怎样做有商业价值的AI研究?看微软研究院如何改善微软产品

编者按:对于普通大众来讲,微软研究院的存在似乎略显神秘。但实际上每一个用户手中的微软产品背后大都有着来自微软研究院的人工智能最新研究成果的支持。本文就将从两个典型实例:运用于 Microsoft Translator 和 Azure 认知服务的机器翻译突破和运用于必应搜索的多任务学习技术入手,讲解 AI 研究是如何转化到具体微软产品上,并最终提升用户体验。本文编译自微软 AI 博客。
过去几年间,微软研究人员在人工智能领域取得了多个新突破,在对话语音识别、阅读理解、新闻报道翻译等颇具挑战性的语言理解任务中都让算法表现出了近似于人类的强大能力。现在,这些 AI 研究的成果正逐步渗透到从 Azure 到必应(Bing)的一系列微软产品中。
新的深度神经网络模型可以一次从多种自然语言理解任务中学习,改善必应的搜索结果和 SharePoint 上的问题答案;Azure 说话人识别 API 也整合了一种新的语音识别模型,在最近的 VoxCeleb 说话人识别挑战赛中表现出色;还有能够大大简化模型构建过程的 Azure 自动化机器学习功能,向用户提供所需信息的 Azure 个性化体验创建服务……这些来自微软研究院的前沿技术,最终都进入了微软产品,造福更多用户。
在以往,如果一家公司要帮助来自世界各地的客户预定跨国行程,为这一需求构建聊天机器人将耗费大量资金和精力,因为通常要分别构建不同语言的聊天机器人来协助翻译。但是由于人工智能研究的突破,算法开始能够根据不同语言的表达和遣词造句方式来更精准地解析语言中的细微差别。现在,只要构建一个聊天机器人,再加上 Microsoft Translator 就能够轻松解决。
在机器翻译领域,微软亚洲研究院与微软雷德蒙研究院共同在2018年率先证明,AI 在翻译领域可以与人类的表现相媲美。三个研究团队使用了深度神经网络和其他技术来模仿人类的翻译流程,使得机器翻译更流畅准确。这一模型不仅应用于 Microsoft Translator,也优化了 Azure 认知服务。2018年6月,基于这一技术的产品改进首先在英语和九种语言间的对译中推出,11月又更新了八种新语言的支持,大大提升了多语种的翻译质量。

微软研究人员开发的 AI 模型提高了 Microsoft Translator 的准确性,并为 Azure 认知服务提供了支持。图片为改进前后的示例。
技术研究和商业落地要考虑许多完全不同的问题,研究员和工程师要将两个环节无缝衔接在一起。“一开始,我们并没有考虑这个技术是否可以作为产品来交付,我们完全专注于技术问题本身。在问题基本解决之后,我们就自然地转向如何用这一高质量的技术改进微软产品。” 微软杰出工程师、Microsoft Translator 创始人 Arul Menezes 说。从用户需求的角度说,用户希望能即刻得到翻译结果,因此开发团队必须使复杂的大型模型变得精简而快速,在缩小算法模型和系统的同时尽可能地扩大算法涵盖的范围,将新闻文章之外的食谱、百科全书等更多类型的内容纳入对 AI 的训练。
他们采用知识蒸馏的技术来实现这一目标,让一个轻量级的“学生”模型从“老师”模型生成的翻译中进行学习,而不是像往常一样直接使用大量的原始数据进行学习。此外,“学生”模型还可以使用简化的解码算法在每个步骤中选择最佳的翻译单词,而不用再像以往一样在可能的巨大范围中费力搜索。这让“学生”模型比它的“老师”更快、更简单,同时仍能保证翻译质量。
