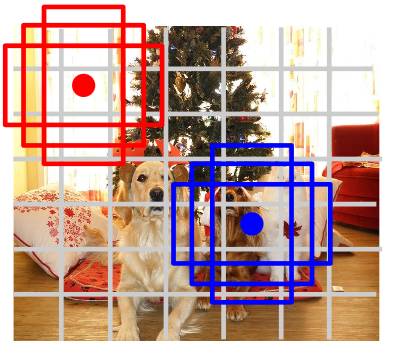
上图中红点没有对应要检测的物体,所以该网格对应背景信息;绿点对应要检测的狗,所以这个格子负责预测图像中的狗。上图被分成 7×7 的网格,每个网格对应 3 个矩形区域的位置信息,以及属于某种类别的概率信息。上图中的矩形区域称之为 Bounding Box,包含 5 个数据信息 x,y,w,h,confidence。其中 x,y 为物体的位置坐标信息;w,h 为矩形区域的宽,高信息。Confidence 表示矩形区域的目标检测的置信度(是否包含物体及矩形区域的定位准确性)。Yolo 的网络结构如下图所示:
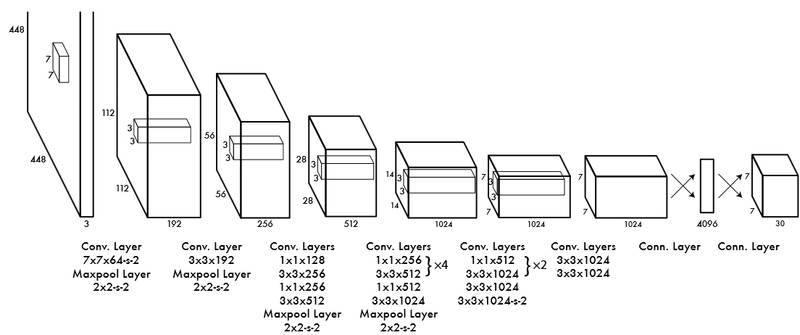
该网络中输入图像分辨率是 448x448,最后一层是 7×7×30 的卷积层,每个 7×7 的网格会对应(20+2×5)的一个特性向量,其中 20 表示要识别物体的类别,2 表示每个网络会对应 2 个 Bounding Box,5 表示每个 Bounding Box 的(x,y,w,h,confidence)特征值。
Yolo2 在 Yolo 的网络模型上做了更进一步的改进,主要加入了如下操作,提升了模型精度。

