如何在Chatbot中应用深度学习? | 赠书

本书节选自图书《深度学习算法实践》
文末评论赠送本书,欢迎留言!
人类其实从很早以前就开始追求人类和机器之间的对话,早先科学家研发的机器在和人对话时都是采用规则性的回复,比如人提问后,计算机从数据库中找出相关的答案来回复。这种规则性的一对一匹配有很多限制。机器只知道问什么答什么,却不知道举一反三,比如你问它:“今天天气怎么样?”它会机械地把今天的天气告诉你。这不像人与人之间的对话,人是有各种反应的,这类反应的产生是基于人的知识结构和对话场景的。
那么,你觉得这类机器是否真的具有智能了?图灵测试是这样判断机器人是否具有智能的:测试中,一个正常人将尝试通过一连串的问答,把被试的机器与人类区分开来。一般来说,如果正常人无法分辨和自己聊天的是人还是机器人的时候,机器人就算通过测试了。
图灵测试的关键之处在于,没有定义“思维/意识”。只是将机器人作为黑盒,观察输入和输出是否达标。所以说它从一开始就绕开了“机器能思考吗?”这样的问题,而是把它替换成另外一个更具操作性的问题——“机器能做我们这些思考者所做的事吗?”。大家注意这两者其实完全不是一个层次的问题。
然而,“机器能思考吗?”和“机器能做我们这些思考者所做的事吗?”这两个问题真的可以相互替代吗?
比如说,机器能够写诗,甚至比许多资质平庸的人写出的诗更像样子。如果我们人为拟定一套标准,来为机器和人写的诗打分,那么完全有可能设计出一台能够赢过绝大多数诗人的写诗机器。但这真的和人类理解并欣赏一首诗是一回事吗?再比如,人工智能在国际象棋、围棋领域已经比人类更强大,但这真正和人类思考如何下棋是一样的吗?
世界上有这么一个关于图灵测试的奖项——“勒布纳奖”,颁给擅长模仿人类真实对话场景的机器人。然而,这个奖项大多数的获得者都没有看上去那样智能。比如一个人问一台机器“你有多爱我?”,如果它想通过图灵测试,它就不停地顾左右而言他,比如回答“你觉得呢?”事实上大多数问题都可以用反问去替代,说白了这些仅仅是一些对话技巧。而获胜者并没有真正理解“你有多爱我?”这样的问题。
这里有句话,希望大家记住:人工智能的真实使命是塑造智能,而非去刻意打造为了通过某类随机测试的“专业”程序。
所幸到今天为止,很多学者都意识到了图灵测试的局限性,如果我们要发明人工智能,就要真正清楚地定义人工智能。同样如果我们要做智能对话,我们也要清晰地定义智能对话。
在2013年的一次国际会议上,来自多伦多大学的计算机科学家发表了一篇论文,对“图灵测试”提出了批评。他认为类似这样的人机博弈其实并不能真正反映机器的智能水平。对于人工智能来说,真正构成挑战的是这样的问题:
镇上的议员们拒绝给愤怒的游行者提供游行许可——“因为他们担心会发生暴力行为”——是谁在担心暴力行为?