微软亚洲研究院的研究人员还用他们开发的对偶学习方法来改善机器学习模型的翻译结果。如果一个学习日语的人想要检验她写给海外朋友的信是否准确,她可以将这封日语信件用机器翻译翻成英文来自行检查。机器学习算法也可以用同样的思路来学习。对偶学习能清洗“学生”模型的训练数据,在无需大量计算的情况下去掉翻译不准确的句子对。在大量的试验和调整后,足够简单、可以在云端运行的机器翻译“学生”模型最终达到了与更复杂的“老师”模型同样准确而实时的结果。
在迅速发展的 AI 研究界,新的自然语言理解模式不断被开发出来,必应搜索的专家们也一直在寻找符合用户需求的新技术。过去人们使用搜索引擎时,往往是先输入关键字,在搜索结果中寻找自己需要的信息,再点击链接阅读;而今,用户习惯改变了,他们直接输入问题,例如:“蒙娜丽莎要花多少钱?”或“被哪些蜘蛛咬伤是危险的?”,并且期望答案能直接出现在搜索结果的最上方。
为了满足这种需求,AI 模型不仅要能够从海量信息中选出最可靠的文档,还必须对每个文档的内容有深入的理解。这就要求它能够胜任多语言理解任务。
2019年6月,微软研究人员开发的多任务深度神经网络模型 MT-DNN(Multi-Task Deep Neural Network)在通用语言理解评估(GLUE)基准上超过了人类,可以胜任包括情感分析、文本相似性分析等9种不同的语言理解任务。MT-DNN 同时使用了知识蒸馏和多任务学习技术,使一个模型可以同时在多个任务上进行训练和学习,并能够把从一个领域中获得的知识应用于其他领域。
今年秋天,这一研究的核心已经被快速整合到了必应搜索的机器学习模型中,使必应在英语市场中多达26%的搜索回答得到了进一步的改善,并优化了20%的搜索结果中的说明生成。这一新模型可以理解和大胆估算用户的提问,比如 “《蒙娜丽莎》要花多少钱?”,它能够直接告诉用户“8.3亿美元”。为得到这一答案,它首先必须知道“花”这个词是在寻找一个数字。它还必须理解搜索结果中的内容,来估算1962年的1亿美元等同于今天的多少价值。
这样的多任务流程在以往通常会用多个模型分别处理,而可进行多任务训练的统一模型将能一次性微调多个任务,快速为用户提供易读的最佳答案。模型从一项任务中学习到有用的东西后就可以将其所学应用于其他领域。就像人类骑自行车时对平衡的掌握会有助于他学滑雪一样,多任务学习的方法正是借鉴了人类的工作方式,当人在生活中积累了越来越多的经验,当他面临新任务时就可以调用他在其他情况下学到的有用信息。
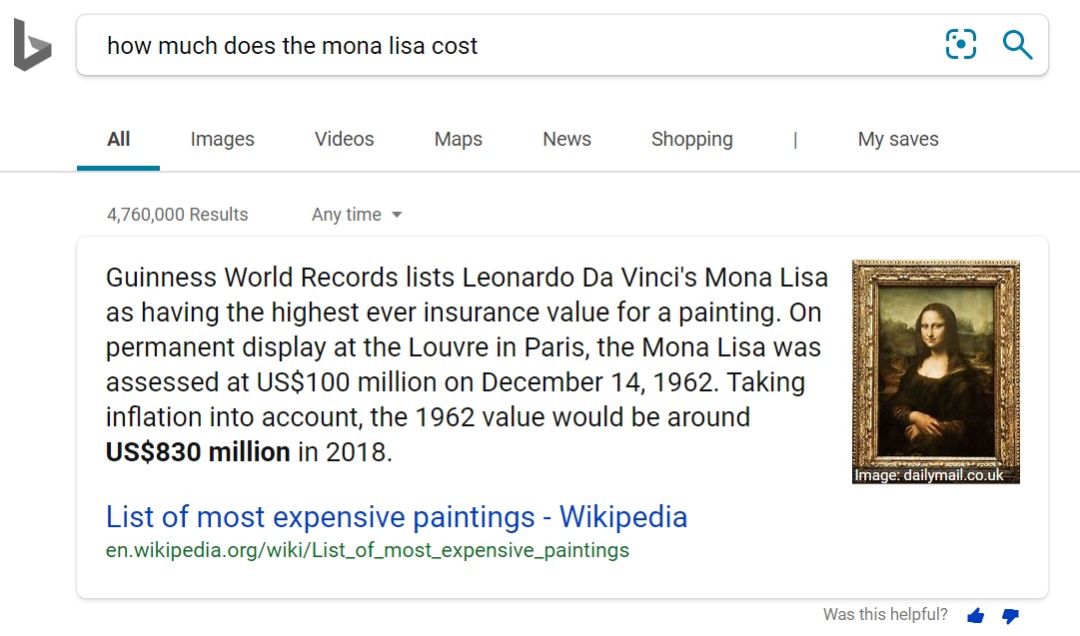
AI 很好地理解了问题,区分了1962年的1亿美元和2018年的8.3亿美元,并在说明中用粗体进行了强调。
与微软翻译团队一样,必应团队也使用知识蒸馏将庞大而复杂的模型变成精简模型,让它既快速又兼具成本效益,以便应用在商业产品上。
这些模型与方法对于企业服务也同样适用。当人们在自己的公司内部搜索信息时,必应搜索使用的模型可以帮助他们更方便地找到答案。例如,如果员工输入问题:“我可以带狗去上班吗?”即使公司的内部资料中从未出现过“狗”这一词汇,模型也可以迅速识别出“狗”是一种宠物,并根据公司的宠物政策来回答这个问题。
微软负责 Azure AI 的副总裁 Eric Boyd 表示:“作为全球最大的科技公司之一,我们需要最前沿的思维。微软研究院庞大的顶级人才队伍就提供了这样的思维,他们通过研究推动公司发展,在公司占据着特殊的地位。我们会将他们的最新研究应用到产品中,也向他们反馈我们的问题与需求,从而相互促进和发展。”
你也许还想看: