2015-2019年摘要模型(Summarization Model)发展综述(一)
作者:张文涛
本文为授权转载,原文链接,点击阅读原文直达:
https://zhuanlan.zhihu.com/p/135468859

一、2015-2019年摘要模型发展综述(一)
二、2015-2019年摘要模型(Summarization Model)发展综述(二)
三、2015-2019年抽取式摘要模型(Extractive Summarization Model)论文详述
四、2015-2019年生成式摘要模型(Abstractive Summarization Model)论文详述
一、2015-2019年摘要模型发展综述(一)
目录
1、什么是摘要模型
2、抽取式摘要模型的发展过程
2.1、RNN-based Summarization model的发展过程
2.1.1、模型的基础结构
2.1.2、decoder的变化过程
2.1.3、encoder的变化过程
2.1.4、task formulization的变化过程
2.1.5、loss function的变化过程
2.2、Transformer-based Summarization model的发展过程
2.2.1、model structure的变化过程
2.2.2、合适摘要生成任务的pre-training task
2.3、降低冗余性的trigram blocking strategy
1、什么是摘要模型
摘要模型(Summarization model),也称为文本压缩模型(Compression model),用于将长文本(source)压缩为短文本(summaries),同时不丢失source的主要信息,使得人们可以浏览较短的summaries获悉source的主要内容。
根据摘要不同的生成方式,可以将摘要模型分成两类:抽取式摘要模型(Extractive Summarization model)和生成式摘要模型(Abstractive Summarization model)。
什么是抽取式摘要模型
抽取式摘要模型指,从source中选择合适的句子作为summaries的模型,要求被选择的句子同时满足两个要求:(1)包含source中全部的重要信息,并与其在逻辑上保持一致,这实际上是在强调summaries的information recall(2)具备最低的冗余性,即包含类似信息的句子不应同时出现在summaries中,包含非重要信息的句子不应出现在summaries中,这实际上是在强调summaries的information precision。
抽取式摘要生成任务通常被视为sequence labeling task,decoder沿着待压缩文档逐句进行二分类,每一步解码时,综合当前的句子语义信息、上一步的解码状态和待压缩文档的全局语义信息,判断当前的句子是否应被选择为摘要。
然而,抽取式摘要虽然能够以较高的标准满足上述两种要求,但是由于组成摘要的句子是从source中抽取出来的,在文本的连贯性上往往不尽如人意,甚至影响摘要的可读性,尤其是当涉及到句中实体的指代问题,还需要对摘要中的指代实体(如:he、it、this等)进行指代消解(coreference resolution)。为此,生成式摘要模型被提出来用于生成更加连贯的summaries。
什么是生成式摘要模型
生成式摘要模型指,根据source的重要信息,由decoder自发地生成summaries。与抽取式摘要一样,生成式摘要仍需满足上述的两个要求,即信息性和冗余性;同时,与抽取式摘要相比,生成式摘要具备更高的抽象性(abstraction)和连贯性(coherence/fluency),在信息的表达方式上具备更高的自由度。
生成式摘要模型通常采用seq2seq框架,encoder编码待压缩文档的语义信息,decoder通过attention机制自适应地选择有效的上下文信息,逐字生成连贯的、信息一致的摘要。
生成式摘要模型是无敌的吗
由于decoder具备更高的自由度,生成式摘要往往具备相当高的连贯性,当decoder事先经过LM objective的预训练时,这种特征就更加明显;但这种高自由度往往使得生成式摘要更加难以满足信息性和冗余性的要求,由于缺乏对生成内容的可控性,生成式摘要总是会出现以下几种错误生成内容:(1)生成与source重要信息无关的内容,甚至生成与source重要信息在逻辑上相悖的内容,当source中涉及大量的实体(entity)和关系(relation)时,这种情况尤其明显,如:source中出现文本“葛优出演了电影《让子弹飞》,这部电影由姜文导演”,生成式摘要模型生成了摘要“葛优导演《让子弹飞》”,丧失了信息性(2)decoder在生成较长的摘要时,忘记之前已经对某个重要信息进行压缩,因而不断地对该重要信息进行重复压缩,生成重复的摘要,提高了冗余性。
同样由于decoder具备更高的自由度,生成式摘要往往具备更高的抽象性,即句子的表达方式更加多样化,不需要与source中的句子采用相同的表达方式;但这种生成方式往往会遇到现实的OOV问题,即:为了提高decoder的生成效率,decoder总是使用有限的vocabulary,在decode过程中,decoder的vocabulary可能缺少用于描述source重要信息的tokens,尤其是source中的一些重要实体和关系,此时decoder生成<UNK>。为了缓解这种情况,常给生成式摘要模型增加copy mechanism,即当decoder的vocabulary没有包含某个描述source重要信息的token时,从source中复制该token,而非生成<UNK>。
从实践中来看,增加copy mechanism的生成式摘要模型生成的摘要的抽象度往往大幅下降,根据Pointer-Generator Network的实验结果来看,在训练时摘要的抽象度(不从source中copy token的概率)可以达到53%,但在测试时摘要的抽象度下降到17%;这种现象在所有引入copy mechanism的生成式摘要模型中都可以见到。人们总说,与其说decoder学会生成更加抽象的摘要,不如说decoder仅学会生成更加连贯的摘要。