A.镇上的议员们
B.愤怒的游行者
类似这样的问题,机器有没有可能找到正确的答案?要判断“他”究竟指代谁,需要的不是语法书或者百科辞典,而是常识。人工智能如何能够理解一个人会在什么情况下“担心”?这些问题涉及人类语言和社会交往的本质,以及对话的前后语境。这些本质其实是一种规则,而这种规则是在不停变化的。正是在这些方面,目前人工智能还无法与人类相比。
这意味着,制造一台能与人类下棋的机器人很容易,但想要制造一台能理解人类语言的机器人却很难。
为了更好地理解机器对话,英特将现有的对话技术进行总结并画出流程图(见图3-1),这里面涉及的逻辑和模块较多,英特是从模拟人类对话的第一步,即理解人类的语言开始的,当然要做到完全理解人类的语言在目前来讲也不太可能。对于机器人来说,无论何种用途的机器人,首要需要解决的就是理解人类说了些什么,而除了命令句式以外,理解人类说什么就是理解人类提出的各种问题。请移步下一节来看看如何理解人类的提问。
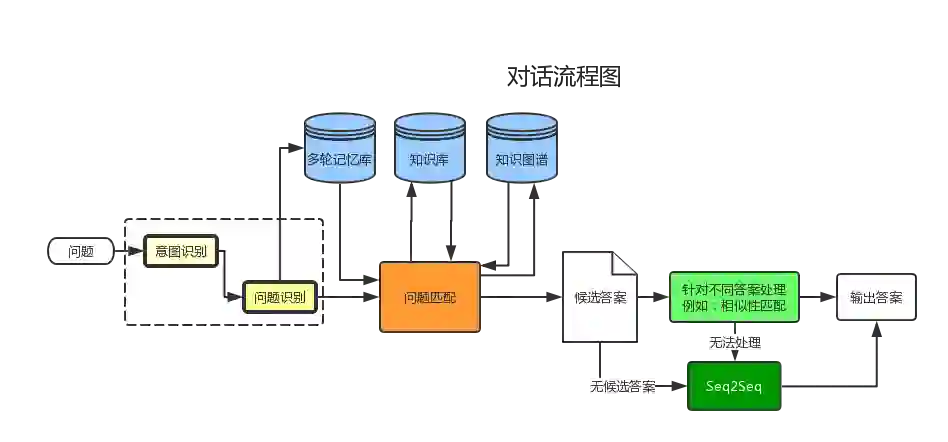
图3-1 对话流程图
理解人类提问
英特调查后发现对于中文问题来说,无非可以分成以下两类:疑问句和反问句。对于反问句当然没什么好说的,我们来重点看看疑问句。可以分为是非问句、正反问句、特指问句、选择问句,其中特指问句又可以分为人、原因、地点、时间、意见、数量、方式和其余的实体。
对于问题来说,人类也需要首先对句子做一个判断,拿特指问题来说,需要判断到底是问什么?接着将每个问题做一个初步的定位,缩小回答时的搜索范围,最后从知识体系和场景中取得答案。
英特团队按照句式结构找了些例句放进去,为后一步的句式分类准备好训练集。
比如在“特指问句_时间”里放入了如下例句。
中国第一部宪法颁布的时间?
哪天你有空?
演唱会是哪天?
又比如“特指问句_原因”里放入如下例句。
为什么人的面容千差万别?
为什么我感觉不到演员演技的好坏?
为什么不要空腹喝牛奶?
用我们在第2章提到的任意特征提取器、分类模型,我们都能得到一个基本准确的输出,比如问题“还有多久轮到我们”。
Enter the sentence you want to test(“quit” to break):还有多久轮到我们
Sentence Type: 疑问句_特指问句_时间 -- <type ‘str’>
How much:
疑问句_特指问句_时间 --> 0.568171744082
陈述句_转折复句 --> 0.0833727296382
陈述句_目的复句 --> 0.0702280010834
陈述句_时间复句 --> 0.0467500544003
陈述句_连锁复句 --> 0.0389512385469
疑问句_特指问句_地点 --> 0.0360868190755
陈述句_因果复句 --> 0.023920374049
疑问句_选择问句 --> 0.0149039847156
疑问句_特指问句_意见 --> 2.89120579329e-19
脏话_增强语气 --> -0.00288297881955
脏话_恶意脏话 --> -0.00377381341484
答案的抽取和选择
在答案的提取阶段,一般的对话像常见的智能对话助手Siri、小冰等,都是有对应的问题答案组(QA)的,这种QA数量一般都接近百万级了。而在现实工作中,没有能力和精力人工组建QA怎么办?这个时候我们可以使用互联网的信息——利用爬虫爬取。
大体过程是这样的:
(1)定义一个爬虫,针对某些问题的特点爬取候选答案。
(2)答案的抽取。从离线或在线知识库抽取候选答案,候选答案一般有多条。
(3)答案的选择。从候选答案中提取真正有效的回答。
下面用一个简单的例子来做说明。
首先是爬虫,这里我们以“百度知道”为爬取目标,爬取相关问题及答案的前几名。
def getAnswerfromZhiDao(question):
"""
Scrap answers from ZhiDao(百度知道 )
:param question:
:return:
"""
tic = time.time()
global zhidaoHeader
URL = ZHIDAO + "/index?rn=10&word=" + question
# print(URL)
Answer = []
http = httplib2.Http()
# 声明一个CookieJar对象实例来保存cookie
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
req = urllib2.Request(URL)
response = opener.open(req)
zhidaoHeader['Cookie'] = response.headers.dict['set-cookie']
response, content = http.request(URL, 'GET', headers=zhidaoHeader)
上面的代码是整个爬虫的http请求header头组装及爬取url的组装。
ZHIDAO = 'http://zhidao.baidu.com'
URL = ZHIDAO + "/index?rn=10&word=" + question
这里参数rn=10 也就是要返回10条答案。
比如用户提问:唐太宗是谁?
