用AI让静图变动图:CVPR热文提出动态纹理合成新方法
选自arXiv
作者:Matthew Tesfaldet等
机器之心编译
参与:路、李泽南
图画总是只能表现事物瞬间的形象,而动画则需要逐帧手绘,费时费力,人工智能是否能够帮助我们解决这一困难?近日,来自加拿大约克大学、Ryerson 大学的研究者们提出了使用「双流卷积神经网络」的动画生成方法,其参考了人类感知动态纹理画面的双路径模式。该动画生成模型可以参考相关视频,让一张静态图片变成效果逼真的动画。目前,该研究的论文已被 CVPR 2018 大会接收,相关代码也已公开。
项目展示页:https://ryersonvisionlab.github.io/two-stream-projpage/

动画生成效果展示
很多常见的时序视觉模式使用组成元素的外观和动态(即时序模式变化)的集合进行描述。此类模式包括火、摇曳的树木和波浪起伏的水。长期以来,理解和特征化这些时序模式是人类感知、计算机视觉和计算机制图领域感兴趣的问题。之前的研究给这些模式起了很多名字,如涡流运动(turbulent-flow motion)[17]、时序纹理(temporal texture)[30]、时变纹理(time-varying texture)[3]、动态纹理 [8]、纹理运动(textured motion)[45] 和时空纹理(spacetime texture)[7]。本论文作者使用「动态纹理」(dynamic texture)。该研究提出从外观和时序动态的角度对动态纹理进行因子分析。然后使用因子分解结果完成基于示例纹理输入的动态纹理合成,从而生成新型动态纹理实例。它还产生了一种新型风格迁移形式,目标外观和动态可来自不同来源,如图 1 所示。
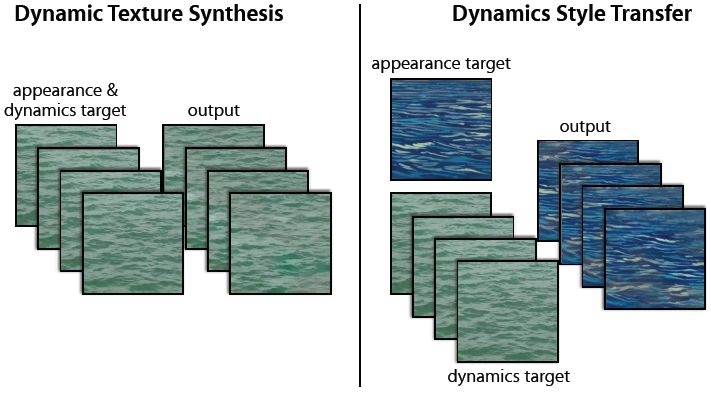
图 1:动态纹理合成。(左)给出一个输入动态纹理作为目标,本文提出的双流模型能够合成一个新的动态纹理,保留目标的外观和动态特征。(右)双流模型使合成结合一个目标的纹理外观和另一个目标的动态,从而产生二者的合成品。
本研究提出的模型由两个卷积网络(ConvNet)构成——外观流和动态流,二者分别经过预训练,用于目标识别和光流预测。与空间纹理研究 [13, 19, 33] 类似,本文根据每一个流的滤波器输出的时空数据集,总结输入动态纹理。外观流建模输入纹理每一帧的外观,动态流建模时序动态。合成过程包括优化随机初始化的噪声模式,以使每个流的时空数据与输入纹理的时空数据相匹配。该架构受到人类感知和神经科学的启发。具体来说,心理物理学研究 [6] 显示人类能够感知动态纹理的结构,即使是在没有外观提示的情况下,这表明两个流是独立的。类似地,双流假设 [16] 从两个路径建模人类视觉皮层:腹侧流(负责目标识别)和背侧流(负责运动处理)。