两种摘要模型的现状
针对上面所述的抽取式和生成式摘要模型的各种缺点,许多论文提出了不同的改进方法。
长期以来,在各种摘要语料库(如New York Times,CNN/Daily Mails等)上,抽取式摘要模型的表现都优于生成式摘要模型的表现;直至2019年各种预训练语言模型大量出现,大幅提高了生成式摘要模型的表现,尤其是以T5(Google)或PEGASUS(Google Brain)为基础的生成式摘要模型,其表现超过了抽取式摘要模型SOTA的表现。
本文主要对2015年以来,抽取式摘要模型和生成式摘要模型的发展过程和重要的论文进行介绍,并在文末附上参考文献,方便各位进行查阅。
本章节是综述章节,总结了两种摘要模型的发展过程,对摘要模型的一些重要特性的持续改进进行归纳说明,无暇看相关论文详述的同学们可以仅阅读本章节。
2、抽取式摘要模型的发展过程
根据pre-trained model出现的时间,可以大致将抽取式摘要模型的发展过程分为两个阶段:(1)2015-2018年,RNN-based Summarization model的发展阶段(2)2019-2020年,Transformer-based Summarization model的发展阶段。
当预训练模型出现后,摘要模型虽然在建模思想上延续RNN-based model阶段的思想,但是在模型结构和训练方式上出现了较大的改变,尤其是在encoder和decoder的预训练方式等方面。为此,本文将分两个阶段介绍摘要模型的发展过程。
2.1、RNN-based Summarization model的发展过程
2.1.1、模型的基础结构
RNN-based model的基础结构由三部分构成:(1)sentence encoder,输入是每个句子的word embeddings,输出是每个句子的sentence embeddings,从而得到编码了整句上下文信息的表示(2)document encoder,输入是所有句子的sentence embeddings,输出是 待压缩文档的document embedding,从而得到编码了所有文档上下文信息的表示,在decoder解码时提供全局信息(3)decoder,对encoder得到的sentence embeddings逐句进行判断,综合document embedding提供的全局语义信息及其他信息,判断每个句子是否应被选择为摘要。
2.1.2、decoder的变化过程
ranking decoder
2015年及之前,摘要模型的decoder并没有采用DNN的网络结构,而是预先定义对sentence embeddings的打分函数,通过打分函数对每个句子进行打分,选择得分最高的k个句子作为摘要。
例如,[1]将extractive summarization视为一个最优化选择的问题,定义monotone nondecreasing submodular set function F为在待压缩文档V之上的目标函数,其中S是摘要;L(S)代表摘要的信息性,即对待压缩文档的信息覆盖度;R(S)代表摘要的多样性,即摘要信息的冗余度,对于给定长度的摘要,冗余度越高,多样性越低;λ代表两者之间的权衡,允许调节两者之间的重要性;
对于L(S),待压缩文档中的每个句子i,其与S的相似度的最大值是其与V的相似度,并通过α进行scaling,控制摘要的信息覆盖度的上限;
对于R(S), 
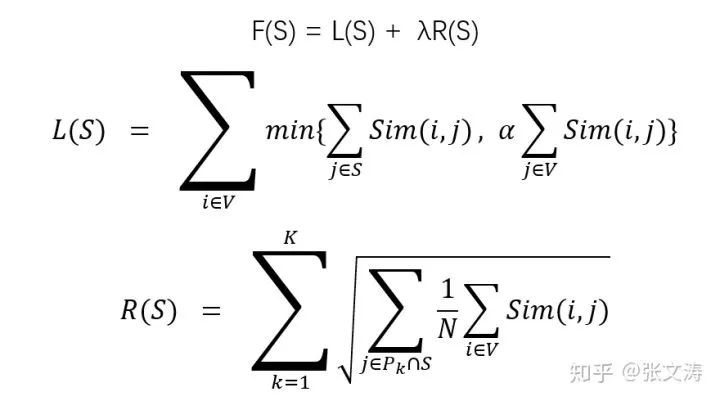
再如,[2]将摘要生成的过程分为ranking和selection两个阶段;在ranking阶段,使用逻辑回归作为打分函数,输入是每个句子的sentence embedding,拟合句子与gold summaries之间的ROUGE-2,预测每个句子的得分;在selection阶段,按照分数降序排列,按照如下规则将句子加入摘要:(1)选择V中得分最高的句子v(2)判断v是否冗余,即如果v中有超过50%的词都出现在摘要S中,即v冗余(3)如果v不冗余,则加入摘要S(4)从V中删除v(5)重复上述步骤,直至满足摘要长度k,论文使用k=100(个词)。
RNN-based decoder
2016年,[3]首次提出将LSTM作为decoder,如下图中的黄色部分,每步解码的输入是上一步句子的sentence embedding,输出的hidden state经过MLP + sigmoid classifier进行二分类,预测当前句属于摘要的概率;
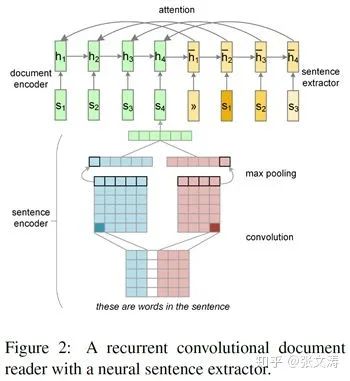
图中hidden state在送入classifier前,需与encoder对当前句进行编码后得到的上下文句向量进行信息交互,从而利用当前句的上下文信息进行解码;
此后,LSTM/GRU decoder成为RNN-based model的两类标准decoder之一,不同模型对于decoder的改进,主要集中在两方面:(1)hidden state在送入classifier前,应与哪些更有效的信息进行交互(2)采用哪种更有效的交互的方式。
如,2018年,[4]中提出,压缩文档时,除了使用文档本身的文本内容,还可以使用side information,比如:title,image caption,table caption等信息,decoder如下图黄色部分,每步解码时的输入既包含当前句的sentence embedding,还包括side information的信息;需注意,与[3]不同,此时deocder在输入和输出上已经不存在延迟,即当前句作为输入,预测当前句成为摘要的概率,这成为之后RNN decoder的标准。