组装后URL = https://zhidao.baidu.com/index?rn=10&word=唐太宗是谁?
利用组装的URL返回答案条目如下。

search_result_list = etree.HTML(content.lower()).xpath("//div[@class='slist']/p/a")
# time1 = time.time()
limit_num = 3
for index in range(min(len(search_result_list), limit_num)):
url = search_result_list[index].attrib['href']
url = ZHIDAO + url
# print(url)
response, tar_page = http.request(url, 'GET', headers=zhidaoHeader)
# 判断是否做了重定向 301, 302
if response.previous is not None:
if response.previous['status'][0] == '3':
url = response.previous['location']
上一段程序先爬取答案的一级页面,也就是上面截图的页面,然后再分别爬取前三个答案的详细页面,以得到具体的答案。也可以控制爬取详细答案的数量:limit_num = 3。在爬取“百度知道”内容时需要注意重定向问题,以区分处理各种网站。
爬取了问题后,需要做答案的提取和选择,第一步是找到有一定相关度的答案候选、缩小范围;第二步就是选择并提取答案。因为我们已经做了问题的分类,这里要分情况来考虑。
(1)对于人、地点、时间等这种知道明确在问什么,也知道明确的提取规则的,我们可以按照规则去抽取答案,按出现的频率来评价答案。
(2)对于方式、原因等这样的开放式问题需要用一句话或者一段话回答,可以先选择一批备选答案,再从备选答案种挑一个最好的。
对于上面提到的问题:唐太宗是谁?这可以归类到第一种情况。下面我们来看看这个问题的处理流程。
第一步,通过问题分类、问题理解,找到了这个答案属于特指问题“人”。
第二步,针对这类问题,英特用了个小技巧,非常简单但有效:如果我们确认要找的是人、人名等,可以在备选答案中选择表示人的单词,比如名词、代词,再计算它出现的频率,比如“李世民”这个词在答案中出现了10多次,就可以将它提取出来反馈给用户。
if tar == 'who':
for i in words:
if i.flag == 'nr' and i.word not in question: # 人名
humWord.append(i.word)
return getTopWord(humWord, 1)
问数量的、问时间的、问地点的都可以照此处理。当然如果这里单独用了词频还是有问题,我们将范围缩小一些找词频就能更准确:比如将“唐太宗是谁?”这个问题在答案里做相似性匹配,找到匹配度很高的候选答案,再用以上的小技巧计算词频,当然在计算词频时,我们可以看看比如“李世民”这个词出现在句中的位置,这能帮助我们进一步精确地抽取答案。
做到这一步,英特解决了简单问句的回答,特别是针对时间、人物、地点等这种回答只有一个词的问句特别有效。但对话中大量出现上文提到的第二种情况,诸如问“如何”“怎么样”这类开放性问题,该如何处理呢?比如“唐太宗是个什么样的皇帝?”这样的开放问题。对这类问题,来看看英特的解决方法:
第一步,通过问题分类、问题理解,找到了这个答案属于特指问题“意见”。
第二步,求问题和检索答案段落的文本相似性。相似性有很多种处理方式,思路之一是可以简单地估计问题的关键词占所有问题关键词的比例(比如:唐太宗、皇帝),或者可以用word2vec、LSI来求相似度。
第三步,判断答案是否由一个段落蕴含。这里我们假设已经有了识别文本蕴含(RTE)的算法,并能准确找出“唐太宗勤勉治国,是个好皇帝。”是被蕴含的答案。
我们将答案提取打分的伪代码总结如下:
ScoreAnswers(String[] answers, String[] passages, AnalyzedQuestion aq)
scoredAnswersø
foreach answer(answers):
//特征1:段落和问题间的文本相似度
textSimcalculateTextSimilarity(answer,passages,aq,question)
//特征2:判断一个蕴含问题
entailedrecognizeEntailment(answer,passages, aq,question)
//从特征值估算置信分值
//通过增强置信分值来找到相似答案
return scoredAnswers
通过相似度评分和蕴含评分得到答案的总体评分,然后再将答案排序输出第一个答案。
对于相似度评分无需过多描述,但是蕴含呢?英特查了很多资料后决定了蕴含关系的研发方案。
蕴含关系
蕴含关系,是为了评价从一段文字中得到的推论是否符合原文的本意,我们这里用蕴含关系来做答案中是否包含着问题的判断,其实就是求某种语义上的相似性或相关性。
下面举个例子。
T:第一次世界大战(简称一战;英语:World War I、WW I、Great War)是一场于1914年7月28日至1918年11月11日主要发生在欧洲,然而战火最终延烧至全球的战争,当时世界上大多数国家都被卷入这场战争,是人类史上第一场全球性规模的大型战争,史称“第一次世界大战”。
H:第一次世界大战的时间
label:1 ← 这里标签为1,表示答案中蕴含问题。
T:第二十九届奥林匹克运动会(英语:the Games of the XXIX Olympiad;法语:les Jeux de la XXIXe Olympiade),又称2008年夏季奥运会或北京奥运会,于2008年8月8日至24日在中华人民共和国首都北京举行。
H:东京奥林匹克运动会的举办时间
label:0 ← 这里标签为0,表示答案中没有蕴含问题。
从例子可以看出,求蕴含关系就是求一个相似度,但还不完全像求相似度,蕴含关系中,选择哪些特征才是这个算法在问答中应用的重点,只要把特征选出扔到SVM分类器中就可以做训练了。
一般提取哪些特征出来呢?我们先人工选择特征并提取。看看代码,除了词的频率和位置还可以提取下面这些特征(规律):
features['word_overlap'] = len(extractor.overlap('word'))
# hyp 与 text 中重复的 word
features['word_hyp_extra'] = len(extractor.hyp_extra('word'))
# hyp 有 但 text 中没有的 word
features['ne_overlap'] = len(extractor.overlap('ne'))
# hyp 与 text 中重复的 ne
features['ne_hyp_extra'] = len(extractor.hyp_extra('ne'))
# hyp 有 但 text 中没有的 ne
features['neg_txt'] = len(extractor.negwords & extractor.text_words)
# text 中的 否定词
features['neg_hyp'] = len(extractor.negwords & extractor.hyp_words)
# hyp 中的 否定词
ne指的是命名实体(Named Entity),其中hyp指的是问题,大家观察蕴含的示例代码可以看出,英特在项目进行中发现光是名词实体不足以提取到完整特征,于是将时间名词、成语、状态词都加入到ne范畴中,提取规则同上保持不变。
当然如果你不想用人工方式提取答案和问题的特征,仍然可以用在第2章我们提到的CNN+RNN方式提取特征,而这种提取方式可以稍作变化,将词性作为输入加到Word Embedding层后。
生成式对话模型(Generative Model)
前面的这类方法可以总结为检索式方法,其思路是从一个已知的大知识数据库 中搜索并组合出相应的答案,这种搜索方式可以伴随一些预定好的规则,比如:{who} 想要糖果?回答:我想要{ pronoun }。 这个{ pronoun }可以从数据库找出相应的代词填入。而这种回答的规则可以用一种通用的XML文件来描述,我们称它为AIML2.0。
另外还需要拥有初级的逻辑推理能力,比如IBM Watson ,而对于这类而言,我们除了需要制定相应的逻辑规则库以外,还需要事实库。在Python中我们可以选用pyke框架来管理相应的事实库与逻辑规则库。
以上无论是逻辑推理回答还是一般回答都可以称作检索式的或者规则式的方法。除此之外还有哪些方法可以给出答案呢?英特在调查中发现目前学界在RNN(LSTM)上的突破让模型拥有了初级的‘学习’能力:基于神经网络序列的生成式对话模型。
生成式对话模型算法的概念就是让模型先看一些对话集,然后问它一句话,模型会通过从对话集学习的一些规律给你一个回答。简单来说根据你的上一句话和学习到的所有对话集规律生成一个个单词,这些单词如果意义是连贯的那就是一句话!而这正好契合了对话模型。
听上去很美好,而且一些大公司已做了很多工作,比如图3-2所示的Google对话集:

图3-2 Google 对话集示例
Google的这个结果建立在训练了3000万条对话的基础上,取其中的300万条对话来做验证集,并且去掉了专业名词、数字和URL等。达到这种数据量级后,能够对某一垂直领域类的问题做自由度较高的机器回复。
Google所用的生成式对话模型有哪些特点呢?下面来看看基于检索式模型和生成模型之间的区别,是不是能找到一些特点。
基于检索式模型(基于AIML2.0)使用了预定义回复库和一种条件触发式方法来根据输入和语境做出合适的回复。这种触发式方法一般基于规则的表达式匹配,当然你也可以用机器学习分类器来处理这类触发。检索式模型的特点是它不会产生新文本,只是从固定集合中挑选一种回复,套用农夫山泉广告语:“我们不生产文本我们只是集合的搬运工”。
生成式对话模型不依赖于预定义回复库,从零开始生成新回复。生成式对话模型一般基于机器翻译中的Seq2Seq技术,但应用场景有较大差别;机器翻译的目标是:把一个输入“翻译”成一个输出“回复”。输入(翻译)再输出(回复)就是编码器(encoder)经信息编码后再经解码器(decoder)解码的过程,而在对话中输入人说的话再输出机器的回复(如图3-3所示)。
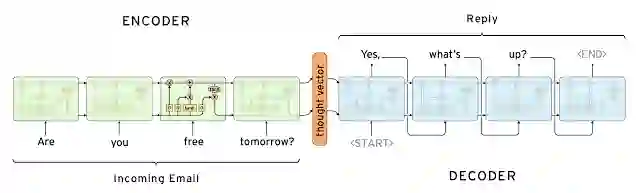
图3-3 Seq2Seq结构
编码器(encoder)是对于人的提问或对话的编码,可以看作是机器对问题的一种理解,而解码器(decoder)是机器对问题的一种回复。
是不是生成式对话模型就远比检索式要好呢?可以说目前为止,还只是各司其职,各自有不同的应用场景:
(1)检索式模型由于采用人工制作的回复库,基于检索式方法不会有语法错误,当然我们使用搜索引擎作为回复库,也很少有语法错误。然而使用回复库不能处理没出现过的情况,因为它们没有合适的预定义回复。同样,这些模型不能重新利用提上下文中的实体信息,如先前对话中提到过的名字。综上,检索式模型可以用在需要正确回答问题的场合,对答案的语法和准确性要求比较高。
(2)生成式对话模型从原理上讲更“聪明“些。它们可以重新提及输入中的实体并带给你一种正和你对话的感觉。然而,这类模型很可能会犯语法错误(特别是输入一个长句时),而且通常要求大量的训练数据。综上,生成式对话模型可以用在要求不那么精确的对话中。比如游戏的NPC交谈,比如一般的生活类对话场景。
虽然生成式对话模型有一些缺点,但毕竟是一个很好的方向,英特选择使用TensorFlow来实现这个结构。
前文提到,生成式对话模型是基于生成式机器翻译模型,而机器翻译模型用的就是Seq2Seq(Sequece2Sequence)结构 。我们先来理解下Seq2Seq结构:Seq2Seq由编码器和解码器组成,输入的单词以序列化的方式传入编码器,最终得到表示一句话的上下文特征向量;解码器接收特征向量以及每次的输出单词,做序列化的解码,输入和输出以终止。
对于编码器来说,为了进一步提高生成的准确性,其输入部分需要更多的句子特征,除一般的word2vec表示外,我们还可以引入单词的词性、句子成分、单词的重要性(TF-IDF)作为额外的特征。
下面我们看一个编解码器的例子(也是Seq2Seq的核心构件)。
编码器代码如下。
# Encoder
encoder_cell = rnn_util.MultiEmbeddingWrapper(
cell,
embedding_classes=num_encoder_symbols,
embedding_size=encoder_embedding_size
)
encoder_outputs, encoder_state = rnn.rnn(
encoder_cell, encoder_inputs, dtype=dtype)