下面讲解一些主要改进:
Batch Norm:通过在卷积层后添加 batch normalization,改善了收敛速度,减少了对正则方法的依赖,使 mAP 获得了 2% 的提升。
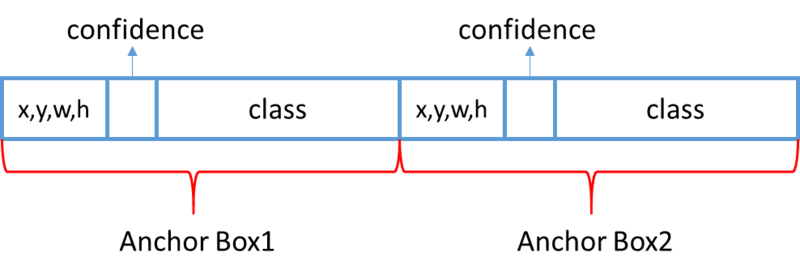
Anchor Boxes:Yolo 把全连接层 reshape 成 7×7×30 的特征进行方框预,这会导致空间信息丢失,造成方框定位不准。Yolo2 使用 Faster R-CNN 中的 anchor 思想,进行方框位置预测。并且一一对应类别的预测与每个方框位置的预测,如下图所示:
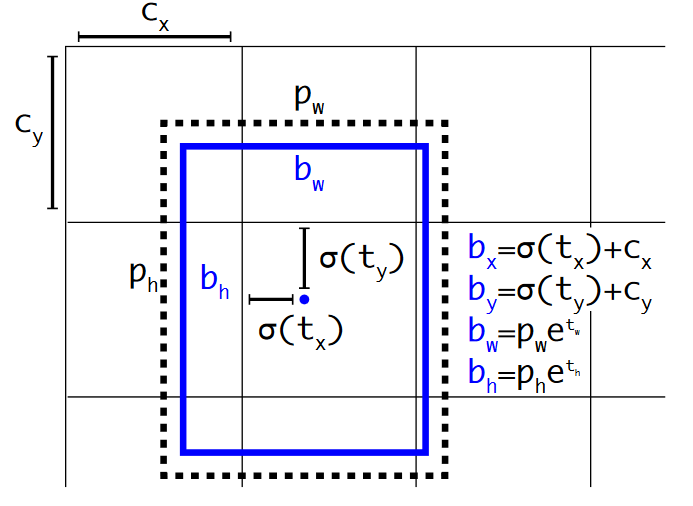
Location Prediction:直接使用 anchor boxes 时,在早期迭代的时,模型不稳定,主要原因是 boxes 的 offset 没有限定,可能会出现 anchor 检测很远的目标 box 的情况,效率比较低。而现实场景中应该是每一个 anchor 负责检测周围附近单位以内的目标 box,如下图所示。其中,每一个 bounding box 预测 4 个坐值,分别为 tx,ty,tw,th。如果这个 cell 距离 bounding box 坐标系统左上角的边距为(cx, cy)以及对应的 bounding box 的长和宽分别为 (pw, ph)。可按照上述公式计算出 bounding box 的坐标值(bx, by, bw, bh),如下图所示:
PassThrough:Yolo2 添加了转移层(passthrough layer),这一层把浅层特征图(分辨率为 26×26,是底层(13×13)分辨率 4 倍)连接到深层特征图,拥有更好的细粒度特征,对小尺度的物体检测有帮助。
SSD 同 Yolo 一样同样是基于回归方法的深度学习目标检测算法。该网络结构利用了 Faster RCNN 的 anchor box 和 YOLO 单个神经网络检测思路,该网络结构即保留了 Faster RCNN 的准确率又有 YOLO 的检测速度,可以实现高准确率的实时检测。SSD 的网络结构如下图所示:
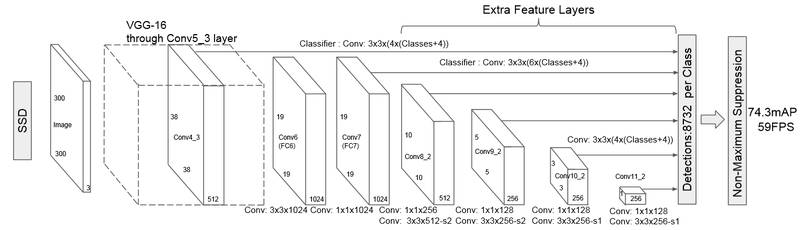
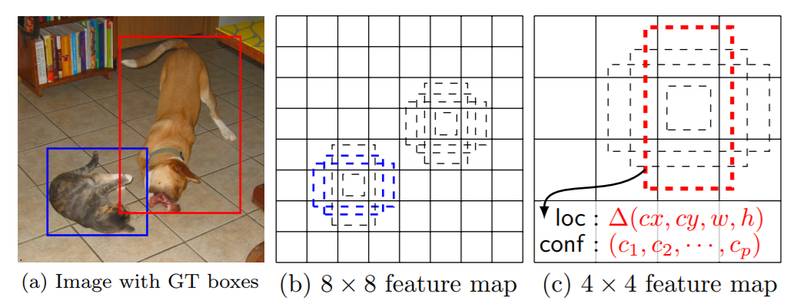
SSD 的基本思想是基于 CNN 网络,产生固定大小的 bounding boxes 位置偏移,以及每一个 box 中包含物体的概率得分后,使用非极大值抑制(Non-maximum suppression)方法得到最终的检测结果。下面主要介绍下 SSD 算法中 default boxes 生成算法,该算法中 default boxes 不必要与每个层的 receptive fields 对应。特征图中的每个网格位置,来负责原始图像中特定的区域,以及物体特定的尺寸,如下图所示:
假设使用 m 个不同层的特征图来做预测,最浅层特征图的 scale 值为 scale_min=0.2,最深层特征图的 scale_max=0.9。则每个特征图上 default box 的缩放比例可以由下面公式计算得到:
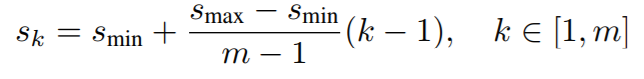
而每个默认框长宽比根据比例值计算,原论文中比例值为{1,2,3,1/2,1/3},因此,每个默认框的长宽由如下公式计算得到:
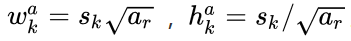
2017 年谷歌开源了 TensorFlow 目标检测框架,该目标检测框架主要包含如下目标检测模型:
基于 MobileNet 网络的 SSD 目标检测模型。
基于 Inception V2 网络的 SSD 目标检测模型。
基于 Resnet 101 网络的 Region-Based Fully Convolutional Networks (R-FCN) 目标检测模型。
基于 Resnet 101 网络的 Faster RCNN 目标检测模型。
基于 Inception Resnet v2 网络的 Faster RCNN 目标检测模型。
该 TensorFlow 目标检测框架主要依赖于如下代码:
Slim: 主要包含数据接入,特征提取网络及模型部署运行。
https://github.com/tensorflow/models/tree/master/research/slim
object_detection:负责目标检测的主要功能。
https://github.com/tensorflow/models/tree/master/research/object_detection
该目标检测框架的代码架构如下图所示:

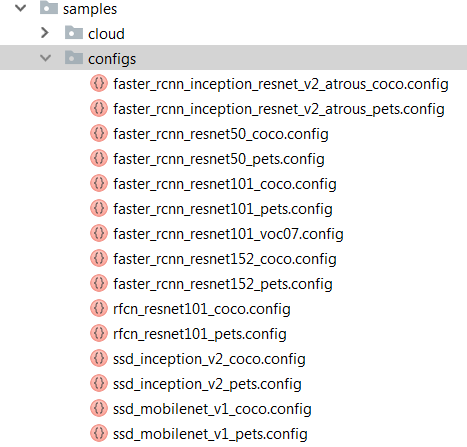
配置文件:目标检测框架通过配置文件配置模型的 train 和 evaluate 参数,并提供了相关模型的示例配置,放在 $object_detection/samples/configs 目录下,文件命名规则为:模型名 - 特征提取网络 - 数据集, 如下所示:
数据接入:首先要把 Raw Data(例如 VOC 数据集)转换为 TFRecord 数据格式,然后使用 batch queue 作为数据接入,每个 batch 的数据会返回:images, groundtruth_boxes_list, groundtruth_classes_list。每个 images 中包含预处理后的图片信息,groundtruth_boxes 和 groundtruth_classes 中是每个图片中对应的 groundtruth_boxes 坐标信息和相应的类别信息。
检测模型:目标检测模型中的 train 流程如下,其中 Preprocess 主要负责图片的预处理工作,Predict 主要负责 Box 的预测,Compute Loss 主要计算模型 Loss 值。

Evaluation 流程如下所示,Preprocess 和 Predict 同上。Post Process 主要把预测得到的 Box 进行处理(如进行最大值抑制)并转换为最后要输出的格式,如 Box 位置的绝对坐标,Box 得分以及类别信息。

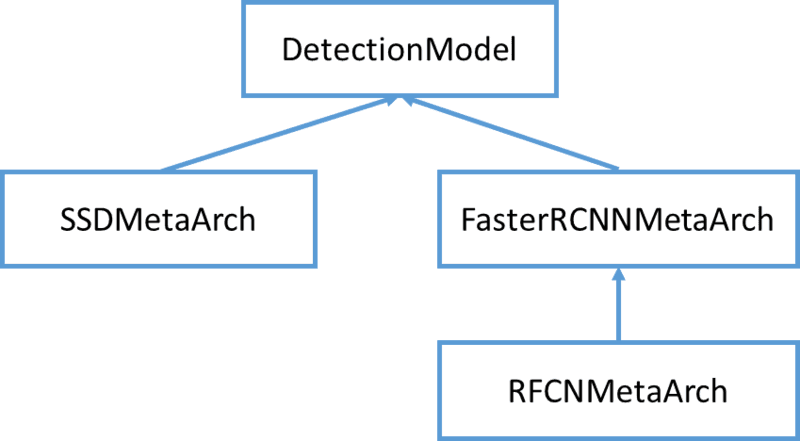
目标检测模型类继承关系如下图所示,其中 RFCN 的模型类似于 Faster RCNN,所以继承自 FasterRCNNMetaArch,主要区别在于模型的第二阶段与 Faster RCNN 模型不同。
DetectionModel 类结构如下所示,其中 groundtruth_lists 主要包含模型中 groundtruth boxes 的相关信息,loss 用于计算模型 loss 值,num_classes 为要检测的类别数目,postprocess,preprocess 和 predict 如上所述。restore_map 主要用于模型的 fine tuning。

Slim 模型部署:根据模型的运行参数(如 Worker 数量,GPU 数量),通过 Slim 的模型部署方法,可以把模型适配成单机单卡、单机多卡、多机多卡的分布式模型。
模型优化:得到模型 Loss 值后,调用相应的优化方法即可。如果要使用同步算法时,需要设定 SyncReplicasOptimizer 优化器。
模型训练:调用 Slim 的 slim.learning.train 方法,触发模型训练。
本文首先介绍了目标检测的背景以及使用场景,如面部检测、图像搜寻、卫星图像分析等。然后讲解了两类思想的目标检测模型:基于候选区域生成的目标检测模型(Faster RCNN)和基于回归方法的目标检测模型(Yolo 和 SSD);并对 Faster RCNN,Yolo 和 Yolo2,SSD 的网络结构进行了分析,主要包括网络的特征提取部分和 Anchor 机制。最后对 TensorFlow 目标检测模型的源码架构进行了分析,用户可应用该模型架构到工业领域中的相关目标检测问题。
武维(微信:allawnweiwu):博士,现为 IBM Spectrum Computing 研发工程师。主要从事大数据,深度学习,云计算等领域的研发工作。
参考文献
[1] https://www.tensorflow.org
[2] https://github.com/tensorflow/models/tree/master/research/object_detection
[3] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
[4] You Only Look Once: Unified, Real-Time Object Detection
[5] YOLO9000: Better, Faster, Stronger
[6] SSD: Single Shot MultiBox Detector
[7] http://cs231n.stanford.edu/syllabus.html




