考虑到 Transformer 对于机器学习最近一段时间的影响,这样一个研究就显得异常引人注目了。
Transformer 有着巨大的内存和算力需求,因为它构造了一个注意力矩阵,需求与输入呈平方关系。谷歌大脑 Krzysztof Choromanski 等人最近提出的 Performer 模型因为随机正正交特性为注意力矩阵构建了一个无偏的估计量,可以获得线性增长的资源需求量。
这一方法超越了注意力机制,甚至可以说为下一代深度学习架构打开了思路
。
![]()
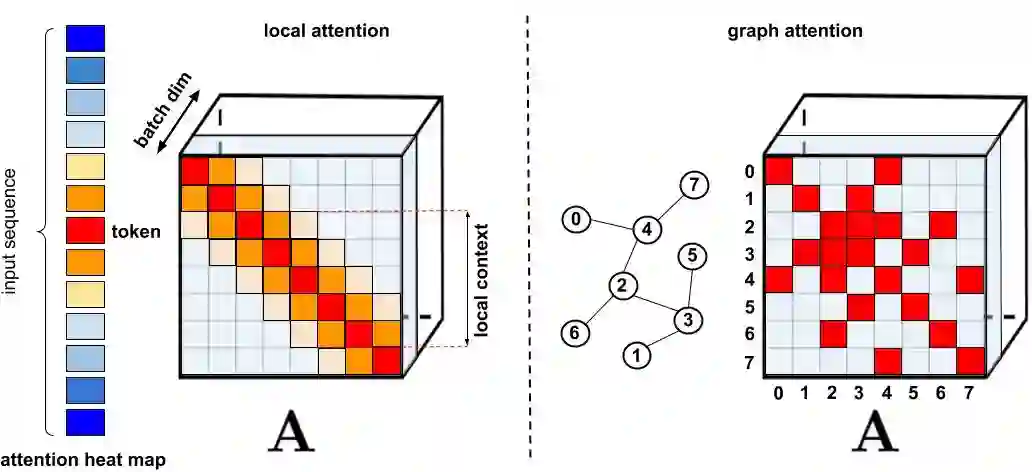
自面世以来,Transformer 模型已经在多个领域取得了 SOTA 结果,包括自然语言处理、图像处理甚至是音乐处理。众所周知,Transformer 架构的核心是注意力模块,它计算输入序列中所有位置对的相似度得分。然而,随着输入序列长度的增加,注意力机制本身的问题也越来越突出,因为它需要二次方的计算时间来产生所有的相似度得分,用来存储这些得分的内存大小也是如此。
针对那些需要长距离注意力的应用,部分研究者已经提出了一些速度快、空间利用率高的方法,其中比较普遍的方法是稀疏注意力。
![]()
然而,稀疏注意力方法也有一些局限。首先,它们需要高效的稀疏矩阵乘法运算,但这并不是所有加速器都能做到的;其次,它们通常不能为自己的表示能力提供严格的理论保证;再者,它们主要针对 Transformer 模型和生成预训练进行优化;最后,它们通常会堆更多的注意力层来补偿稀疏表示,这使其很难与其他预训练好的模型一起使用,需要重新训练,消耗大量能源。
此外,稀疏注意力机制通常不足以解决常规注意力方法应用时所面临的所有问题,如指针网络。还有一些运算是无法稀疏化的,比如常用的 softmax 运算。
为了解决这些问题,来自谷歌、剑桥大学、DeepMind、阿兰 · 图灵研究所的研究者提出了一种新的 Transformer 架构——Performer。它的
注意力机制能够线性扩展,因此能够在处理长序列的同时缩短训练时间
。这点在 ImageNet64 等图像数据集和 PG-19 文本数据集等序列的处理过程中都非常有用。
![]()
论文链接:https://arxiv.org/pdf/2009.14794.pdf
Performer 使用一个高效的(线性)广义注意力框架(generalized attention framework),允许基于不同相似性度量(核)的一类广泛的注意力机制。该框架通过谷歌的新算法 FAVOR+( Fast Attention Via Positive Orthogonal Random Features)来实现,后者能够提供注意力机制的可扩展低方差、无偏估计,这可以通过随机特征图分解(常规 softmax-attention)来表达。该方法在保持线性空间和时间复杂度的同时准确率也很有保证,也可以应用到独立的 softmax 运算。此外,该方法还可以和可逆层等其他技术进行互操作。
研究者表示,他们相信该研究为注意力、Transformer 架构和核方法提供了一种新的思维方式。
代码地址:https://github.com/google-research/google-research/tree/master/performer
论文公布之后,Youtube 知名深度学习频道 Yannic Kilcher 对该文章进行了解读。
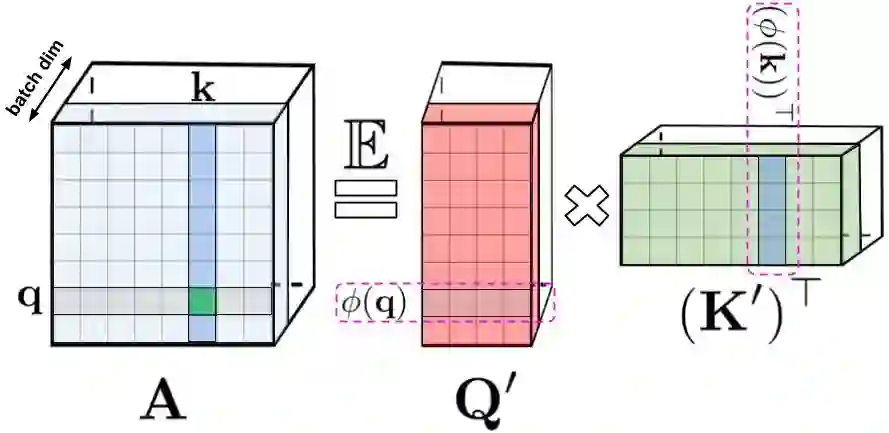
在以往的注意力机制中,分别对应矩阵行与列的 query 和 key 输入相乘,通过 softmax 计算形成一个注意力矩阵,以存储相似度系数。值得注意的是,这种方法不能将 query-key 生成结果传递给非线性 softmax 计算之后再将其分解为原始的 query 和 key。然而,将注意力矩阵分解为原始 query 和 key 的随机非线性函数的乘积是可以的,即所谓的随机特征(random feature),这样就可以更加高效地对相似度信息进行编码。
![]()
标准注意力矩阵包括每一对 entry 的相似度系数,由 query 和 key 上的 softmax 计算组成,表示为 q 和 k。
常规的 softmax 注意力可以看作是由指数函数和高斯投影定义的非线性函数的一个特例。在这里我们也可以反向推理,首先实现一些更广义的非线性函数,隐式定义 query-key 结果中其他类型的相似性度量或核函数。研究者基于早期的核方法(kernel method),将其定义为广义注意力(generalized attention)。尽管对于大多核函数来说,闭式解并不存在,但这一机制仍然可以应用,因为它并不依赖于闭式解。
该研究首次证明了,任意注意力矩阵都可以通过随机特征在下游 Transformer 应用中实现有效地近似。实现这一点的的新机制是使用正随机特征,即原始 query 和 key 的正直非线性函数,这对于避免训练过程中的不稳定性至关重要,并实现了对常规 softmax 注意力的更准确近似。
新算法 FAVOR+:通过矩阵相关性实现快速注意力
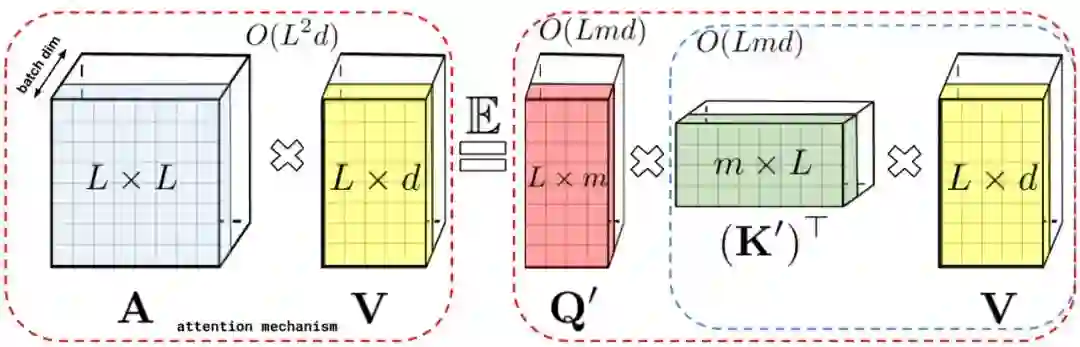
上文描述的分解允许我们以线性而非二次内存复杂度的方式存储隐式注意力矩阵。我们还可以通过分解获得一个线性时间注意力机制。虽然在分解注意力矩阵之后,原始注意力机制与具有值输入的存储注意力矩阵相乘以获得最终结果,我们可以重新排列矩阵乘法以近似常规注意力机制的结果,并且不需要显式地构建二次方大小的注意力矩阵。最终生成了新算法 FAVOR+。
![]()
左:标准注意力模块计算,其中通过执行带有矩阵 A 和值张量 V 的矩阵乘法来计算最终的预期结果;右:通过解耦低秩分解 A 中使用的矩阵 Q′和 K′以及按照虚线框中指示的顺序执行矩阵乘法,研究者获得了一个线性注意力矩阵,同时不用显式地构建 A 或其近似。
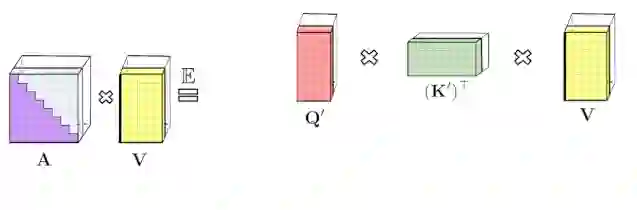
上述分析与双向注意力(即非因果注意力)相关,其中没有 past 和 future 的概念。对于输入序列中没有注意前后 token 的单向(即因果)注意力而言,研究者稍微修改方法以使用前缀和计算(prefix-sum computation),它们只存储矩阵计算的运行总数,而不存储显式的下三角常规注意力矩阵。
![]()
左:标准单向注意力需要 mask 注意力矩阵以获得其下三角部分;右:LHS 上的无偏近似可以通过前缀和获得,其中用于 key 和值向量的随机特征图的外积(outer-product)前缀和实现动态构建,并通过 query 随机特征向量进行左乘计算,以在最终矩阵中获得新行(new row)。
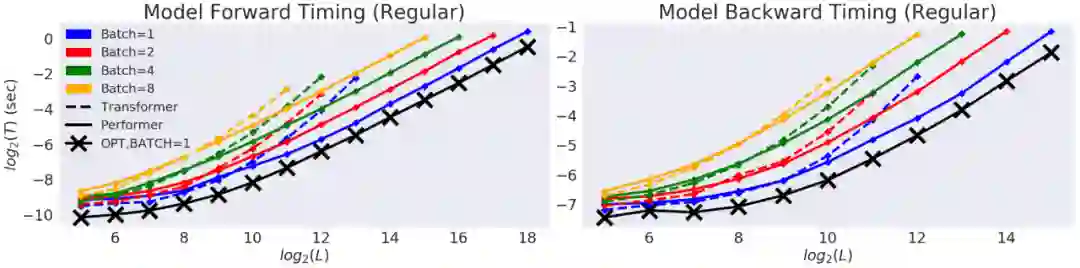
研究者首先对 Performer 的空间和时间复杂度进行基准测试,结果表明,注意力的加速比和内存减少在实证的角度上近乎最优,也就是说,这非常接近在模型中根本不使用注意力机制的情况。
![]()
在以时间(T)和长度(L)为度量的双对数坐标轴中,常规 Transformer 模型的双向 timing。
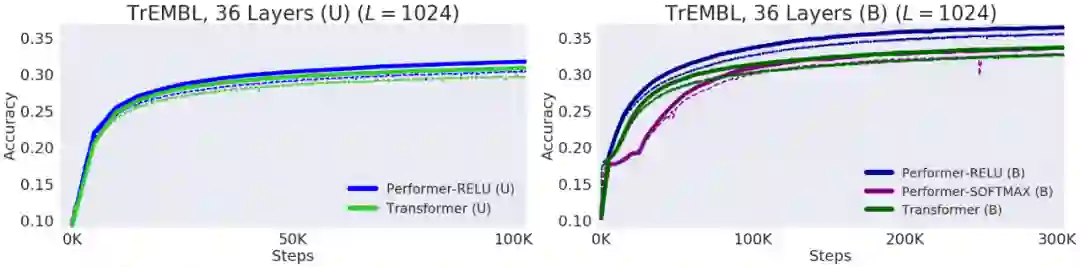
研究者进一步证明,使用无偏 softmax 近似,该 Performer 模型在稍微进行微调之后可以向后兼容预训练 Transformer 模型,从而在提升推理速度的同时降低能耗,并且不需要从头训练预先存在的模型。
![]()
在 One Billion Word Benchmark (LM1B) 数据集上,研究者将原始预训练 Transformer 的权重迁移至 Performer 模型,使得初始非零准确度为 0.07(橙色虚线)。但在微调之后,Performer 的准确度在很少的梯度步数之后迅速恢复。
蛋白质具有复杂的 3D 结构,是生命必不可少的拥有特定功能的大分子。和单词一样,蛋白质可以被看做线性序列,每个字符代表一种氨基酸。将 Transformers 应用于大型未标记的蛋白质序列语料库,生成的模型可用于精确预测折叠功能大分子。正如该研究理论结果所预测的那样,Performer-ReLU 在蛋白质序列数据建模方面表现良好,而 Performer-Softmax 与 Transformer 性能相媲美。
![]()
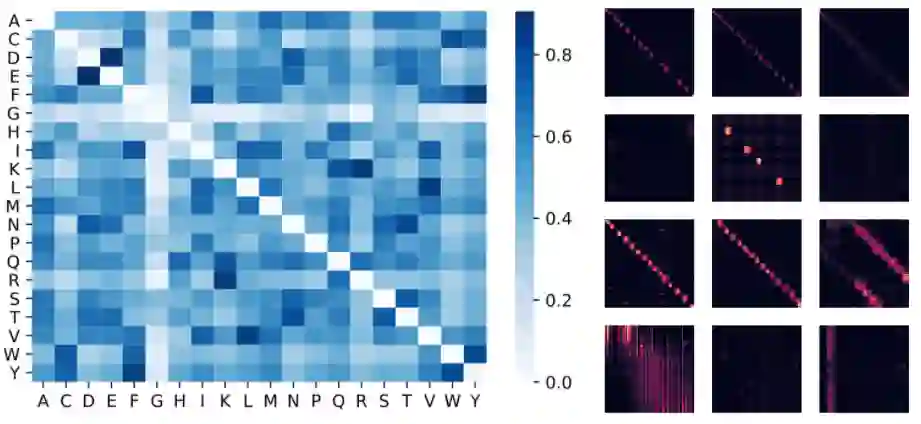