再如,2018年,[5]认为,抽取式摘要生成不仅仅需要关注句子的重要度,还需要关注句子中关键词的重要度,这些关键词往往是文档的核心实体,包含关键词的句子被选择为摘要的概率总是大于不包含关键词的句子;
如下图,模型有两个decoder,一个是word level decoder(DW),每步输出都是在vocabulary上的概率分布,代表每个词被选择的概率;另一个是sentence level decoder(DS),每步输出都是在所有句子上的概率分布,代表每个句子被选择的概率;两个decoder同步解码,模型第t步解码时,通过机制Q来决定是选择word decoder在第t步的输出还是选择sentence decoder在第t步的输出;
在预测时,每个句子被选择为摘要的概率,等于该句被预测的概率与其包含的所有词被预测的概率之和,如果一个词被多次预测,则以其最大预测概率值为准。

non-RNN-based decoder
除了RNN-based decoder,还有一类常用的decoder,在解码时对每个句子单独进行分类,其他句子是否已经被选择为摘要对当前句的分类没有影响。但是,这类decoder的输入具有更高的灵活性,可以引入句子的统计信息,如:句子在待压缩文档中的位置信息通常是句子是否被选择为摘要的关键信息,重要的句子往往出现在文档中的前几句或后几句的位置。
这类decoder的基础结构是MLP + sigmoid classifier,不同模型的改进集中在decoder的输入;在预训练摘要模型出现之后,这类decoder成为目前的主流decoder。
如:2017年,[6]提出统合了5种信息的classifier layer,其公式如下:
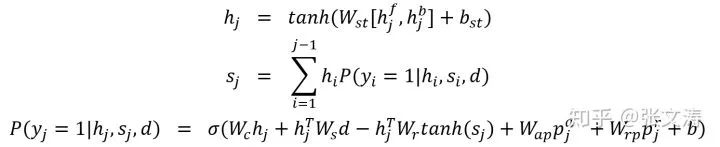
从公式中可以看出,分类器基于5种信息对每个句子作出分类:(1)content: 








预测时,预先统计每个句子的相关信息,分别作为输入送入classifier layer进行分类;由于每个句子在分类时不必须需要依赖其他句子的分类结果,可以分批次对句子进行分类,每个批次同时对多个句子进行分类,实现高度的并行性。
再如,2018年,[7]提出一个更简单的decoder,公式如下:
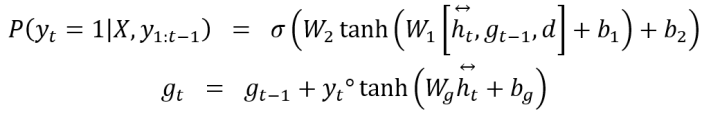
其中,d是document embedding, 

