【泡泡图灵智库】SqueezeSeg:从3D LiDAR点云中实时分割路面物体的循环CRF卷积神经网络(ICRA)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud
作者:Bichen Wu, Alvin Wan, Xiangyu Yue and Kurt Keutzer
来源:ICRA 2018
编译:黄文超
审核:刘小亮
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——SqueezeSeg:从3D LiDAR点云中实时分割路面物体的循环CRF卷积神经网络
本文作者致力于解决3D LiDAR点云中的路面物体语义分割问题。特别是需要检测和分类感兴趣的物体如车,人和骑自行车或摩托车的人。作者将这个问题视为逐点的分类问题,基于CNN提出了一个端到端的框架SqueezeSeg:CNN接收经过变换的LiDAR点云输入,直接输出逐点的标记图,随后使用一个由CRF(条件随机场)实现的循环层进行精炼,最后使用传统的聚类方法获得实例级别的标记。CNN模型是在KITTI的LiDAR数据上训练的,逐点的分割标记从KITTI的3D包围框中获得。为了获得额外的训练数据,作者还在GTA-V中建立了一个LiDAR模拟器,来合成大量真实的训练数据。实验表面SqueezeSeg达到了很高的精度,同时运算速度快且稳定(每帧8.7 ± 0.5 ms),这对于自动驾驶的应用有很大帮助。此外,在合成数据上的训练还提高了在真实数据验证集上的精度。源代码和合成数据将会开源。
主要贡献
1、将CNN和CRF用于3D LiDAR数据,提出了实时路面物体分割网络SqueezeSeg。
2、实验验证其有效性、鲁棒性以及极快的计算速度。
算法流程
A. 点云变换
传统CNN模型是在图像上操作,可以表示为HxWx3的张量。但是3D LiDAR数据通常是非常稀疏和不规则的,直接体素化会导致大量的空体素,造成内存和计算资源的浪费。作者提出将LiDAR点云投影到一个球体上(见图2B),公式如式(1)所示。考虑Velodyne HDL-64E,转换后的张量为64x512x5,其中64代表线数,512代表90°的前视场分为了512份,5为特征数,包括:3个笛卡尔坐标xyz,1个强度测量值和距离r。这样的表达是稠密且规则分布的(图2C)。
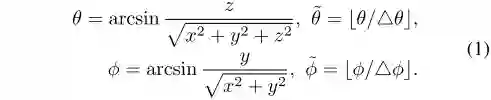

图2 激光雷达数据投影
B. 网络架构
网络架构如图3所示,依据SqueezeNet修改而来。SqueezeNet是一个轻量级的CNN,能够达到AlexNet的精度但是参数少50倍。网络的输入是64 × 512 × 5的张量,在max-pooling的降采样阶段,由于H远小于W,仅对W进行降采样。为了获得全分辨率的标记预测图,使用逆卷积模块来上采样特征图。由Softmax生成的概率图又经由循环CRF层进行精炼。

图3 SqueezeSeg网络结构
C. 条件随机场
在图像分割中,CNN产生的概率标记图通常具有模糊的边界,这是由降采样过程中低层次的细节丢失造成的。精确的逐点标记预测不仅需要高层次的语义也需要低层次的细节,后者对于标记分配的一致性很重要。例如,如果两个点在点云中相邻,同时又有相近的强度测量值,那么它们就很有可能具有相同的标记。条件随机场的能量函数最小化的平均场迭代算法和作为RNN的方法参考文献[9]和[11]。本文方法的实现见图5。

图5 CRF作为一个RNN层
[9] P. Kr¨ahenb¨uhl and V. Koltun, “Efficient inference in fully connected crfs with gaussian edge potentials,” in Advances in neural information processing systems, 2011, pp. 109–117.
[11] S. Zheng, S. Jayasumana, B. Romera-Paredes, V. Vineet, Z. Su, D. Du, C. Huang, and P. H. Torr, “Conditional random fields as recurrent neural networks,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 1529–1537.
D. 数据收集
初始数据来自KITTI数据集,提供图像,LiDAR数据和3D包围框,从3D包围框中可以提取逐点的类别标注。同时为了获得更多的数据,作者在GTA-V中建立了一个LiDAR仿真器,在游戏中的车上安装了一个虚拟的激光雷达。获得的数据如图6所示。为了使这个数据更加真实,作者分析了KITTI点云数据中的噪声分布,用这个分布去加强合成的数据。

图6 左:游戏场景;右:对应的LiDAR数据
主要结果
表1 SqueezeSeg的分割性能
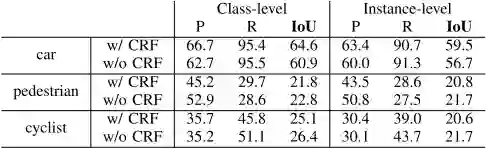
SqueezeSeg的分割准确度见表1.作者比较了两种变体,区别在于是否带有循环CRF层。尽管评估计算值非常具有挑战性,SqueezeSeg依然获得了很高的IoU分数,特别是车这一类别,分类级别和实例级别的召回率都超过90%。行人和骑自行车的人这两个类别的准确度较低,可能有如下两个方面的原因:数据集中这两个类别的数量较少;这两个类别的实例尺寸大小较小,细节信息更少,较难分割。
表2 SqueezeSeg的计算性能

表2是在TITAN X GPU上进行测试的SqueezeSeg性能。不使用CRF层的情况下仅需8.7ms来处理一帧LiDAR数据,结合CRF层后需要13.5ms。这比当前大部分激光雷达扫描仪的采样频率快得多。
表3 SqueezeSeg在合成数据上对车的分割性能
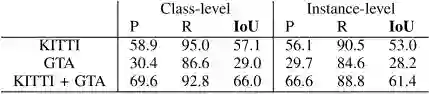
作者在GTA合成数据上训练,在KITTI数据集上测试,得到的结果见表3。由于合成数据暂时无法提供真实的行人和骑自行车的人的标记,该测试就仅针对车进行。同时合成数据不带有强度信息,所以为了作比较,作者在KITTI数据集上也训练了一个不使用强度信息的SqueezeSeg网络。仅在GTA数据上训练的网络测试结果很差,但是同时在KITTI数据集和GTA数据上训练的网络性能有很大的提升。

Abstract
In this paper, we address semantic segmentation of road-objects from 3D LiDAR point clouds. In particular, we wish to detect and categorize instances of interest, such as cars, pedestrians and cyclists. We formulate this problem as a point-wise classification problem, and propose an end-to-end pipeline called SqueezeSeg based on convolutional neural networks (CNN): the CNN takes a transformed LiDAR point cloud as input and directly outputs a point-wise label map, which is then refined by a conditional random field (CRF) implemented as a recurrent layer. Instance-level labels are then obtained by conventional clustering algorithms. Our CNN model is trained on LiDAR point clouds from the KITTI dataset, and our point-wise segmentation labels are derived from 3D bounding boxes from KITTI. To obtain extra training data, we built a LiDAR simulator into Grand Theft Auto V (GTA-V), a popular video game, to synthesize large amounts of realistic training data. Our experiments show that SqueezeSeg achieves high accuracy with astonishingly fast and stable runtime (8.7 ± 0.5 ms per frame), highly desirable for autonomous driving applications. Furthermore, additionally training on synthesized data boosts validation accuracy on real-world data. Our source code and synthesized data will be open-sourced.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