本文提出的对动态纹理的双流分析也被应用于纹理合成。研究者考虑了大量动态纹理,并展示了其方法能够生成新型高质量样本,匹配输入样本的逐帧外观和时序变化。此外,外观和动态的因子分解还产生了一种新型的风格迁移形式,一个纹理的动态可以与另一个纹理的外观结合起来。我们甚至可以使用单个图像作为外观目标来完成该操作,使静态图像变成动画。最后,研究者通过大量用户调研验证了其生成纹理的逼真程度。
技术方法
本文提出的双流方法包括外观流(表示每一帧的静态(纹理)外观)和动态流(表示帧与帧之间的时序变化)。每个流包括一个卷积神经网络,其激活数据被用于特征花动态纹理。合成动态纹理是一个目标为匹配激活数据的优化问题。本文提出的动态纹理合成方法见图 2。
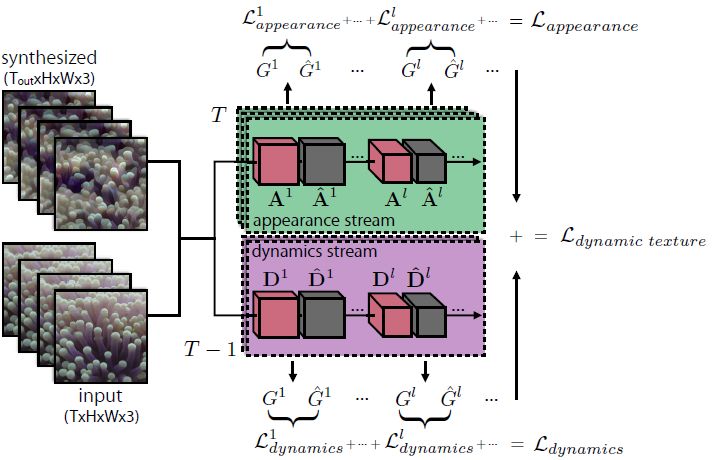
图 2:双流动态纹理生成。Gram 矩阵集表示纹理的外观和动态。匹配这些数据才能实现新纹理的生成和纹理之间的风格迁移。
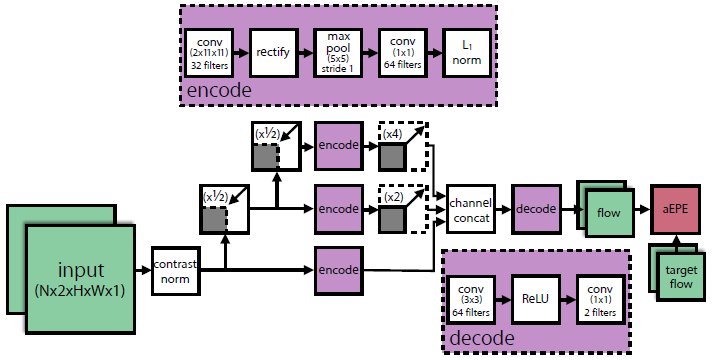
图 3:动态流卷积神经网络。该 ConvNet 基于面向时空的能量模型 [7,39],同时经过光流预测的训练。图中显示了三个扩展(scale),实践中研究者使用了五个扩展。
实验结果
(动态)纹理合成的目标是让计算机生成人类观察者无法区分是否为真实图像的样本。该研究同时也展示了各种合成结果,以及大量用户调研,以定量评估新模型生成图像的逼真程度。由于生成图像随时间变化的特性,本研究的结果多为视频展示。研究人员表示,该双流架构是由 TensorFlow 实现的,并使用 NVIDIA Titan X(Pascal)GPU 生成结果,图像合成的时间介于 1-3 小时之间,每次生成 12 帧,图像分辨率为 256×256。
论文:Two-Stream Convolutional Networks for Dynamic Texture Synthesis

论文链接:https://arxiv.org/abs/1706.06982
摘要:本论文提出了一个用于动态纹理合成的双流模型。我们的模型基于两个预训练的卷积神经网络(ConvNet),分别针对两个独立任务:目标识别、光流预测。给定一个输入动态纹理,来自目标识别卷积神经网络的滤波器响应数据压缩输入纹理每一帧的外观,而来自光流卷积神经网络的数据会对输入纹理的动态进行建模。为了生成全新的纹理,随机初始化输入序列经过优化后,用于匹配输入纹理的数据与每个流的特征数据。受到近期关于图像风格迁移的启发,同时受益于本文提出的双流模型,我们还尝试合成一种纹理的外观与另一种纹理的动态,以生成全新的动态纹理。实验表明,我们提出的方法可以生成全新的、高质量样本,可匹配输入纹理的逐帧外观及其随时间的变化。最后,我们通过深入的用户研究,对新的纹理合成方法进行量化评估。

蚂蚁金服举办首届金融科技领域算法类大赛——ATEC 蚂蚁开发者大赛人工智能大赛,点击「阅读原文」 进入大赛官网了解比赛信息,比赛报名请使用PC端浏览器打开官网。