2.1.3、encoder的变化过程
encoder由两个部分构成,sentence encoder和document decoder。
document encoder用于编码待压缩文档的全局语义信息,因此所有RNN-based model都采用LSTM/GRU作为document encoder,主要的改进有:(1)由uni-directional RNN改为bi-directional RNN(2)由single-layer RNN改为multi-layer RNN,大多数模型采用3-layer RNN-based decoder。
sentence encoder主要有两种结构,CNN-based encoder和RNN-based encoder;这两种结构的encoder有各自的优缺点,并没有定论指出哪种encoder更好。对这部分的改进主要集中在:(1)CNN的结构(2)sentence embeddings的pooling方式。
CNN-based sentence encoder
2015年,[8]首次提出CNN-based sentence encoder,结构如下图中的convolution layer和max-pooling layer,300指表示的维度。
convolution layer使用相同size的filter,按公式 
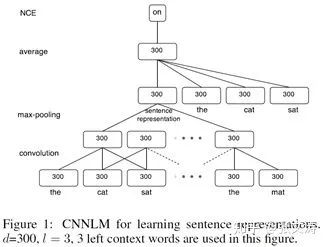
2016年,[3]对CNN-based sentence encoder进行改进,提出了具有不同filter size的sentence encoder,结构如下图中的红色和蓝色部分,不同size的filter可以抓取句中不同的语义信息,较长的conv layer抓取到句中偏语义信息的特征,较短的conv layer抓取到句中偏句法信息的特征,实现更灵活的特征获取,提高模型的robustness。
不同size的filter在输入上进行卷积得到对应的feature map,对每种feature map分别进行max-over-time pooling得到每种特征的表示,再对所有特征表示进行max-over-feature pooling,从而得到每个句子的sentence embeddings。
后续有些模型采用类似的sentence encoder结构,只是在pooling的方式上有所调整,如[4]中的模型,在第二次pooling时采用拼接而非max pooling的方式。还有一些模型,在CNN-based encoder的基础上增加更加复杂的encoder结构,以抓取句子中更加复杂的语义信息。
如:2018年,[9]提出Convolutional Sentence Tree Indexer(CSTI)用于学习层次化的句向量,结构如下图,这种句向量不仅学习到句子的局部和全局特征,还学习到局部特征间的依赖关系;这种结构抓住一种直觉:句子是由词、短语、短语或词间的序列或组成关系逐级构成的,这种层次结构通过tree structure来表现;
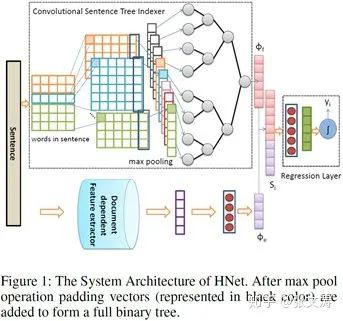
CSTI包含两个部分:(1)Conv layer与上文提到的结构相同,除了没有进行第二次max pooling,得到的特征表示作为BLSTM Tree Indexer的输入(2)BLSTM Tree Indexer(BTI)是一个full binary tree,每个leaf node上有一个transformation function,子节点和父节点间有一个composition function,通过两个function对特征表示进行自适应的信息聚合,最终在root node得到sentence embeddings,该表示不仅包含了句子的语义信息,还包含了句子中不同片段的依赖信息。
RNN-based sentence encoder
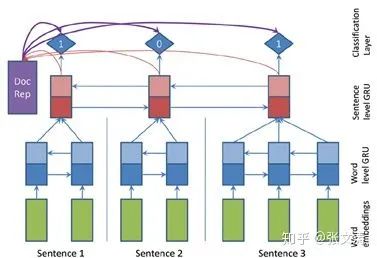
2017年,[6]首次提出bi-GRU sentence encoder,结构如下图,以word embeddings为输入,将正反两个方向的上下文向量拼接得到每个token的上下文向量,对这些上下文向量进行average pooling得到每个句子的sentence embeddings;进一步地,将这些sentence embeddings进行average pooling并经过tanh转换得到document embedding。
后续很多模型都采用这种结构的RNN-based sentence encoder,除了在pooling的方式上进行调整,如:2018年,[10]中将两个方向的GRU的last hidden state拼接作为sentence embeddings;
再如:2018年,[5]提出新的encoder,没有采用将待压缩文档分句,然后逐句进行encode的方式,而是将待压缩文档作为一个长句子由sentence encoder(EW)进行上下文编码,将每个句子的最后一个token对应的上下文向量作为sentence embeddings,由document encoder(ES)进行上下文编码;
sentence encoder采用bi-LSTM,document encoder采用uni-LSTM;这种sentence encoder的改进之处在于,编码每个句子的信息时同时可以获知句子的信息,使得每个句子的表示不仅编码本句的信息,还编码文档的信息,提高了表示的信息性。
这种结构的encoder,在2019年后成为预训练摘要模型的标准encoder结构。
2.1.4、task formulization的变化过程
抽取式摘要生成任务,通常被视为sequence labeling task,因此传统的抽取式摘要模型都是用decoder逐句对待压缩文档中的每个句子进行二分类。但是,这样的模型在预测过程中面临一个问题,即随着decoder逐句进行解码,由于各种各样的原因,decoder的准确率逐步下降;当文档中重要的信息分布在整个文档或文档偏后的位置时,抽取式摘要的准确率远低于重要信息分布在文档偏前的位置时的摘要准确率。
sequence labeling的不足之处
2018年,[10]中对这一现象进行了分析,论文定义了第t步解码的准确率,发现不同解码步时的准确率分布如下图;可以看到,无论是哪种模型,预测准确率总是在逐步下降。论文推测有可能有两个原因:(1)错误累积,导致后续的预测逐渐变差(2)重要的内容已经被抽取,剩下的内容重要性越来越小,难以做出正确决策;更极端的,剩下的句子中已经都是没用的内容,模型仍需在没用的句子中做出选择;
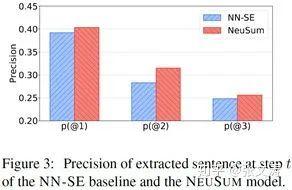
更进一步地,论文讨论了被抽取的句子的位置的分布,分布如下图,oracle是摘要句子的真实分布;从下图可见,无论哪种模型都偏向于选择leading sentences,主要是因为采用序列标注方式的模型总是从前向后标注,往往更容易将前面的句子抽取出来;另外,用于训练模型的语料大多是新闻预料,在结构上往往是总分结构,使得模型更加关注leading sentences。

global selection是一种更好的选择
为此,[10]提出一种新的task formulization,结构如下图,将摘要任务不再视为序列生成任务(sequence labeling task),而是视为最优选择任务(global selection task)。
具体来讲,模型仍然采用RNN-based decoder,但在每步解码时,并非对单个句子进分类,而是计算在尚未被选择为摘要的句子上的概率分布,代表每个句子被选择为摘要的概率,并选择概率最大的句子加入摘要;被选择的句子作为下步的输入,并计算在剩余句子上的概率分布;直至达到选择阈值。
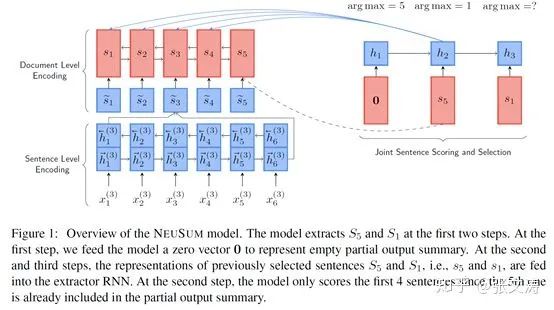
训练时,每步预测需拟合的剩余句子上的概率分布按照下式计算:(1)对每个句子 


模型旨在预测句子(在当前摘要条件下)的ROUGE score increment,这实际上引入了排序的思想;而传统的MLE或CE损失函数,旨在最大化句子的概率,但并没有说明两个都最大化的句子间谁的概率应该更大,没有引入排序的思想。而不在gold summaries中的句子,也有很多句子并非不适合加入摘要,只是相比起来不适合加入摘要,如果删除gold summaries中的句子,这些句子也可能加入摘要,这就要求模型可以对所有句子的可能性进行排序,而非仅仅考虑最大化或最小化概率。
2.1.5、loss function的变化过程
Maximum Likelihood Estimation Loss及其变体
2018年之前,抽取式摘要模型的损失函数是maximum likelihood estimation(MLE),即最大化每个句子的gold labels的概率,这种损失函数与Cross-Entropy Loss等价。
2018年,[5]提出了带选择机制Q的decoder;每步解码时,首先机制Q生成概率 