下面可视化一个蛋白质 Performer 模型,该模型使用基于 ReLU 的近似注意力机制进行训练。研究者发现,Performer 的密集注意力近似有可能捕捉到跨多个蛋白质序列的全局相互作用。作为概念的证明,研究者在串联蛋白长序列上训练模型,这使得常规的 Transformer 模型内存过载。但由于具有良好的空间利用效率,Performer 不会出现这一问题。
![]()
左:从注意力权重估计氨基酸相似性矩阵。该模型可以识别高度相似的氨基酸对,例如 (D,E) 和 (F,Y)。
![]()
Performer 和 Transformer 在长度为 8192 的蛋白质序列上的性能。
参考链接:http://ai.googleblog.com/2020/10/rethinking-attention-with-performers.html
Amazon SageMaker实战教程(视频回顾)
Amazon SageMaker 是一项完全托管的服务,可以帮助机器学习开发者和数据科学家快速构建、训练和部署模型。Amazon SageMaker 完全消除了机器学习过程中各个步骤的繁重工作,让开发高质量模型变得更加轻松。
10月15日-10月22日,机器之心联合AWS举办3次线上分享,全程回顾如下:
![]()
第一讲:Amazon SageMaker Studio详解
黄德滨(AWS资深解决方案架构师)主要介绍了Amazon SageMaker的相关组件,如studio、autopilot等,并通过在线演示展示这些核心组件对AI模型开发效率的提升。
视频回顾地址:https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715443e4b005221d8ea8e3
第二讲:使用Amazon SageMaker 构建一个情感分析「机器人」
刘俊逸(AWS应用科学家)
主要介绍了情感分析任务背景、使用Amazon SageMaker进行基于Bert的情感分析模型训练、利用AWS数字资产盘活解决方案进行基于容器的模型部署。
视频回顾地址:https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715d38e4b0e95a89c1713f
第三讲:DGL图神经网络及其在Amazon SageMaker上的实践
张建(AWS上海人工智能研究院资深数据科学家)主要介绍了图神经网络、DGL在图神经网络中的作用、图神经网络和DGL在欺诈检测中的应用和使用Amazon SageMaker部署和管理图神经网络模型的实时推断。
视频回顾地址:
https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715d6fe4b005221d8eac5d
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com