解码器代码如下。
# Decoder.
output_size = None
if output_projection is None:
cell = rnn_cell.OutputProjectionWrapper(cell, num_decoder_symbols)
output_size = num_decoder_symbols
……
def decoder(feed_previous_bool):
reuse = None if feed_previous_bool else True
with variable_scope.variable_scope(variable_scope.get_variable_scope(), reuse=reuse) as scope:
outputs, state = embedding_attention_decoder(
decoder_inputs,
encoder_state,
attention_states,
cell,
num_decoder_symbols,
embedding_size=decoder_embedding_size,
num_heads=num_heads,
output_size=output_size,
output_projection=output_projection,
feed_previous=feed_previous_bool,
update_embedding_for_previous=False,
initial_state_attention=initial_state_attention)
state_list = [state]
if nest.is_sequence(state):
state_list = nest.flatten(state)
return outputs + state_list
outputs_and_state = control_flow_ops.cond(feed_previous, lambda: decoder(True), lambda: decoder(False))
这里解释下解码器中的Attention层,Attention层的思想也是来自于翻译领域,即前文出现的单词也可能出现在后面的回答中,比如说人名、地名等信息。Attention层是在编码器隐藏层和解码器之间的网络结构,在某一时刻t时,接收解码器的隐藏层信息,生成当前时刻的加载到编码器隐藏层上的权重。
英特训练了10万条有关星巴克的微博信息,最终取得了不错的结果,我们先来看看中间的输出过程(如图3-4所示)。

图3-4 经过5 epoch后的训练结果
图3-4是英特用和星巴克有关的微博数据训练了5 epoch后得到的结果。可以看出,在5 epoch时,模型还无法说出一个完整的句子,甚至都无法表达通顺的短语,但是模型在不停的学习中回答越来越准确,下面的图3-5是训练了50 epoch后的最终结果。

图3-5 经过50 epoch后的训练结果
英特对最终结果分析后发现仍然会存在一些问题:第一就是前文提到的会有一些语法错误;第二需要大量的训练数据。
第一个问题主要受限于现在的模型原理。目前暂时没有哪个模型或者衍生的模型能解决好。
再看第二点,如何获取大量的训练数据。凭借英特的经验,对于普适性的对话模型可以从两类途径获取:一是从电视剧中获取相关数据;二是从微博、QQ聊天记录中获取相关数据。
对于一些专业性比较强的领域,就要求在本专业领域收集数据了,如上文提到的Google将自己IT 服务部门的所有对话拿来训练。在任何稍微开放领域的应用上,比如像回复一封工作邮件,就超出了该模型现有的能力范围。但退一步来讲,仍旧可以利用模型建议和改正回复来“辅助”人类工作者;然后在这个过程中让模型学习人类真实的回复语句,不断更新出一个符合人类习惯的对话模型。
判断机器人说话的准确性
英特团队在做完以上工作后,发现机器说的话有些已经有成形的答案,还有些不通顺、不成句子。这涉及另外一个问题,我们如何评价模型呢?如何判断哪些模型的哪些调整有助于提高输出句子的通顺性或准确度?