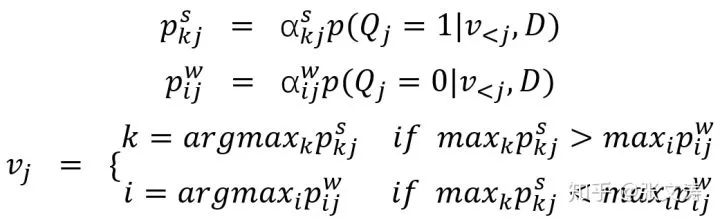
为此,[5]对MLE loss进行了调整,损失函数的计算公式如下,其中 

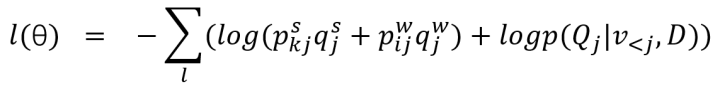
为什么提出Reinforcement Learning Loss
2018年,[11]首次提出使用reinforcement learning loss训练摘要模型;模型按照如下方法计算每个样本的RL Loss:
首先,按下述规则得到candidate summaries:(1)计算每个句子的ROUGE scores,ROUGE scores是指ROUGE-1、ROUGE-2和ROUGE-L的F1的平均值(2)选择p个score最高的句子,接着从这p个句子中得到所有总长度为n的句子的组合,评价每种组合的ROUGE scores,选择k个scores最高的组合作为候选集(3)在训练时从该候选集中按照选择一种作为candidate summary;
ROUGE-1和ROUGE-2用于评价摘要的信息性,实体、关键词等长度往往较短;ROUGE-L用于评价摘要的流利度;
然后,在训练时采样一个candidate summaries,根据其与gold summaries的差距计算reward,定义reward为ROUGE-1、ROUGE-2和ROUGE-L的F1的平均值;
最后,按下式计算RL Loss,其中y是candidate summaries,由n个句子组成,D是带压缩文档;与交叉熵损失函数相比,CE Loss相当于每个样本的损失的权重是相等的,都是1;而RL Loss相当于每个样本的损失的权重是该样本的candidate summaries的reward:
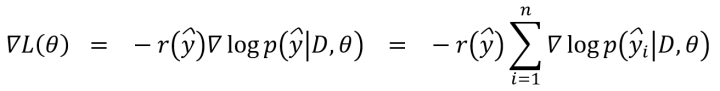
[11]提出,按照以往的MLE损失函数训练模型,至少存在以下两种问题:(1)训练、预测和评价的指标不一致:以往的模型在训练时常常采用交叉熵或似然函数,但在预测时对句子预测的分数常被用于排序,这种排序要求在训练时并没有通过损失函数体现出来(交叉熵并不保证两个最大化的概率间谁应该更大),而在评价时采用ROUGE;这种不一致使得模型在训练、预测和评价时,目标无法一致,影响模型的效果;(2)抽取式摘要模型在训练时依赖样本中的sentence labels,但大多数用于训练的语料库中,其文档多是仅有人工编写的abstractive summaries,常用的sentence labels是根据一定的规则转化而来的,正确率仅有85%,且转化过程并不保证转化后的摘要具有最高的ROUGE,也不保证其不具有冗余;
再从训练方式来看,以往的模型常采用序列标注的方式,这种方式对每个句子单独标注,往往会产生过多的正标签,使得模型过拟合数据,生成冗余度较高的摘要;如果可以进行联合标注,即每次标注是对多个句子组成的集合标注,考虑集合内的句间影响,似乎可以得到更好的结果,生成句子数尽量少的摘要,同时摘要的内容更加贴切。
当进行联合标注时,如果采用传统的交叉熵损失函数,将会欠拟合数据,因为交叉熵仅关注被包含在摘要中的句子,最大化其概率,而最小化所有不在摘要中的句子的概率;然而论文发现,即使在gold summaries外也有很多候选句具备很高的ROUGE分,其只是在排序上低于gold summaries而已,这种情况在训练时需要考虑到。
为此,论文提出使用RL Loss训练模型,强迫模型在评价摘要时,一方面从联合标注的角度考虑摘要整体的信息性和冗余性,另一方面对待压缩文档中的句子的选择概率进行合适的调整,防止模型过度关注gold summaries中的sentences。
RL Loss的持续改进
[7]提出,摘要模型的目标是抽取informative、coherent的摘要,而ROUGE-based reward仅能衡量摘要的信息性,为此提出了衡量摘要的连贯性的reward。
[7]改进了candidate summaries的抽取方式,从[11]提出的预定义candidate summaries set改为根据摘要模型预测的每个句子的概率分布,依概率抽取句子组成摘要,从而生成动态的candidate summaries。该方式成为后续论文中抽取candidate summaries的标准方式。
[7]提出sentence coherence model,预先使用pair-wise samples训练,在训练摘要模型时固定参数,不参与训练,其结构如下图:
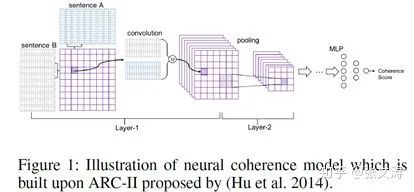
对于任意两个句子,coherence model的layer-1使用滑动窗口分别在两个句子上提取所有可能的local coherence transition,计算两个句子间的相似矩阵。上图layer-1左边部分是单个相似矩阵层的细节,右边部分是计算不同的相似矩阵,类似Conv中不同的filter得到的多个feature maps;layer-2是一个stacked CNN,最终经MLP + sigmoid classifier对两个句子的相似度进行评价。模型在训练时使用hinge loss,最大化相邻的两个句子的得分,最小化不相邻的两个句子的得分。
最终,摘要的流利度得分由其中所有相邻的sentence pairs的流利度得分相加得到,该得分作为流利度的reward,与ROUGE-based reward相加,作为RL training过程中的reward。
[12]提出另一种同时衡量信息性和连贯性的reward。同样地,[12]也借助一个预先训练好的sentence compression model来计算摘要的reward,这是一个attentive seq2seq model,在训练摘要模型时固定参数,不参与训练。
训练compression model的语料即为训练summarization model的语料,假设文档D={ 