英特浏览了相关的论文,发现针对这类问题有很多评价办法,最终英特选择了最早出现在翻译界的方法:BLEU评测方法。
BLEU(Bilingual Evaluation understudy)方法由IBM提出,这种方法认为如果机器翻译的译文越接近人工翻译结果,那么它的翻译质量越高。所以,评测关键就在于如何定义系统译文与参考译文之间的相似度。BLEU采用的方式是比较并统计共现的n-gram个数,即统计同时出现在系统译文和参考译文中的n-gram的个数,最后把匹配到的n-gram的数目除以系统译文的单词数目,得到评测结果。
最开始提出的BLEU法虽然简单易行,但是它没有考虑到翻译的召回率。后来对BLEU做了修正,即首先计算出一个n-gram在一个句子中最大可能出现的次数MaxRefCount(n-gram),然后再和候选译文中的这个n-gram出现的次数比较,取它们之间最小值作为该n-gram的最终匹配个数。
智能对话的总结和思考
前面的工作可以总结为简单流程图(如图3-6所示)。

图3-6 对话简单流程
该流程一共包括4个主要模块。正如本章开始时所分析的那样,最优先解决的是问答,与其说这是一个智能对话机器人不如说这其实就是信息检索和总结的过程,因为聊天毕竟不是一个人的事,它必然是一个交互的过程(程序与人的交互过程)。而解决交互过程最好的方法就是应用强化学习(reinforcement learning),我们会在后面的章节中对该算法做具体的实验说明,这里仅简单描述:强化学习是用来解决程序与环境的交互问题的,即让程序对当前所处的环境做出必要的反应。
假定我们站在机器的角度来考虑问题,所处的环境为聊天室,看到的全是我与对方的聊天记录,我们要做的就是在适当的时刻给出合适的回复,那么这里就需要做三件事:
(1)看懂聊天记录(state);
(2)量化回复所用的语言(action);
(3)针对对话的过程打分(value function)。
第一件事就是文本特征提取过程(CNN),此处不再赘述。
第二件事有两种处理思路:
(1)把句子作为动作分解成两个过程,输出量化后的动作,再根据量化值生成一句话;
(2)把字作为一个动作,允许连续输出多个动作。
第三件事最为重要,一个好的评价函数是决定强化学习效率的关键,这里也有两种思路可以考虑:
(1)以对抗的方式训练一个句子的打分器,但这需要大量的标注的对话语料;
(2)最新的评价一个对话质量的观点是根据对方是否愿意和你聊天来判断,即根据对话的回合数直接对对话打分。
这样就把对话过程建模成一个强化学习的过程了。
综上,对话问题虽然得到了一定的解决,但并没有在所有领域都取得较好的效果,还需要不断优化,目前最好作为辅助功能。另一方面,如果要回答前面提到的常识性的问题,就需要“规则”和“常识”来处理。“规则常识”其实是对实体的一种映射,这种映射需要不停地存入新的常识并更新,所以常识性的问题少不了知识图谱 的支持,基于检索式的方法结合知识图谱的使用,将使问题回答的准确性有一个质的提高。
这样就引来了如下思考,如果前面的检索方式并不能够解决多轮对话问题,假设出现这样的一个问题“他是做什么的呢?”,那么我们光看这句话明显不知道“他”指的是谁?此时就需要使用指代消解来解决。笔者所在的团队在这方面已经有了初步的效果,目前已经能实现5轮 左右的对话。这里简单例举几种指代的处理方式。
(1)原因询问。
A:她昨天又没来。B:为什么?
“为什么”就指前一句话的内容,这时候B问的是为什么她昨天又没来。
(2)同义替换。
A:今天天气怎么样。B:今天天气不错。A:明天呢?
明天呢?替换成明天天气怎么样?这里将明天和今天替换,这是同义词性的替换。
(3)结构补充。
A:周杰伦是干啥的?B:唱歌的。A:出过哪些专辑?
这里“出过哪些专辑?”替换成“周杰伦出过哪些专辑?”这是结构缺失,要去前文找相似结构位置的主题词并补充。
以上三种情况已经可以涵盖多数场景,读者可以根据这些思路解决更多的指代问题,为多轮对话贡献自己的力量。
对话的部分讲到这里可以告一段落了,人类对于智能机器人的渴求已越来越迫切,而智能的重要表征就在于对话能力,对话能反映出智能的程度,这方面的研究也只是刚刚开了个头,还有很多未知的领域需要我们去探索。笔者非常庆幸我们能生活在这个时代,有信心在有生之年看到真正的智能产生。
《深度学习算法实践》订购链接(点击阅读原文订购):https://item.jd.com/12224062.html

赠书啦!!!
留言告诉头条宝宝你想获得这本书的理由,点赞前5名就可获得本书。
开奖截止时间9月15日(本周五)中午12点!
9月14日(本周四晚8:00),我们邀请到本书作者吴岸城(菱歌科技首席算法科学家),他将带来直播分享「深度学习中基础模型性能的思考和优化」。扫描下方二维码立即报名