然后根据下式,即可以计算candidate summaries的reward:
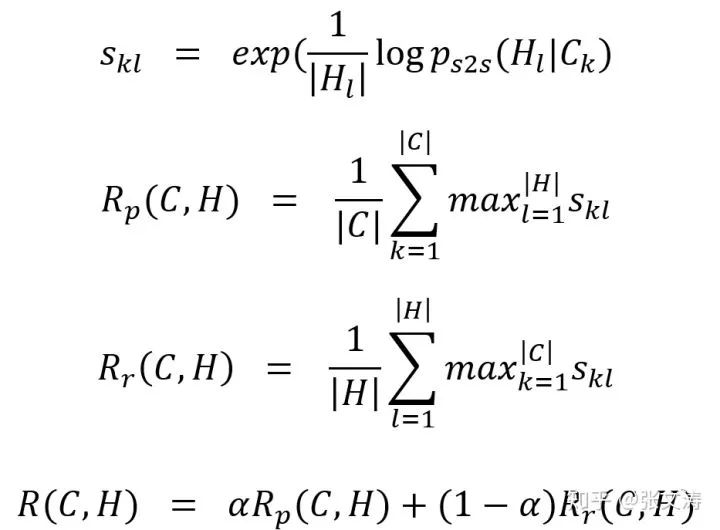
[12]使用一种被称为self-critic RL training的方式训练模型,定义梯度如下,与[11]中的梯度不同的是,下式梯度中定义 
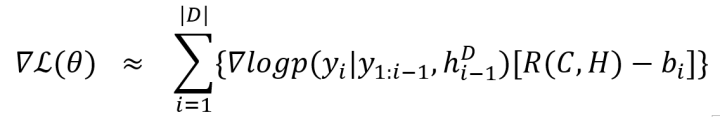
[12]中提出使用简单的线性回归估计
[13]没有采用流利度reward,仅采用ROUGE-based reward,但是在其他方面提出了改进。
例如,在生成candidate summaries时,首先预测每个句子被选择为摘要的概率 

得到
在每次选择句子时,为充分探索摘要的分布空间,除依概率 

其中,i指candidate summary中的句子对应的在文档中的位置的序列, 


再如,在估计策略梯度中的b值时,[13]按上述方式生成B个candidate summaries,将这些summaries的reward的平均值作为b的估计值,按下式计算当前的梯度:
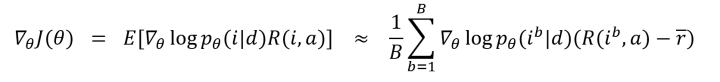
其中,a是reference summaries, 

另外,在计算reward时,[13]使用ROUGE-1/2/L F1的平均值作为reward;相比使用ROUGE recall,使用ROUGE F1可以惩罚长度过长的摘要,强迫模型在摘要冗余度的权衡上给予更多的注意,而非仅注重摘要的信息性。
在对RL Loss的诸多改进中可以看到,改进主要集中在评价摘要的流利度的reward上,然而始终没有一种流利度reward被公认为标准reward。ROUGE-based reward则逐渐成为一种标准的reward,被用于大多数RL training中。
然而ROUGE-based reward也有其自身的缺点,如:更关注n-gram级别的匹配,无法评价candidate summaries和reference summaries间的语义相似性等。虽然ROUGE-based reward有诸多问题,但其作为标准reward的事实,也反映出在摘要模型评价标准方面,除了ROUGE score外,始终没有办法提出其他更好的、通用性强的评价标准。
单独使用RL Loss是最优选择吗
既然RL Loss有诸多优点,那么单独使用RL Loss训练摘要模型是否是最佳选择?例如,[13]在训练时,仅采用RL Loss训练模型,其在CNNDM上的表现就好于[6]和[11]。
[14]进行了相关的实验,实验结果如下图。[14]发现,单独使用RL Loss训练的摘要模型,在ROUGE score上的得分高于单独使用MLE/CE Loss或混合两种Loss训练的摘要模型,这是因为ROUGE-based reward会强迫模型寻找使摘要ROUGE score更高的参数空间;
然而,进行人工评价时,混合两种Loss训练的模型生成的摘要,在可读性和相关性上的评价都最高,而仅使用RL Loss训练的模型生成的摘要,在可读性和相关性上的评价都最低。
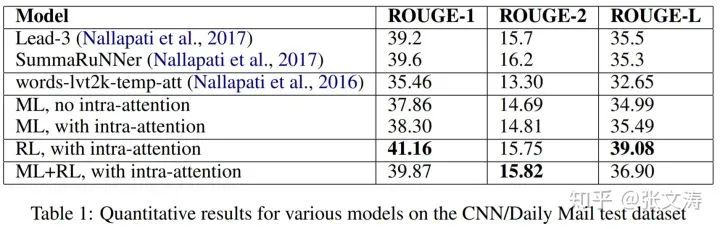

实际上,使用RL Loss训练模型的论文往往使用下述之一的方式训练模型:(1)使用MLE/CE Loss对模型进行pre-training,在此基础上,使用RL Loss对模型进行fine-tuning(2)联立MLE/CE Loss和RL Loss作为total loss,用于训练模型。其中,第(1)种方式使用的范围更广一些,可以作为标准的训练方式使用。
2.2、Transformer-based Summarization model的发展过程
2.2.1、model structure的变化过程
2019年,预训练模型的出现对Extractive Summarization Model的结构产生了影响。为了将预训练模型嵌入到摘要模型中,许多论文对摘要模型的三段式结构进行了调整,形成了几种常见的模型结构。
[15]对比了多种不同结构的摘要模型在不同语料库上的表现,不同的摘要模型具有不同的组件结构(encoder、decoder等组件)或训练方式,并据此提出了表现最好的组件组合和训练方式。
三种主要的结构
引入预训练模型后,常见的摘要模型结构有三种。
[16]使用5-layer 4-head Transformer替换RNN-based document encoder,模型结构如下图,Transformer的输出通过non-RNN-based decoder对每个句子独立分类。为了进一步提高模型的效果,[16]提出了3种适合摘要任务的预训练任务,对模型进行pre-training,将在下文中介绍。
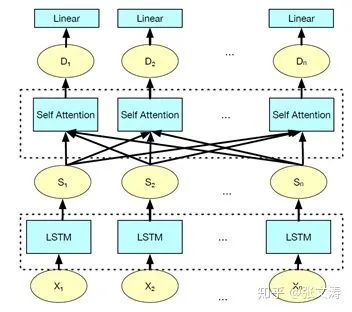
使用Transformer替换document encoder并非是唯一的选择,许多论文使用预训练模型替换摘要模型中的其他部分,如:[15]使用BERT的token embeddings替换RNN-based model的embeddings matrix,只要替换的方式合理,总是可以提高模型的效果。
[17]在使用Transformer替换document encoder(即Summarization Layers)的基础上,使用BERT-base替换sentence encoder,模型结构如下图;同样地,模型使用non-RNN-based docoder:
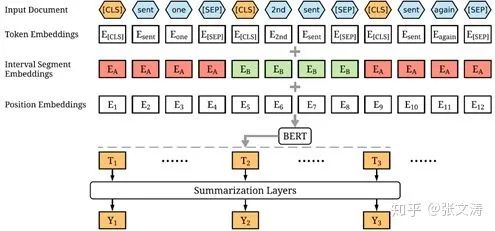
为了使BERT可以处理超过两个句子的文档,[17]对BERT进行了如下改动:(1)Vanilla Bert的输入只能处理最多两个句子,[17]对输入进行修改,为每个句子开头增加[CLS],结尾增加[SEP],从而可以将任意个句子进行拼接作为输入(2)Vanilla Bert有两个sentence embeddings,[17]将其作为interval segment embeddings按图中方式使用,即轮流作为句子的sentence embeddings(3)Vanilla Bert的输出层会输出每个token的隐向量,而extractive summarization是基于句子的,为此[17]将输出层的每个[CLS]对应的向量作为句向量,作为summarization layer的输入。
相比RNN-based sentence encoder在抽取每个句子的表示向量时仅接受该句的信息,该结构的sentence encoder的优势在于,抽取的句子表示向量包含更丰富的语义信息,使得模型可以在全局层面进行最优决策。
上述这种BERT sentence encoder + Transformer document encoder的结构逐渐成为当前预训练抽取式摘要模型的标准encoder,如:[18]也使用这种结构的sentence encoder,并在此基础上增加Graph Encoder进一步加强encoder的信息编码能力,模型结构如下图:

不同点在于,[18]并非将[CLS]的表示向量作为句向量送入Graph Encoder中,而是在SpanExt层计算在每个片段包含的句子上的attention distribution,并将以attention distribution为权重的加和表示向量作为该片段的表示向量送入Graph Encoder中。
[17]和[18]并没有提出适合摘要生成任务的预训练任务,而是使用已经预训练好的BERT初始化模型的部分结构,并在此基础上进行fine-tuning,训练其他随机初始化的结构。
[19]在使用Transformer encoder替换sentence encoder和document encoder的基础上,提出使用Transformer decoder替换RNN-based decoder,模型结构如下图;同样地,[19]也提出了适合摘要生成任务的pre-training task:
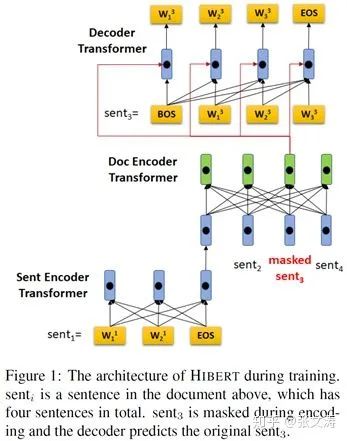
[19]并没有使用类似[17]或[18]的sentence encoder,在编码句子时独立编码每个句子;可以猜测,如果将sentence encoder替换为[17]或[18]中的sentence encoder,可以进一步提升模型的效果。
非常需要注意的是,[19]仅在pre-training时使用Transformer decoder,并对decoder中的encoder-decoder multi-head self-attention进行了下式调整,该调整是为了使decoder适用于pre-training task:
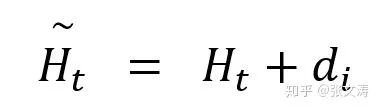
其中, 

在fine-tuning时,使用non-RNN-based decoder以document encoder的输出为输入,为每个句子预测概率。变更decoder的主要目的是提高模型的预测效率。
2.2.2、合适摘要生成任务的pre-training task
[16]提出,如果使用自监督训练对sentence encoder和document encoder进行预训练,使其可以更好地学习如何生成contextualized sentence representations,从而提升下游的summarization classification任务;相比传统摘要模型的training from scratch,这种pre-training + finetuning的方式可以更好地提升模型的表现。
为此,论文提出三种pre-training tasks:
(1)Mask:首先使用sentence encoder编码所有句向量S,然后按照25%概率选择一部分句子,将其对应的句向量替换为<unk>向量;接着使用document encoder编码所有句向量,得到被替换的句子的上下文句向量D;被替换掉的句向量S放入candidate pool,任务的目标是为每一个被替换的位置从candidate pool中预测原本的句子,使用余弦相似度为pool中每个candidate sentence打分,选择得分最高的candidate作为正确的句子:
(2)Replace:按照25%概率将文档中的一部分句子替换为其他文档的句子,经sentence encoder和document encoder得到句子的上下文句向量D,任务的目标是判断句子是否被替换,使用dense layer + sigmoid以D为输入进行预测;
(3)Switch:按照25%概率将文档中的一部分句子的位置重新排列,使这些句子不在其原来的位置上,经sentence encoder和document encoder得到句子的上下文句向量D,任务的目标是判断句子是否被重新排列,使用dense layer + sigmoid以D为输入进行预测;
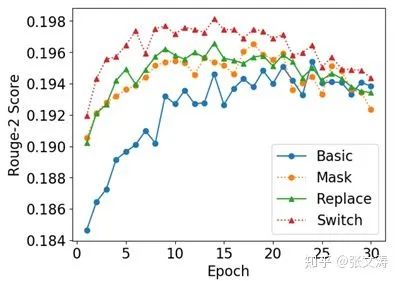
模型的训练过程分为两阶段:首先使用上述pre-training task之一对sentence encoder和document encoder进行pre-training;然后增加classifier layer,使用MLE/CE Loss对模型进行fine-tuning。[16]进行ablation ,对比了三种pre-training task的效果,实验结果如下图,可见Switch的效果是最好的:
[19]提出,MLM等预训练任务都是基于词的,而Extractive Summarization Model是基于句子的,为此论文提出document masking预训练任务:
随机选择文档中15%的句子进行mask,按照如下schema进行mask:(1)80%将句子中的每个token都替换为[MASK](除了[EOS])(2)10%不进行mask(3)10%将句子随机替换为另一个句子;文档经mask处理后,使用HIBERT + Transformer Decoder解码被mask的句子,最大化原句被解码的概率。这实际上是一个提供了上下文的语言模型任务。
模型的训练过程同样分为两个阶段:首先使用document masking和Transformer decoder对encoder进行预训练;然后将Transformer decoder替换文MLP + sigmoid classifier,使用MLE/CE Loss对模型进行fine-tuning。
目前为止,预训练抽取式摘要模型的改进主要集中在提出适合摘要生成任务的预训练任务;改进的方向是:(1)提出更合适的pre-training task,尽量使pre-training task的形式与下游摘要生成任务相似,降低任务形式不同引起的exposure bias(2)提出更合适的预训练语料,众多实验表明,pre-training corpus与fine-tuning corpus越相似,下游任务的表现越好。
RNN-based model时期常见的global selection task formulization和RL Loss暂未在预训练摘要模型时期出现,鉴于这两种结构的优势,如何将其应用于预训练摘要模型可能是未来的发展方向。
2.3、降低冗余性的trigram blocking strategy
在预测阶段,摘要模型为每个句子预测一个概率,通常选择概率最高的k个句子作为摘要;然而这种方式虽然保证了摘要的信息性,但却容易引入过高的冗余性。为了解决此问题,摘要模型在预测时,往往采用trigram blocking strategy。
trigram blocking strategy指:所有候选句子依概率降序排列,选择概率最高的句子,如果其与当前摘要存在trigram overlapping,则认为其具有冗余性,反之则将其加入摘要,并从剩余候选句子中排除;反复进行这种操作,直至满足摘要长度阈值。通过这种方式,可以保证摘要在具备信息性时,降低其冗余性。
参考文献
[1][2014][Kageback et al.][Extractive Summarization Using Continuous Vector Space Models]
[2][2015][Cao et al.][Learning Summary Prior Representation for Extractive Summarization][PriorSum]
[3][2016][Cheng and Lapata][Neural Summarization by Extracting Sentences and Words][NN-SE]
[4][2018][Narayan et al.][Neural Extractive Summarization with Side Information][SideNet]
[5][2018][Jadhav et al.][Extractive Summarization with SWAP-NET: Sentences and Words from Alternating Pointer Networks][SwapNet]
[6][2017][Nallapati et al.][SummaRuNNer: A recurrent neural network based sequence model for extractive summarization of documents][SummaRuNNer]
[7][2018][Yuxiang Wu][Learning to Extract Coherent Summary via Deep Reinforcement Learning][RNES]
[8][2015][Yin and Pei][Optimizing Sentence Modeling and Selection for Document Summa-rization][CNNLM+DivSelect]
[9][2018][Singh et al.][Unity in Diversity: Learning Distributed Heterogeneous Sentence Re-presentation for Extractive Summarization][HNet]
[10][2018][Qingyu Zhou][Neural Document Summarization by Jointly Learning to Score and Select Sentences][NeuSum]
[11][2018][Narayan][Ranking Sentences for Extractive Summarization with Reinforcement Learning][Refresh]
[12][2018][Xingxing Zhang][Neural Latent Extractive Document Summarization][Latent]
[13][2018][Dong et al.][BANDITSUM: Extractive Summarization as a Contextual Bandit][BanditSum]
[14][2018][Paulus][A Deep Reinforced Model for Abstractive Summarization][DeepRL]
[15][2019][Zhong et al.][Searching for Effective Neural Extractive Summarization: What Works and What's Next][PNBERT]
[16][2019][Wang et al.][Self-Supervised Learning for Contextualized Extractive Summarization][Switch]
[17][2019][Yang Liu][Fine-tune BERT for Extractive Summarization][BertSum]
[18][2019][Xu et al.][Discourse-Aware Neural Extractive Model for Text Summarization][DiscoBert]
[19][2019][Xingxing Zhang][HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization][HIBERT]
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇




